- The existing Phetools OCR backend will pre-fetch other pages in the current book when you request a page from it
- This makes the OCR loading extremely fast, since the next page will be ready by the time you load that page
- The new backend should also preload the next page (or perhaps the next n pages) with the current settings to warm the cache. Though the new tool is certainly faster than the old one page-for-page, it's still not as fluid as Phetools once it warms up
Description
Description
Details
Details
| Subject | Repo | Branch | Lines +/- | |
|---|---|---|---|---|
| Prefetch the next page when running OCR | mediawiki/extensions/Wikisource | master | +14 -3 |
Related Objects
Related Objects
- Mentioned In
- T279102: Wikisource OCR: Investigate automatic OCR solution
T281502: Wikisource OCR: Determine bulk approach/proposal
T191286: [Suggestion] Pregenerate next/previous thumb when reading a pdf (or other multi-page file types) - Mentioned Here
- T230689: Preload the next page's image on proofreading view
T256959: Allow PDF's to be rendered at higher (or user specified DPI)
Event Timeline
Comment Actions
I believe this shouldn't be too hard. Maybe the real question is "how many pages?". I think we might just start with a page or two, and change it later on (in either direction) if we need to. As long as we don't hardcode the number of pages, this would also be trivial.
Comment Actions
Even one page will be helpful in the usual case (proofreading page by page). Remember that if you skip ahead out of the "cached buffer", the first time you OCR a new page, the cache will restart.
But because it's fairly common to skip the occasional page (e.g. blank pages. images, etc), a buffer of at least 3 pages would be better (allows to skip over a blank page and an image, which is common). Obviously, if there's system availability, more is better (phetools runs to the end of the book, for example), but because it's so much faster now, the penalty for a cache miss is much less painful than with phetools.
Comment Actions
If resource consumption is a concern, I think a single page will cover the wast majority of cases; and the exceptions have a fairly benign failure mode (it's an additional optimisation). But, yeah, "what Inductiveload said", essentially.
Comment Actions
Change 704534 had a related patch set uploaded (by Daimona Eaytoy; author: Daimona Eaytoy):
[mediawiki/extensions/Wikisource@master] Prefetch the next 2 pages when running OCR
Comment Actions
Copying here from gerrit:
The only thing that we could consider improving is that we currently use the same size of the current image. While this should work regardless, the app uses the URL to build the cache key, so no cache will be warmed up if the actual size is different. This should probably be fixed in wikimedia-ocr itself, though.
So my question is whether we have a quick way to retrieve the size that will be used for the next page (something fast, or it wouldn't worth the effort). If not, we could strip the size from the cache key in wm-ocr, which would be trivial. My only question is whether using a different size can have any effect on the OCR accuracy, and quantify this effect. If it's not tolerable, we can also probably just ignore the issue.
Comment Actions
Depending on how you get the image, the resolution to request might not matter as much as you might think anyway:
- Per T256959, for PDFs, they are rendered at a fixed DPI (150ppi by default) and then that image is upscaled - obviously this looks pretty dreadful
- For DjVus from the IA, they are usually compressed with an MRC compressor, so upscaling them doesn't really help anyway
Also, for the vast majority of files, every page is pretty much the exact same size anyway, so I imagine you would get hits more often than not (and if you find there's a variance of a few px between pages, round to the nearest 50px and use that?). Because the baseline speed is much faster than the Phetools OCR, a cache miss here and there is "OK" anyway.
Comment Actions
I wonder if it wouldn't be better for ProofreadPage to add the next page's info to each page. For example, fixing T230689 might result in embedding the next page's image URL in the current page, and so the Wikisource extension could pick it up from there. We've already got <link rel="prefech" /> for the next page's edit form; perhaps we should add the same for the actual image URL, e.g. <link rel="prefetch" as="image" href="…" title="prp-next-image" />. Or maybe preload, which is more immediate (doesn't wait for idle).
The OCR tool currently doesn't know anything about "pages" of a work, and it might be simpler to keep it that way (so e.g. it can in the future be used for OCRing arbitrary images on Commons).
Comment Actions
I've had an experiment with adding the new <link />: https://gerrit.wikimedia.org/r/c/mediawiki/extensions/ProofreadPage/+/704888 (it's attached to that other ticket).
Comment Actions
No, only when you click the button at the moment. But maybe it should be? It could fire off requests for the current and next page on page-load. Although, that wouldn't be necessary for a great number of pages… maybe it could do it only if there's no text in the editbox?
Comment Actions
I think this would be amazing!
The OCR tool currently doesn't know anything about "pages" of a work, and it might be simpler to keep it that way (so e.g. it can in the future be used for OCRing arbitrary images on Commons).
Absolutely, I also think it's not necessary for the OCR tool to know anything about on-wiki stuff.
I'd stick to onClick for now. My impression is that the SNR would be too high otherwise.
Comment Actions
Change 704534 merged by jenkins-bot:
[mediawiki/extensions/Wikisource@master] Prefetch the next page when running OCR
Comment Actions
@Samwilson Thanks for your help figuring a viable way to test this feature.
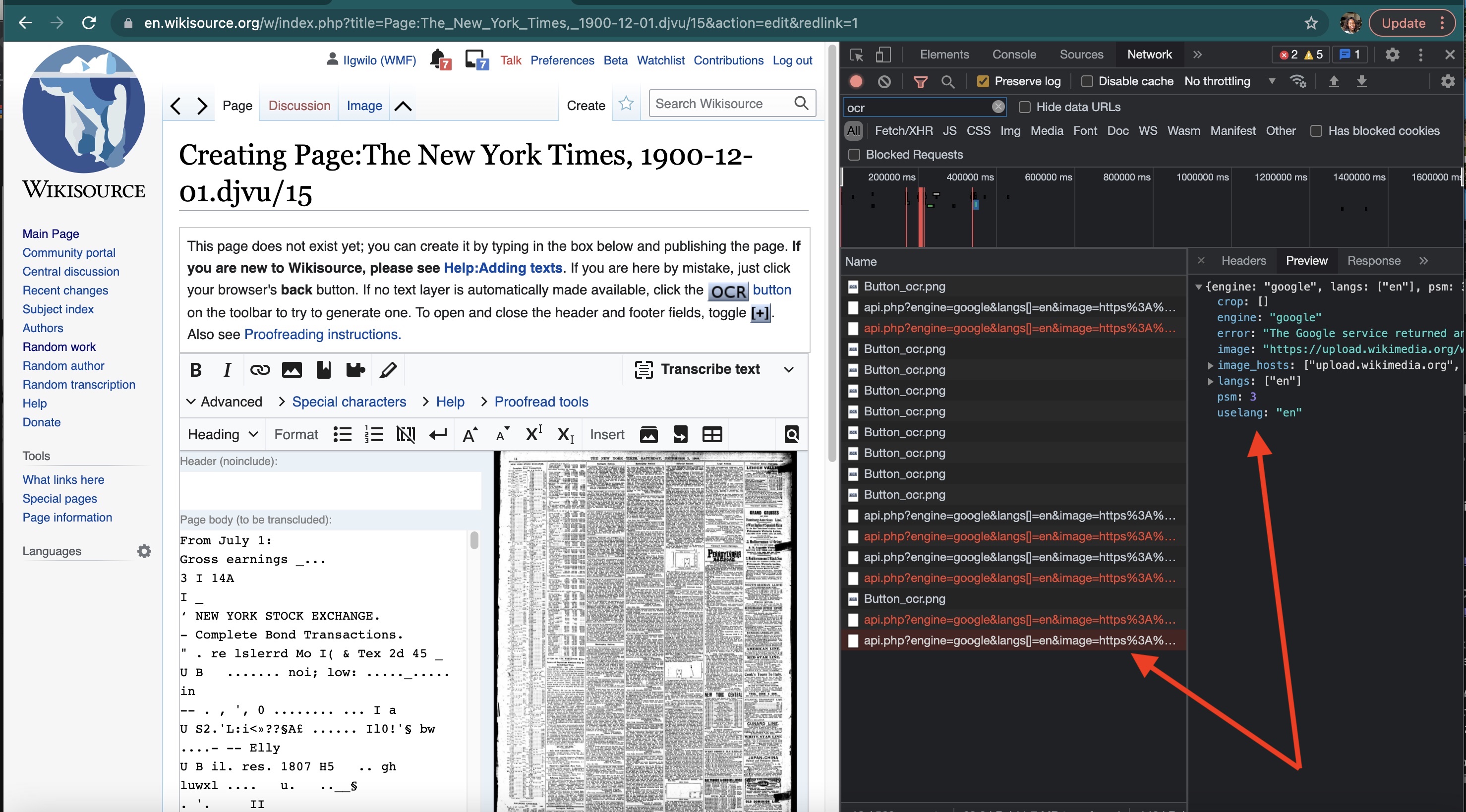
Verification steps:
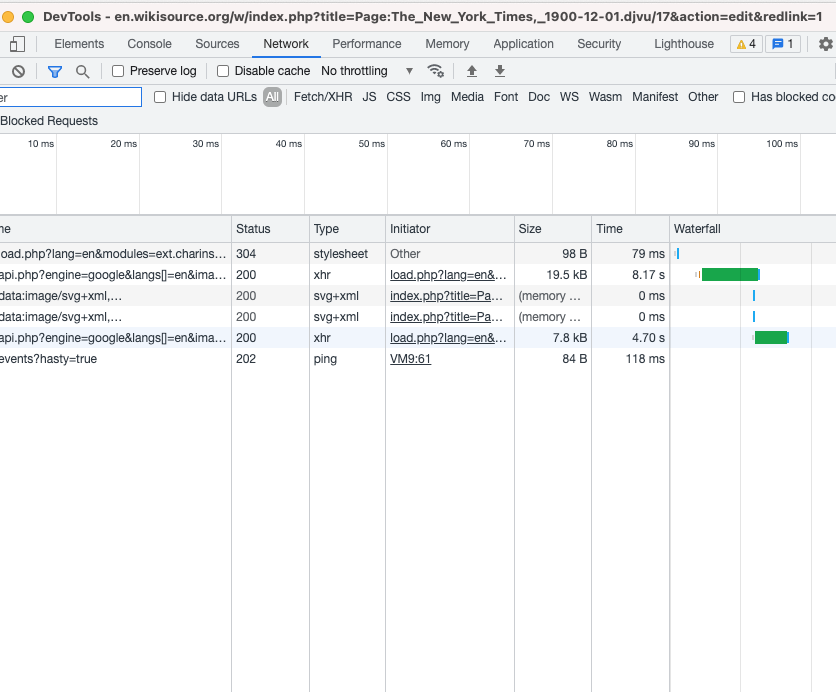
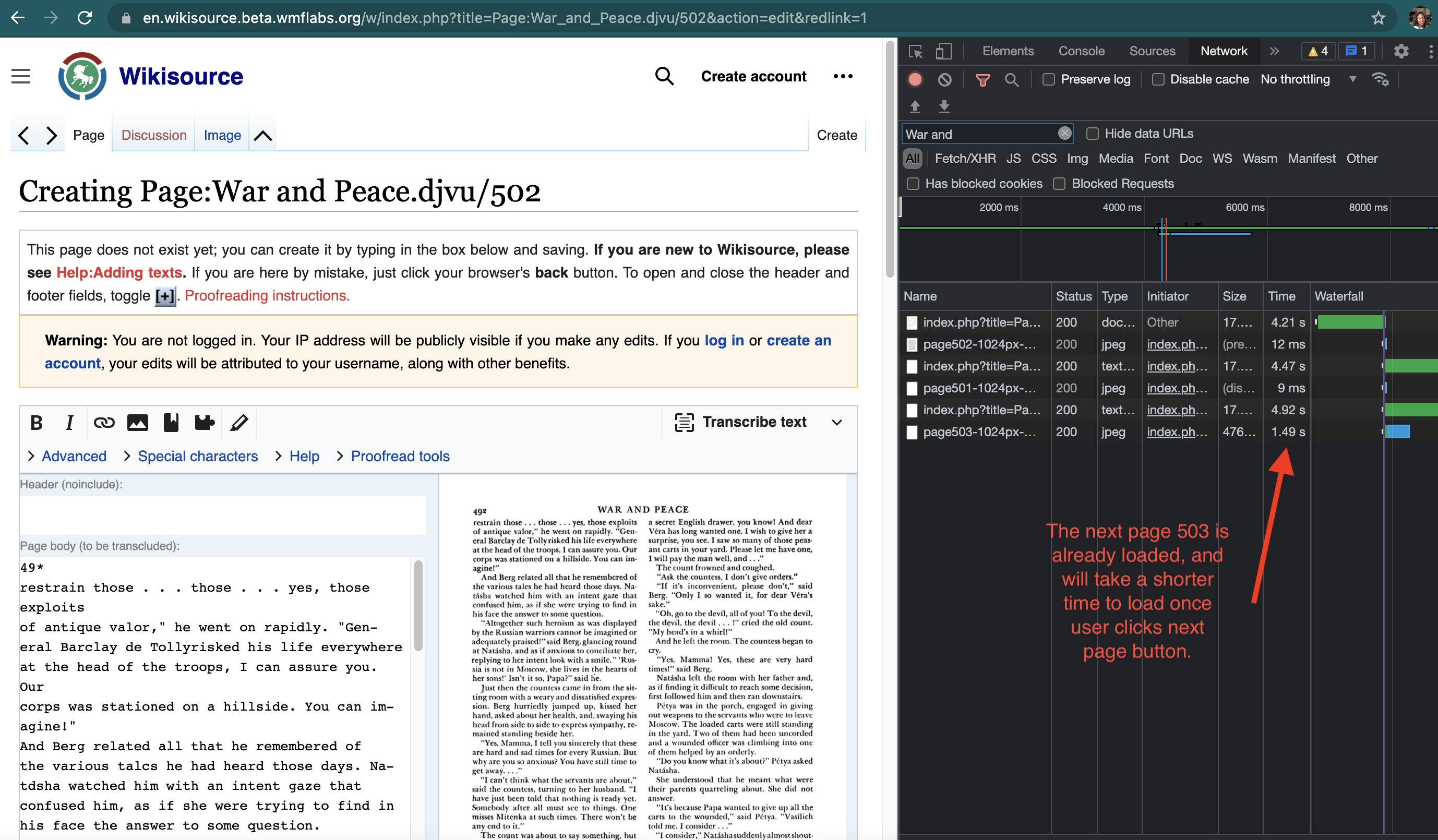
On a browser open developer tool and load the network tab
Load the page link e.g. https://en.wikisource.org/w/index.php?title=Page:The_New_York_Times,_1900-12-01.djvu/17&action=edit&redlink=1
Click next page arrow.
On the developer tools the next page is already loaded. Filter by book title to see network logs. See screenshot below
Comment Actions
@Samwilson FYI, we observed the following, It looks like a network issue. After a while, I test it again and it was find. I tested both translation engines.
URL: https://en.wikisource.org/w/index.php?title=Page:The_New_York_Times,_1900-12-01.djvu/17&action=edit&redlink=1
Error: The Google service returned an error: We can not access the URL currently. Please download the content and pass it in.
Image: https://upload.wikimedia.org/wikipedia/commons/thumb/7/79/The_New_York_Times%2C_1900-12-01.djvu/page16-2000px-The_New_York_Times%2C_1900-12-01.djvu.jpg
Comment Actions
Google returns the "We can not access the URL currently" error when the image takes too long to render. Usually it works on a 2nd try. In combination with the prefetching of the next pages' images, this should happen less often than it used to, but is still possible. I guess the answer could be to add a system of retrying when we get this error, but I'm not sure it's common enough to make it worthwhile.