I noticed warnings for thanos-be hosts hovering at around 94%, it is time to decide and tweak Thanos retention. At the moment we have the following:
aggregation: retention time raw: 54w 5m: 270w 1h: 270w
Pending actions:
- Analyze the data from thanos tools bucket inspect to get size breakdown (per instance, per aggregation, etc)
- Come to a consensus on what to drop for now. An easy candidate is replicas (a, b) since most of the time we have both prometheus replicas up and running.
- After some analysis as of 2024-01-23 the cleanable replicated blocks for our biggest instance ops (older than 3 months) are as follows: (note that for 0s we already cleaned up in the past, whereas 5m and 1h haven't been cleaned up beside the regular retention outlined above)
| resolution | GBs |
|---|---|
| 0s | 1533 |
| 5m0s | 20856 |
| 1h0m0s | 2483 |
- Do capacity planning based on the retention we'd like
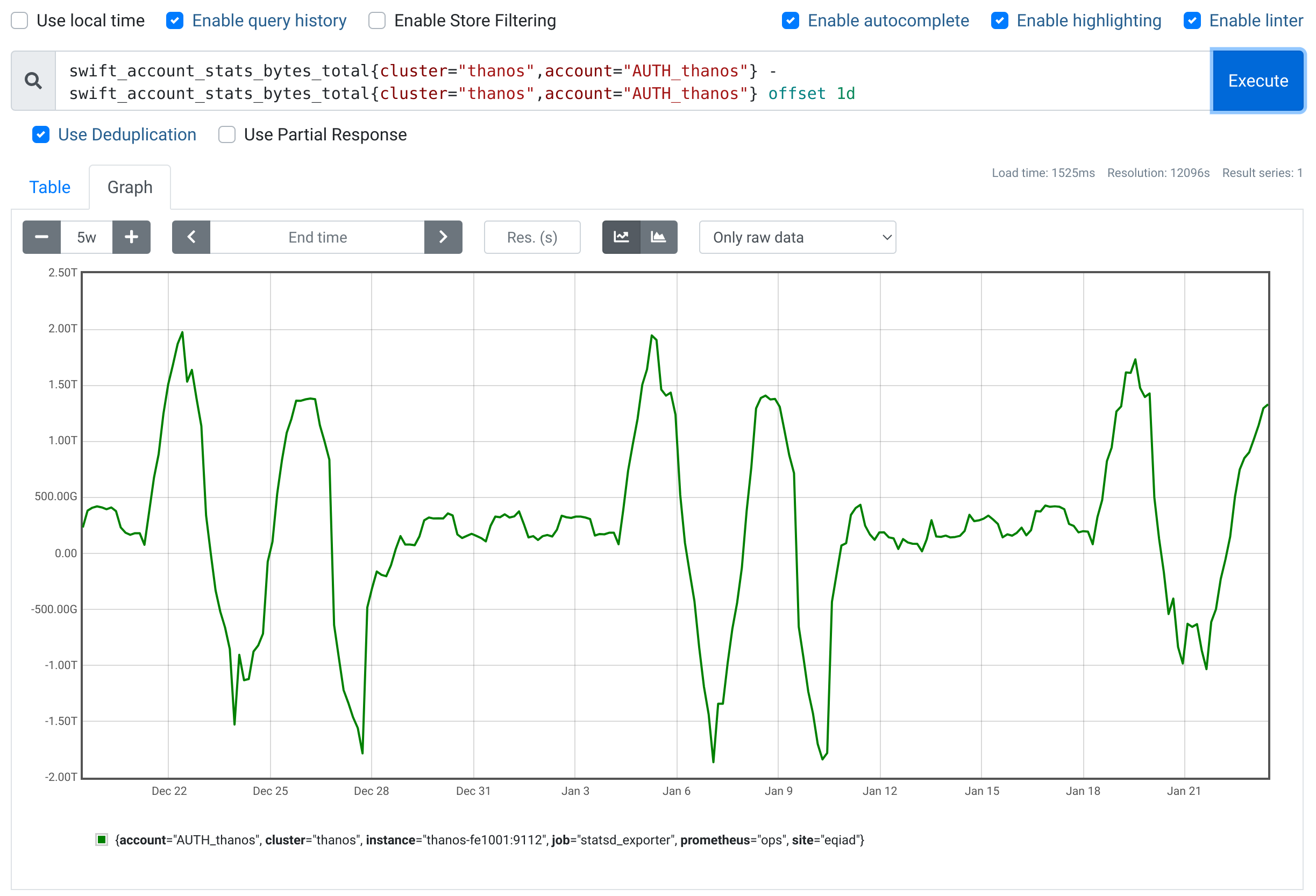
- As it stands we're averaging 400GB/day of new data, plus temporary spikes of ~2TB twice a week when the compactor runs and space gets freed afterwards:
Block cleanup strategies
In the short term there are "low hanging" fruits in terms of replicated data we can quickly delete and shed some storage space load/pressure.
Currently in eqiad and codfw we have two identical Prometheus hosts in each site, configured the same and doing the same work. They upload their data blocks periodically to Thanos for long term storage, each block uploaded is labeled with prometheus=<instance> and site=<site> and replica=[ab] so we can identify the block source later when reading data and de-duplicating it as needed (thanos-query does this job). Note that replica label is intentionally abstracted from the hostname that uploaded the data, and can be (as of Jan 2024) either a or b.
So far we have kept replicated data blocks until Thanos' retention time, this is helpful because e.g. on data missing from replica=a (e.g. during maint/reboot/etc) it is possible to read the missing data from replica=b and vice-versa.
While this strategy works well, it also means we end up with a lot of basically-duplicated data for the most part. Thanos supports the so-called vertical compaction to de-duplicate blocks and merge into one, however that is a more invasive change and comes with its own caveats/risks. For the purposes/scope of this task the focus will be on deleting duplicated blocks.
The strategy implemented so far is the following:
- Select all blocks older than three months, with site=codfw or site=eqiad and resolution 0s (i.e. raw data)
- Group blocks by their prometheus instance and start/end time
- From each group, pick the block with fewer samples (i.e. less data) and mark it for deletion
Cleanup size
The following table shows space reclaimable (> 50GB) for duplicated blocks older than three months, grouped by resolution first and ordered by size.
| resolution | size in GB | labels |
|---|---|---|
| 0s | 51.0 | prometheus=analytics,site=eqiad |
| 0s | 52.7 | prometheus=k8s-staging,site=codfw |
| 0s | 53.6 | prometheus=k8s-mlstaging,site=codfw |
| 0s | 65.7 | prometheus=k8s-staging,site=eqiad |
| 0s | 93.0 | prometheus=ext,site=eqiad |
| 0s | 149.8 | prometheus=k8s-mlserve,site=codfw |
| 0s | 176.8 | prometheus=k8s-mlserve,site=eqiad |
| 0s | 212.2 | prometheus=services,site=codfw |
| 0s | 226.5 | prometheus=services,site=eqiad |
| 0s | 641.9 | prometheus=ops,site=codfw |
| 0s | 784.6 | prometheus=k8s,site=codfw |
| 0s | 815.2 | prometheus=k8s,site=eqiad |
| 0s | 891.4 | prometheus=ops,site=eqiad |
| 1h0m0s | 83.0 | prometheus=services,site=codfw |
| 1h0m0s | 88.1 | prometheus=services,site=eqiad |
| 1h0m0s | 386.1 | prometheus=k8s,site=codfw |
| 1h0m0s | 389.4 | prometheus=k8s,site=eqiad |
| 1h0m0s | 1038.4 | prometheus=ops,site=codfw |
| 1h0m0s | 1444.9 | prometheus=ops,site=eqiad |
| 5m0s | 64.8 | prometheus=k8s-mlstaging,site=codfw |
| 5m0s | 97.2 | prometheus=ext,site=eqiad |
| 5m0s | 106.8 | prometheus=k8s-staging,site=codfw |
| 5m0s | 138.7 | prometheus=k8s-staging,site=eqiad |
| 5m0s | 174.2 | prometheus=analytics,site=eqiad |
| 5m0s | 233.3 | prometheus=k8s-mlserve,site=codfw |
| 5m0s | 246.8 | prometheus=k8s-mlserve,site=eqiad |
| 5m0s | 700.0 | prometheus=services,site=codfw |
| 5m0s | 729.2 | prometheus=services,site=eqiad |
| 5m0s | 1728.5 | prometheus=k8s,site=codfw |
| 5m0s | 1754.4 | prometheus=k8s,site=eqiad |
| 5m0s | 8692.1 | prometheus=ops,site=codfw |
| 5m0s | 12164.1 | prometheus=ops,site=eqiad |
The equivalent sqlite query being:
SELECT resolution, ROUND(SUM(size_mb / 1024), 1) AS size_gb, REPLACE(REPLACE(labels, "replica=a,", ""), "replica=b,", "") AS instances FROM replicated_blocks JOIN blocks_sizes ON replicated_blocks.ulid = blocks_sizes.ulid WHERE until_timestamp < datetime('now', '-3 months') GROUP BY resolution, instances HAVING size_gb > 50 ORDER BY resolution, size_gb;