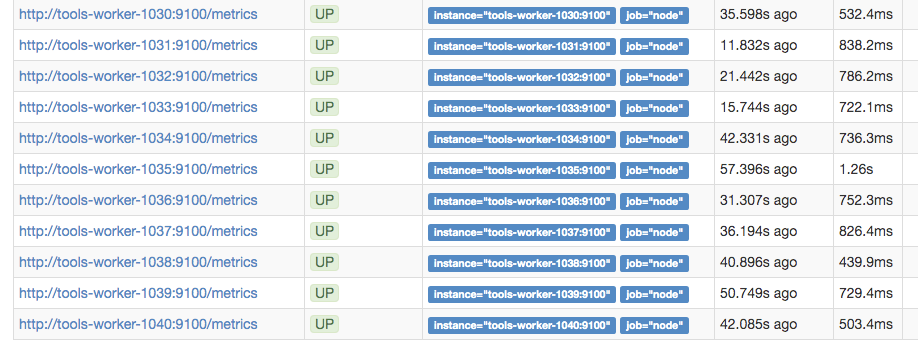
from https://tools-prometheus.wmflabs.org/tools/targets
It seems prometheus can not collect these metrics.
| aborrero | |
| Aug 8 2019, 5:37 PM |
| F30009129: image.png | |
| Aug 12 2019, 5:08 PM |
| F30000865: image.png | |
| Aug 8 2019, 5:37 PM |
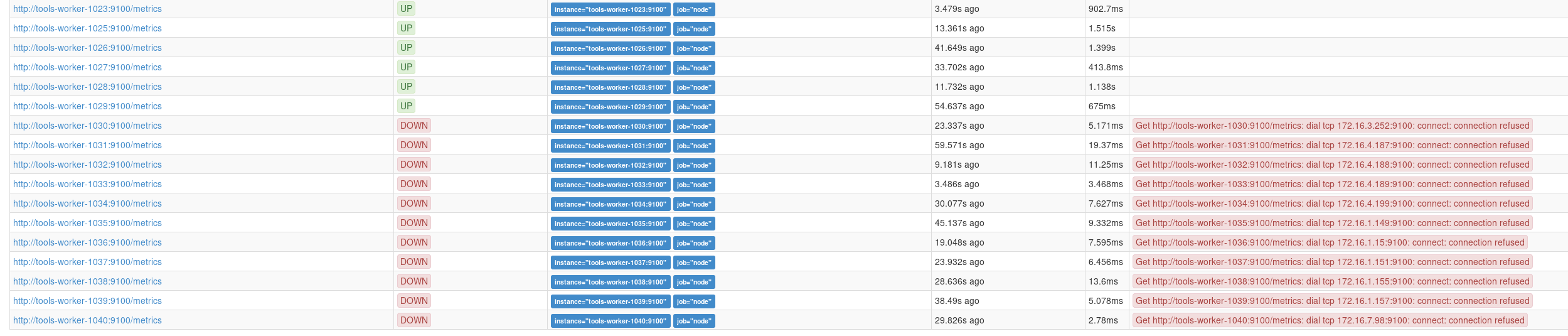
from https://tools-prometheus.wmflabs.org/tools/targets
It seems prometheus can not collect these metrics.
In horizon, "Instance Console Log", I can see the following logs for tools-worker-1030
[[32m OK [0m] Stopped Prometheus exporter for machine metrics.
Starting Prometheus exporter for machine metrics...
[[1;31mFAILED[0m] Failed to start Prometheus exporter for machine metrics.
See 'systemctl status prometheus-node-exporter.service' for details.During the prometheus-node-exporter.service startup, the following error occurs
Aug 06 18:04:45 tools-worker-1030 prometheus-node-exporter[661]: flag provided but not defined: -collector.buddyinfo
This is because the prometheus-node-exporter package is outdated and the the argument isn't supported yet.
For the fix, the prometheus-node-exporter package on tools-worker-10{30..40} needs to be updated from 0.14.0~git20170523-1 to 0.17.0+ds-3
I can confirm that the "working" nodes such as 029 already have prometheus-node-exporter package version 0.17.0+ds-3
That makes sense:
aborrero@tools-worker-1030:~$ apt-cache policy prometheus-node-exporter
prometheus-node-exporter:
Installed: 0.14.0~git20170523-1
Candidate: 0.17.0+ds-3
Version table:
0.17.0+ds-3 0
1001 http://apt.wikimedia.org/wikimedia/ jessie-wikimedia/main amd64 Packages
*** 0.14.0~git20170523-1 0
1001 http://apt.wikimedia.org/wikimedia/ jessie-wikimedia/backports amd64 Packages
100 /var/lib/dpkg/statusI would suggest we:
Mentioned in SAL (#wikimedia-cloud) [2019-08-12T16:08:26Z] <phamhi> updated prometheus-node-exporter from 0.14.0~git20170523-1 to 0.17.0+ds-3 in tools-worker-[1030-1040] nodes (T230147)
Mentioned in SAL (#wikimedia-cloud) [2019-08-12T20:39:59Z] <phamhi> toolsbeta-test-puppet-sandbox instance created for T230147
I created a new instance "toolsbeta-test-puppet-sandbox" with jessie image and it looks like it came with prometheus-node-exporter version 0.14.0 not 0.17.0. As per Arturo's suggestion, I am looking into create a Puppet patch for this issue.
Just for information, there's more than one quirk in building new Jessie K8s nodes. It may be worth it to just document the problem because pinning doesn't always prevent chicken/egg issues https://wikitech.wikimedia.org/wiki/Portal:Toolforge/Admin/Kubernetes#Building_new_nodes
Does it make more sense to close this ticket as the original issue has been resolved? We then create a new ticket to prevent this issue from re-occurring?
No, I think this is only resolved if "new kubernetes worker nodes" can export metrics. They'll fail if we spin up another one. I'm perfectly fine with just documenting that the package needs an upgrade (since there's packages that need downgrades as well), but a puppet pin of the package would resolve it as well. The reason I'm ok with just updating the docs is because this is re: Jessie nodes. We are going to deprecate Jessie. Otherwise, we'd surely insist on fixing this in puppet so the build is reproduceable.
We certainly need to spin up more nodes and those ones will have the same problem at this point.
I have updated the docs located at https://wikitech.wikimedia.org/wiki/Portal:Toolforge/Admin/Kubernetes#Worker_nodes to include the command to update the prometheus-node-exporter package after the build.
Documentation at https://wikitech.wikimedia.org/wiki/Portal:Toolforge/Admin/Kubernetes#Worker_nodes completed as per request. Marking as resolved.