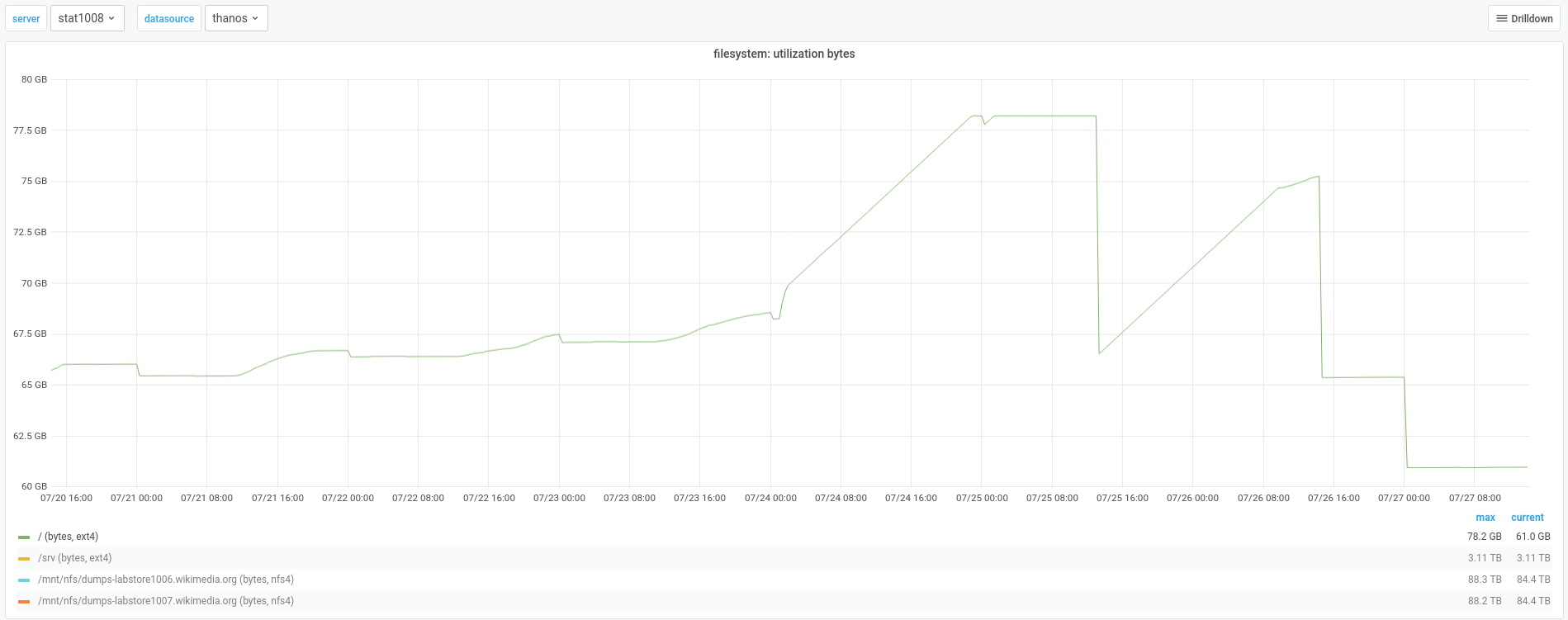
Hey folks,
just noticed that stat1008's root partition is full, and /var/log's size is around 20G (half of the partition size). The syslog logs are quite big, full of:
Jul 25 11:27:23 stat1008 bash[7938]: 21/07/25 11:27:23 ERROR AsyncEventQueue: Listener AppStatusListener threw an exception Jul 25 11:27:23 stat1008 bash[7938]: java.lang.NullPointerException Jul 25 11:27:23 stat1008 bash[7938]: #011at org.spark_project.guava.base.Preconditions.checkNotNull(Preconditions.java:191) Jul 25 11:27:23 stat1008 bash[7938]: #011at org.spark_project.guava.collect.MapMakerInternalMap.putIfAbsent(MapMakerInternalMap.java:3507) Jul 25 11:27:23 stat1008 bash[7938]: #011at org.spark_project.guava.collect.Interners$WeakInterner.intern(Interners.java:85) Jul 25 11:27:23 stat1008 bash[7938]: #011at org.apache.spark.status.LiveEntityHelpers$.weakIntern(LiveEntity.scala:603) Jul 25 11:27:23 stat1008 bash[7938]: #011at org.apache.spark.status.LiveRDDDistribution.toApi(LiveEntity.scala:486) Jul 25 11:27:23 stat1008 bash[7938]: #011at org.apache.spark.status.LiveRDD$$anonfun$2.apply(LiveEntity.scala:548) Jul 25 11:27:23 stat1008 bash[7938]: #011at org.apache.spark.status.LiveRDD$$anonfun$2.apply(LiveEntity.scala:548) Jul 25 11:27:23 stat1008 bash[7938]: #011at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234) Jul 25 11:27:23 stat1008 bash[7938]: #011at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234) Jul 25 11:27:23 stat1008 bash[7938]: #011at scala.collection.mutable.HashMap$$anon$2$$anonfun$foreach$3.apply(HashMap.scala:139) Jul 25 11:27:23 stat1008 bash[7938]: #011at scala.collection.mutable.HashMap$$anon$2$$anonfun$foreach$3.apply(HashMap.scala:139) Jul 25 11:27:23 stat1008 bash[7938]: #011at scala.collection.mutable.HashTable$class.foreachEntry(HashTable.scala:236) Jul 25 11:27:23 stat1008 bash[7938]: #011at scala.collection.mutable.HashMap.foreachEntry(HashMap.scala:40) Jul 25 11:27:23 stat1008 bash[7938]: #011at scala.collection.mutable.HashMap$$anon$2.foreach(HashMap.scala:139) Jul 25 11:27:23 stat1008 bash[7938]: #011at scala.collection.TraversableLike$class.map(TraversableLike.scala:234) Jul 25 11:27:23 stat1008 bash[7938]: #011at scala.collection.AbstractTraversable.map(Traversable.scala:104) Jul 25 11:27:23 stat1008 bash[7938]: #011at org.apache.spark.status.LiveRDD.doUpdate(LiveEntity.scala:548) Jul 25 11:27:23 stat1008 bash[7938]: #011at org.apache.spark.status.LiveEntity.write(LiveEntity.scala:49) Jul 25 11:27:23 stat1008 bash[7938]: #011at org.apache.spark.status.AppStatusListener.org$apache$spark$status$AppStatusListener$$update(AppStatusL istener.scala:991) Jul 25 11:27:23 stat1008 bash[7938]: #011at org.apache.spark.status.AppStatusListener.org$apache$spark$status$AppStatusListener$$maybeUpdate(AppSt atusListener.scala:997) Jul 25 11:27:23 stat1008 bash[7938]: #011at org.apache.spark.status.AppStatusListener$$anonfun$onExecutorMetricsUpdate$2.apply(AppStatusListener.scala:764) Jul 25 11:27:23 stat1008 bash[7938]: #011at org.apache.spark.status.AppStatusListener$$anonfun$onExecutorMetricsUpdate$2.apply(AppStatusListener.scala:764) Jul 25 11:27:23 stat1008 bash[7938]: #011at scala.collection.mutable.HashMap$$anon$2$$anonfun$foreach$3.apply(HashMap.scala:139) Jul 25 11:27:23 stat1008 bash[7938]: #011at scala.collection.mutable.HashMap$$anon$2$$anonfun$foreach$3.apply(HashMap.scala:139) Jul 25 11:27:23 stat1008 bash[7938]: #011at scala.collection.mutable.HashTable$class.foreachEntry(HashTable.scala:236) Jul 25 11:27:23 stat1008 bash[7938]: #011at scala.collection.mutable.HashMap.foreachEntry(HashMap.scala:40) Jul 25 11:27:23 stat1008 bash[7938]: #011at scala.collection.mutable.HashMap$$anon$2.foreach(HashMap.scala:139) Jul 25 11:27:23 stat1008 bash[7938]: #011at org.apache.spark.status.AppStatusListener.org$apache$spark$status$AppStatusListener$$flush(AppStatusListener.scala:788) Jul 25 11:27:23 stat1008 bash[7938]: #011at org.apache.spark.status.AppStatusListener.onExecutorMetricsUpdate(AppStatusListener.scala:764) Jul 25 11:27:23 stat1008 bash[7938]: #011at org.apache.spark.scheduler.SparkListenerBus$class.doPostEvent(SparkListenerBus.scala:59) Jul 25 11:27:23 stat1008 bash[7938]: #011at org.apache.spark.scheduler.AsyncEventQueue.doPostEvent(AsyncEventQueue.scala:37) Jul 25 11:27:23 stat1008 bash[7938]: #011at org.apache.spark.scheduler.AsyncEventQueue.doPostEvent(AsyncEventQueue.scala:37) Jul 25 11:27:23 stat1008 bash[7938]: #011at org.apache.spark.util.ListenerBus$class.postToAll(ListenerBus.scala:91) Jul 25 11:27:23 stat1008 bash[7938]: #011at org.apache.spark.scheduler.AsyncEventQueue.org$apache$spark$scheduler$AsyncEventQueue$$super$postToAll(AsyncEventQueue.scala:92) Jul 25 11:27:23 stat1008 bash[7938]: #011at org.apache.spark.scheduler.AsyncEventQueue$$anonfun$org$apache$spark$scheduler$AsyncEventQueue$$dispatch$1.apply$mcJ$sp(AsyncEventQueue.scala:92) Jul 25 11:27:23 stat1008 bash[7938]: #011at org.apache.spark.scheduler.AsyncEventQueue$$anonfun$org$apache$spark$scheduler$AsyncEventQueue$$dispatch$1.apply(AsyncEventQueue.scala:87) Jul 25 11:27:23 stat1008 bash[7938]: #011at org.apache.spark.scheduler.AsyncEventQueue$$anonfun$org$apache$spark$scheduler$AsyncEventQueue$$dispatch$1.apply(AsyncEventQueue.scala:87) Jul 25 11:27:23 stat1008 bash[7938]: #011at scala.util.DynamicVariable.withValue(DynamicVariable.scala:58) Jul 25 11:27:23 stat1008 bash[7938]: #011at org.apache.spark.scheduler.AsyncEventQueue.org$apache$spark$scheduler$AsyncEventQueue$$dispatch(AsyncEventQueue.scala:87) Jul 25 11:27:23 stat1008 bash[7938]: #011at org.apache.spark.scheduler.AsyncEventQueue$$anon$1$$anonfun$run$1.apply$mcV$sp(AsyncEventQueue.scala:83) Jul 25 11:27:23 stat1008 bash[7938]: #011at org.apache.spark.util.Utils$.tryOrStopSparkContext(Utils.scala:1302) Jul 25 11:27:23 stat1008 bash[7938]: #011at org.apache.spark.scheduler.AsyncEventQueue$$anon$1.run(AsyncEventQueue.scala:82)
The bash script is:
christi+ 7938 0.0 0.0 6912 3384 ? Ss Jul01 0:00 /bin/bash /etc/jupyterhub-conda/jupyterhub-singleuser-conda-env.sh /home/christinedk/.conda/envs/2021-02-17T16.48.34_christinedk --port=36749 --NotebookApp.default_url=/lab
And this leads to:
494M /var/log/jupyterhub-conda 1.5G /var/log/messages 1.5G /var/log/syslog 1.5G /var/log/user.log 3.3G /var/log/syslog.1 5.3G /var/log/messages.1 5.3G /var/log/user.log.1