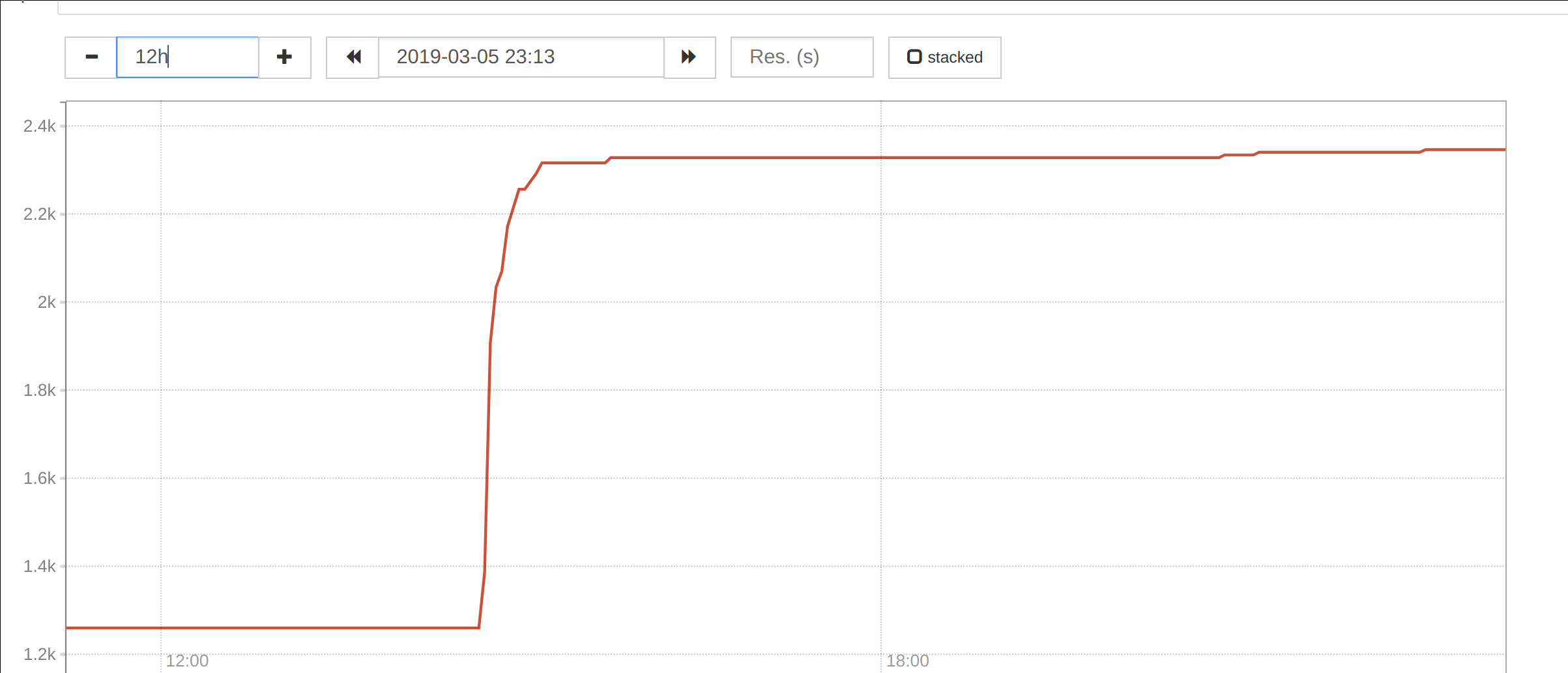
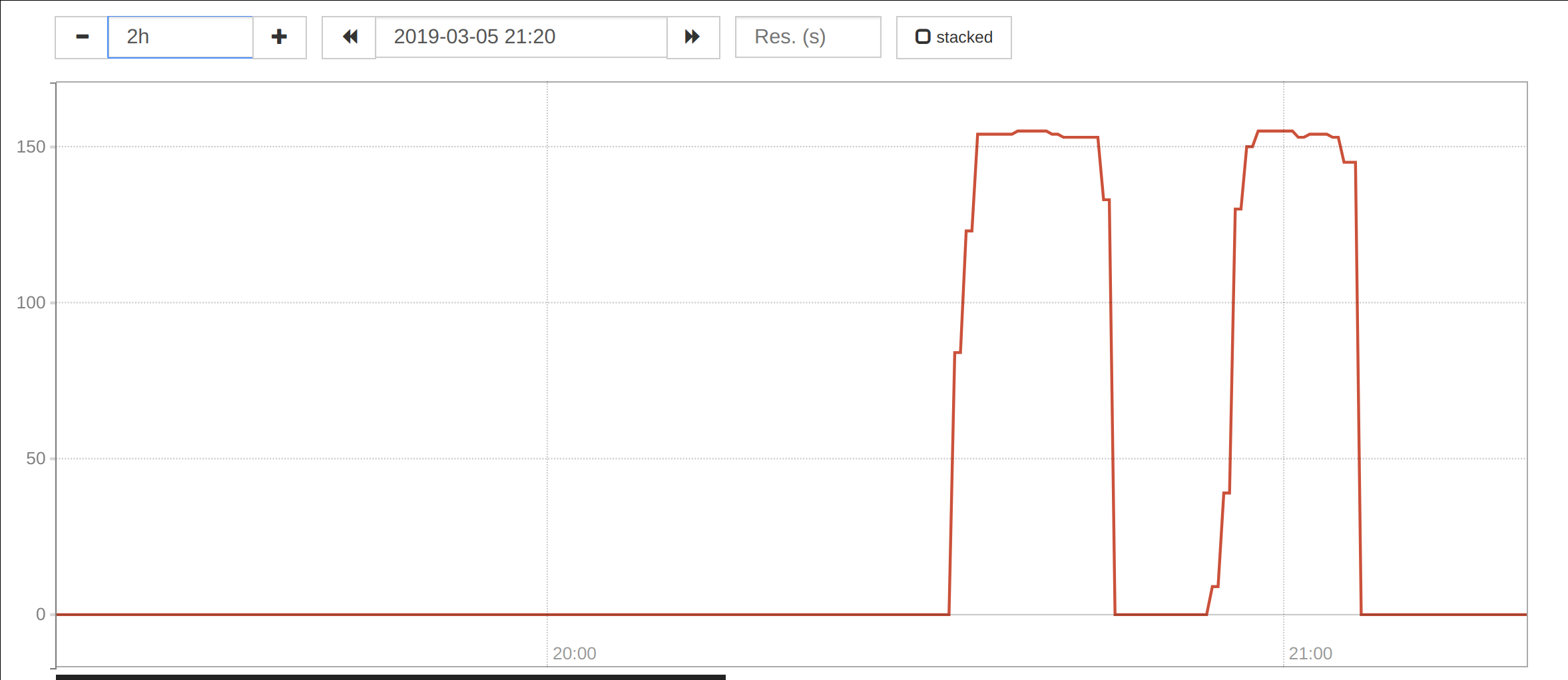
At 20:35UTC on Mar 5th, we were paged for the prometheus codfw svc IP, as well as grafana.
The apache on grafana1001 was unhealthy, as was the apache on prometheus2004. CPU usage on prometheus2004 was very high. (prometheus2003 is depooled for the prom2.x migration.)
An inspection of the apache logs on prometheus2004 showed many queries that were taking an inordinate amount of time (10-50 seconds) to evaluate:
https://phabricator.wikimedia.org/P8161 (NDA'd because it is unsanitized)
These same queries took ~200x less time when evaluated at 15:00 UTC just hours ago.
It is not clear why. Probably inspecting the prometheus tsdb and engaging with upstream will be necessary to diagnose this.
As a temporary mitigation, @fgiunchedi disabled queries against the k8s prometheus.