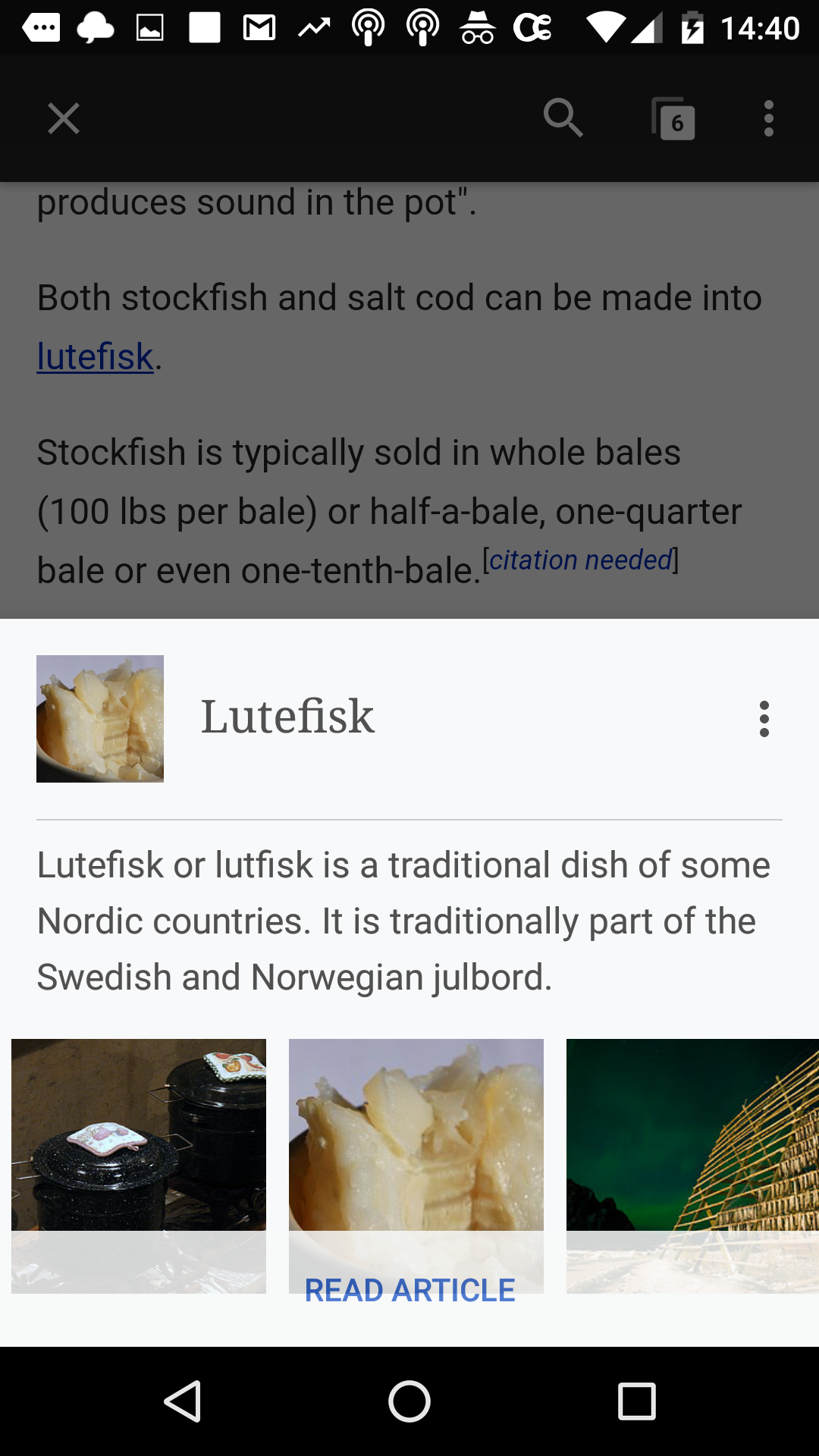
Previously we stripped out the phonetic pronunciation guide when presenting extracts in the app (recommendations, featured article, etc). This information, while helpful, often takes up a lot of horizontal space and generally doensn't fit the purspose of extracts (which is to help the user determine if an article is interest/relevant by providing a short informative introduction.
I am open to leaving as is, but we should make a deliberate choice, rather than change this due to regression.