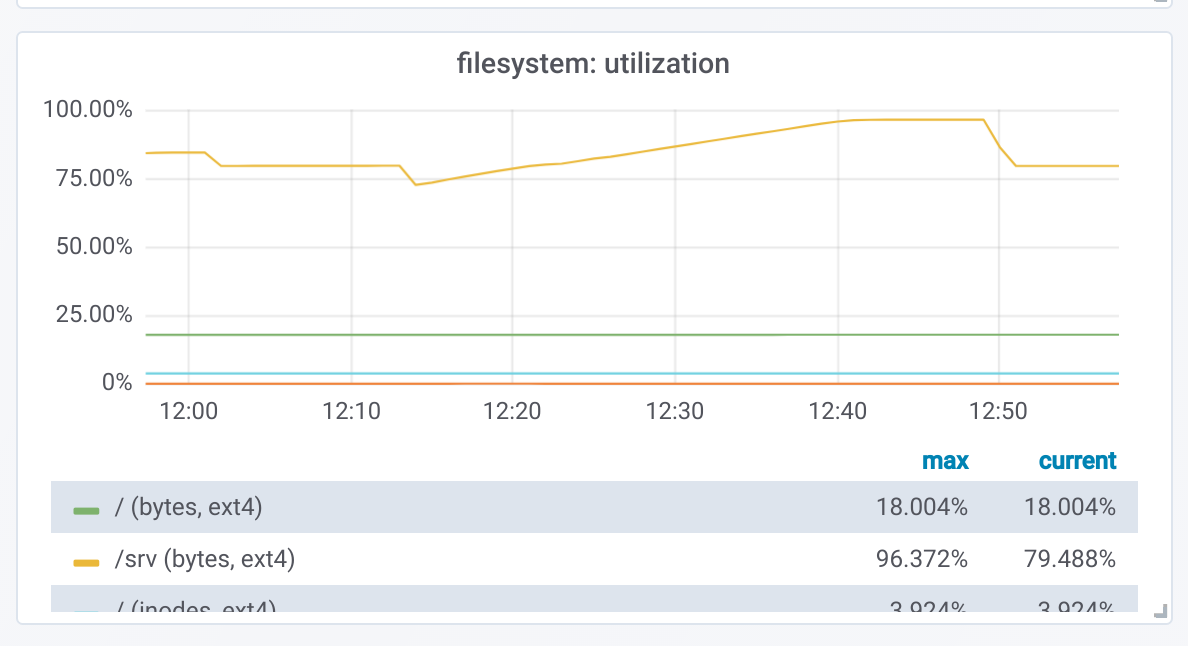
Elasticsearch logs warnings when trying to allocate and free disk space is below cluster.routing.allocation.disk.watermark.low. This creates much unnecessary logging traffic to logstash and is the sign of an unablanced cluster, which leads to much variance in query time. In that case, cluster should be rebalanced by lowering cluster.routing.allocation.disk.watermark.high to force moving shards or by manually moving shards around.
Having an early warning as an Icinga alert would enable us to react appropriately.