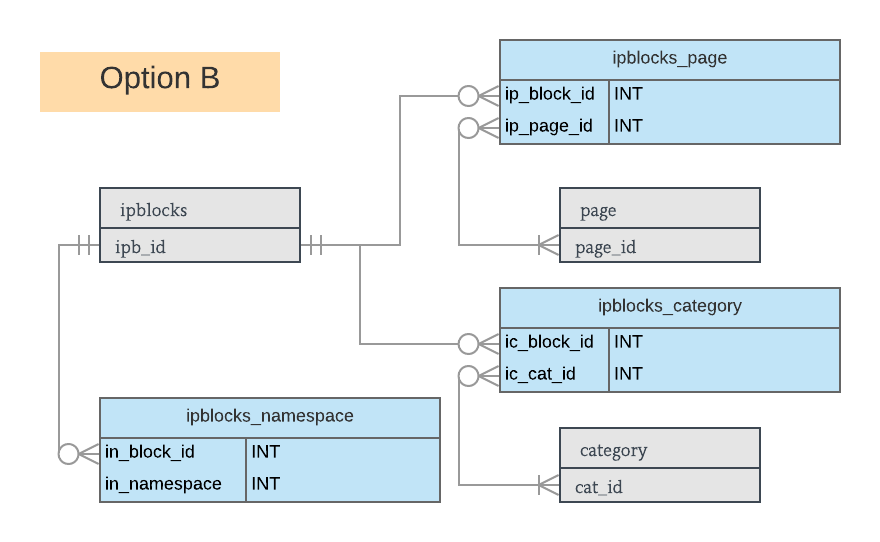
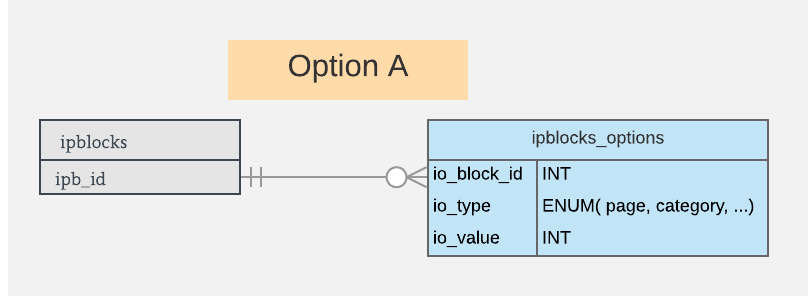
Data types here are illustrative, and open to change.
ipblocks_restrictions
| Field | Type |
|---|---|
| ir_ipb_id | int |
| ir_type | int |
| ir_value | int |
ir_type will be an int representing one of two values (page, namespace) and it will unlikely support anything else in a foreseeable future
ipblocks
| Field | Type |
|---|---|
| ipb_sitewide | tinyint |
A bool named sitewide will be added to ipblocks to indicate if the block is sitewide or partial.