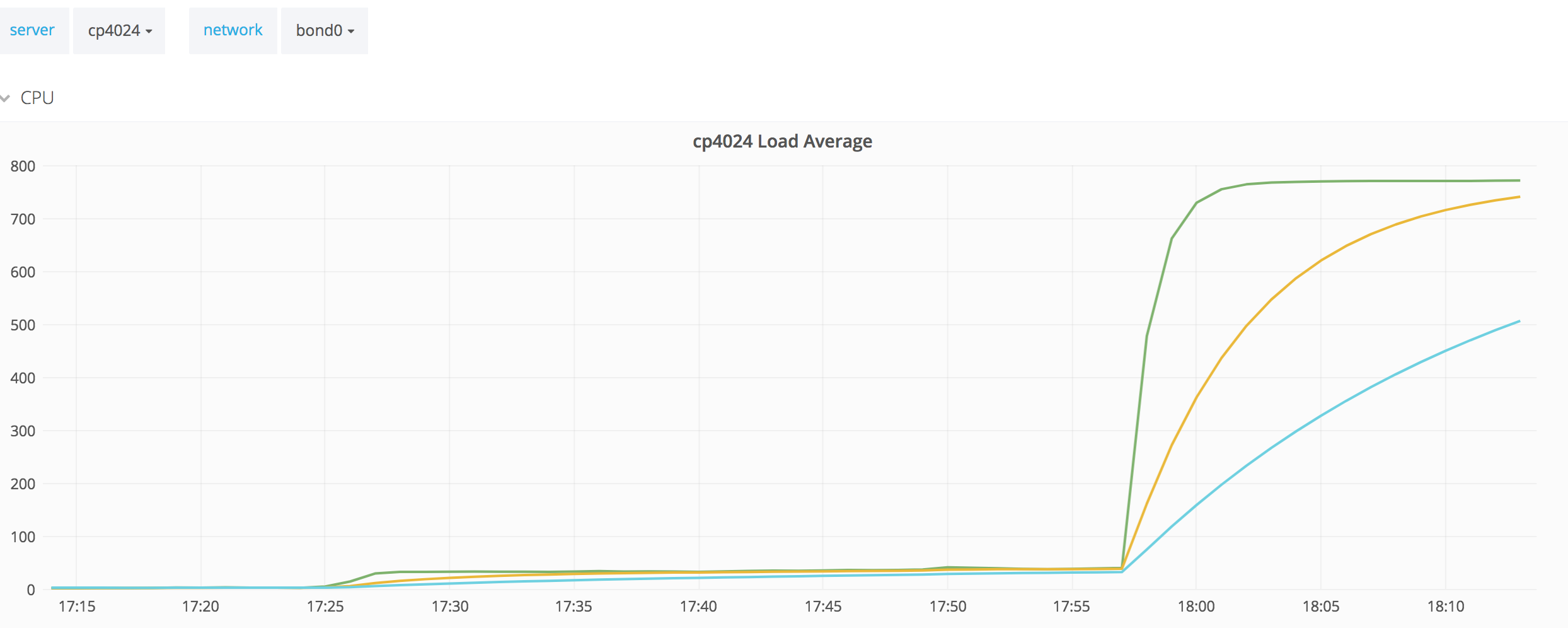
cp4024's varnish backend alarmed at around 17:28 UTC and several kernel errors were present in the dmesg, with this one popping up in the tty:
Message from syslogd@cp4024 at Sep 3 17:56:06 ... kernel:[30568.739024] NMI watchdog: BUG: soft lockup - CPU#41 stuck for 22s! [varnishd:2065]
Before doing anything I depooled it and then tried to restart Varnish with much success. Didn't try to attempt any reboot or similar to allow the Traffic team to better triage it.