Open data collections -- like Wikidata -- are created and maintained by volunteers and are thriving on community knowledge. Missing or new information needs to be added by community members. Otherwise, the knowledge base will dry out and be obsolete after a while. Hence, changing and completing a knowledge base is a crucial task within any community-driven initiative. Consequently, we consider helping people to integrate their knowledge into a knowledge base as a crucial task and defined it as the long-term goal of our initiative.
Considering the editing process, users are enabled to use the Wikibase editor to change the data. However, most of the data is published in unstructured textual form. The main sources for new or updated facts are Wikipedia and other HTML pages like News portals. Obviously, it is not easy for Wikidata editors to identify these pieces of information, and even if they do, then integrating the discovered information is a time-consuming process. We value the time of Wikidata editors a lot, so we define increasing the efficiency of the editing process as our goal.
In the past, other approaches tried to tackle the obstacles. For example, the Wikibase plugin Recoin [1,2] was developed to suggest to editors typical properties while browsing an entity that is present in similar entities but is missing within the current entity. In our earlier research [3] we already showed that it is possible to find outliers in graph-based knowledge bases which need to be checked by experts to ensure the data quality. The WikidataComplete fact extraction implementation [4,5] shows how facts are extracted from text documents and offered to users for validation (outside of Wikidata). Recently we published the WikidataComplete plugin [6] that was developed during a Google Summer of Code 2021 project. There it is already possible to point Wikidata editors to new facts and prepare the forms within the Wikidata UI for almost instant evaluation and confirmation (cf. the presentations at [7] and the YouTube tutorial at [8]). The plugin already helped to integrate many new facts into Wikidata.
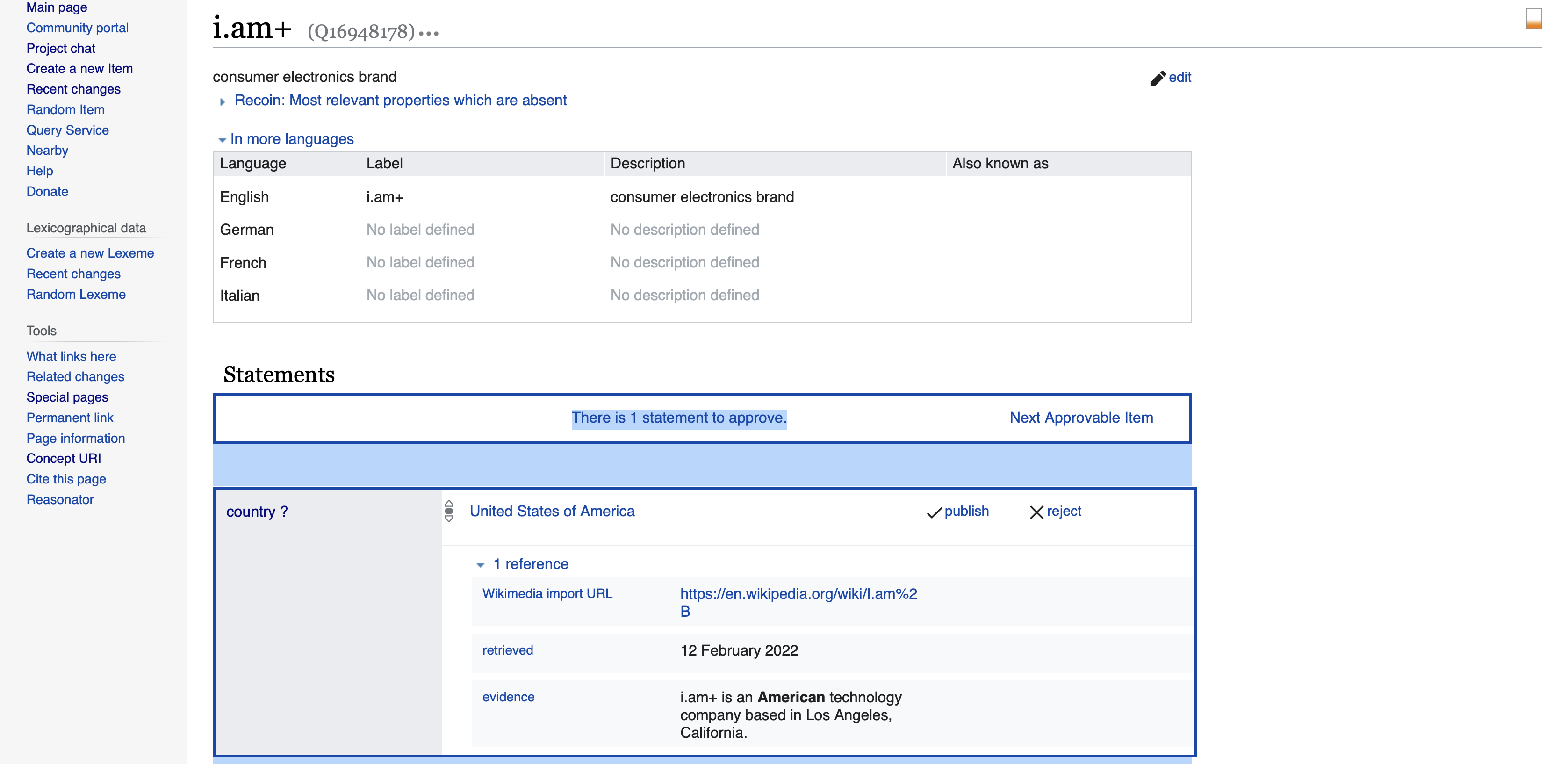
As the community has reached out to us regarding additional data sources for facts, we propose here an extension of the WikidataComplete plugin towards an infrastructure where data donations can be stored and therefore provided to Wikidata editors. This WikidataComplete ecosystem will consist of Web service interfaces to push data from different sources, s.t., researchers, and industry can easily integrate it into their systems and efficiently help to extend the Wikidata knowledge base. Consequently, while opening the raw data collection process for additional contributors we also should integrate an improved recommendation process to point an editor to a fact that he/she would likely be capable of approving (because it’s in the editor’s scope of expertise). Additionally, we should use the information to show appreciation to active editors while establishing a leaderboard and other gamification extensions.
Goals
global: Improve the editing process for changing/extending Wikidata facts
Implement Webservice interfaces for data donations, i.e., sets of approvable facts (which should also contain links to evidence, etc.)
optional: Implement a recommendation engine that suggests agreeable facts to Wikidata editors that are likely to be in their area of expertise.
optional: Extend the gamification features to show appreciation to Wikidata editors, e.g., a badge Web service allowing users to integrate their score/rank into their profiles of social networks (e.g., on Wikidata’s user page, GitHub profile, Linkedin profile) to show their dedication and activate other users.
Impact
Data donations are possible and at the same time, an efficient approval process is supported.
More fact ingestions with the help of the Wikimedia community.
Faster integration of new facts into Wikidata.
The long-term impact of our project is an increase of editors which finally will lead to a stronger Wikidata knowledge base through better integration of additional data sources as well as more editors. Hence, the quality and quantity of the open data offered by Wikidata will increase.
Warm-up tasks
Activate the WikidataComplete plugin [6,7] in your Wikibase account to work with the current implementation
Select 3 Wikidata entities and manually find missing facts based on external data sources
Checkout this tool https://www.wikidata.org/wiki/Wikidata:Primary_sources_tool
Understand the Wikidatacomplete UI and APIs [4,5] which is currently considered to be the (default) data donator
Get familiar with the data structure available in Wikidata
Set up a MediaWiki development environment
Mentors
Dennis Diefenbach
Andreas Both
Kunpeng Guo
Aleksandr Perevalov
The project size can follow the medium-sized (~175 hours) and large (~350 hours) format. However, we prefer the large format as it provides more opportunities to increase the impact.
Keywords
Data Editing, Data Quality, Data Curation, Knowledge Graph completion, Recommendation Engine, Gamification, Machine Learning, Natural Language Processing, Open Data
[1] https://www.wikidata.org/wiki/Wikidata:Recoin
[2] Vevake Balaraman, Simon Razniewski, Werner Nutt. Recoin: Relative Completeness in Wikidata. Wiki Workshop at The Web Conference 2018
[3] Didier Cherix, Ricardo Usbeck, Andreas Both, and Jens Lehmann (2014). Lessons learned—the case of crocus: Cluster-based ontology data cleansing. In European Semantic Web Conference (pp. 14-24). Springer, Cham.
[4] https://wikidatacomplete.org/
[5] Bernhard Kratzwald, Guo Kunpeng, Stefan Feuerriegel, and Dennis Diefenbach. IntKB: A Verifiable Interactive Framework for Knowledge Base Completion. International Conference on Computational Linguistics (COLING), 2020
[6] https://www.wikidata.org/wiki/Wikidata:WikidataComplete
[7] Presentation at Wikidata Quality days 2021: https://docs.google.com/presentation/d/1Hb5q5a2CC2XgXk_lvTkAQrc9SBtvi0MhBUwwAXbn5m0/edit?usp=sharing
[8] WikidataComplete Plugin Tutorial: https://www.youtube.com/watch?v=Ju2ExZ_khxQ