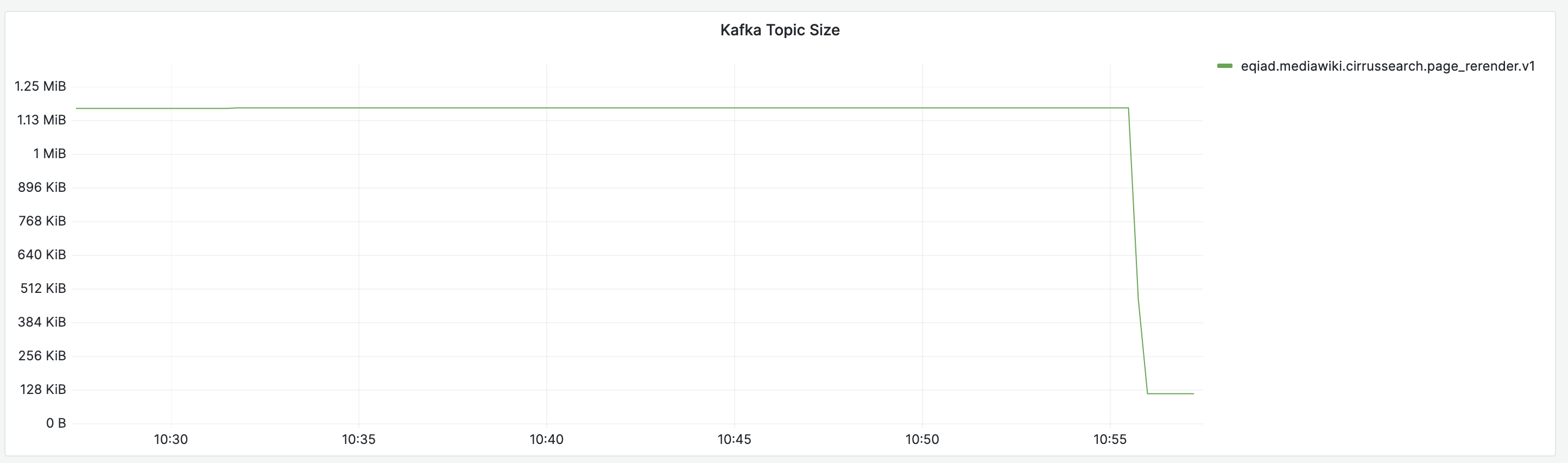
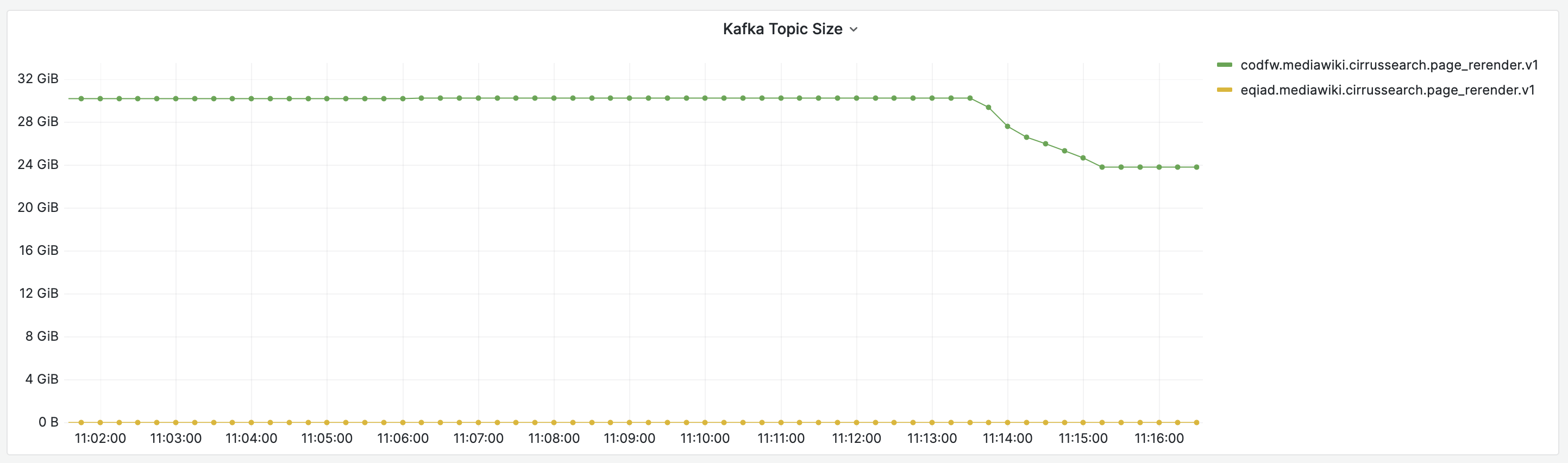
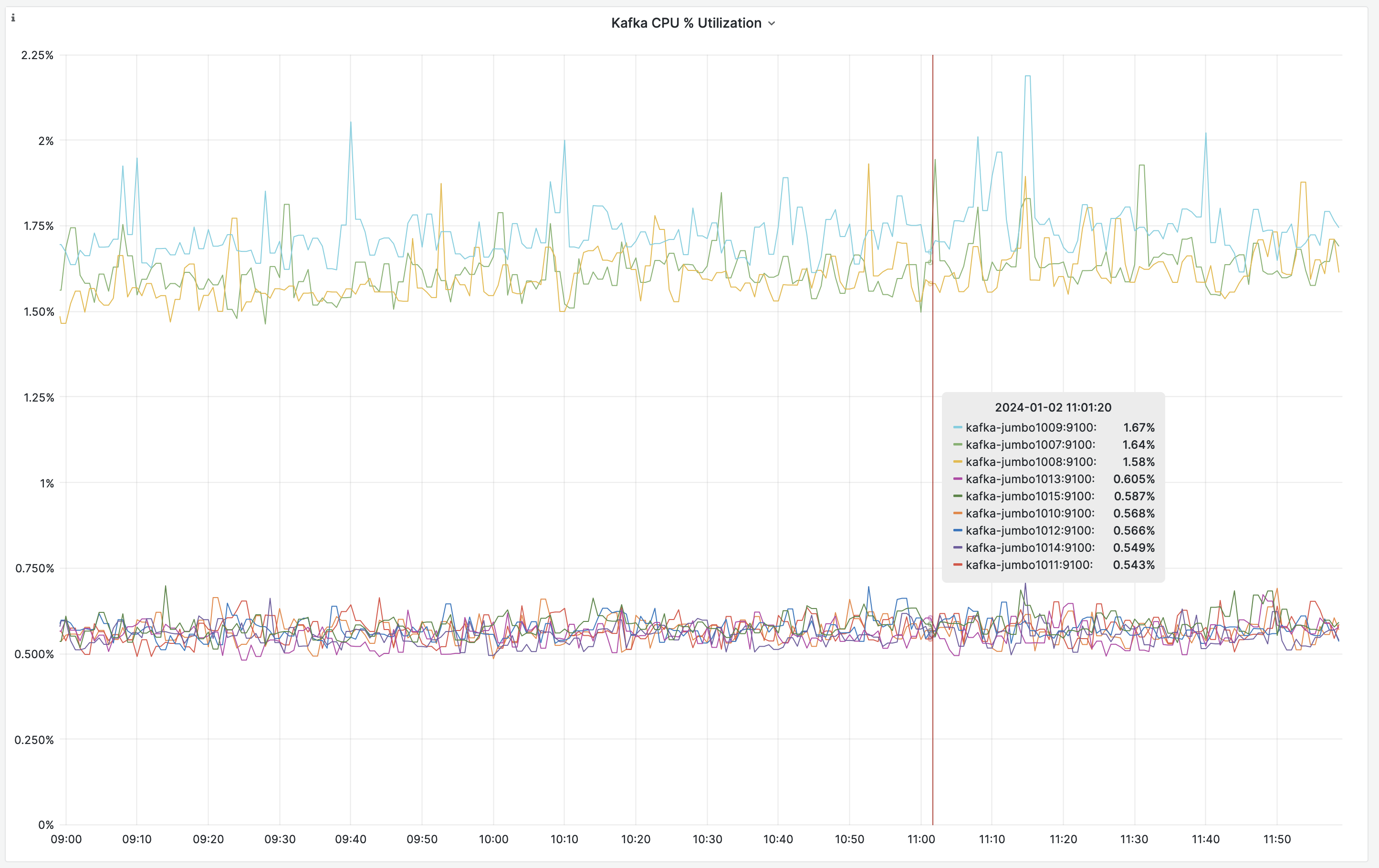
Since page_rerender is a particular chatty topic (~300 records/s expected), we would like to work with log compaction to keep only the latest record per key. Enabling this might increase CPU usage of brokers, therefore, we'd like to test this on kafka-jumbo first.
AC:
- log compaction in combination with retention-based delete (cleanup.policy=[compact,delete]) is enabled for both topics on kafka-jumbo:
- codfw.mediawiki.cirrussearch.page_rerender.v1
- eqiad.mediawiki.cirrussearch.page_rerender.v1
- monitored impact on CPU utilisation