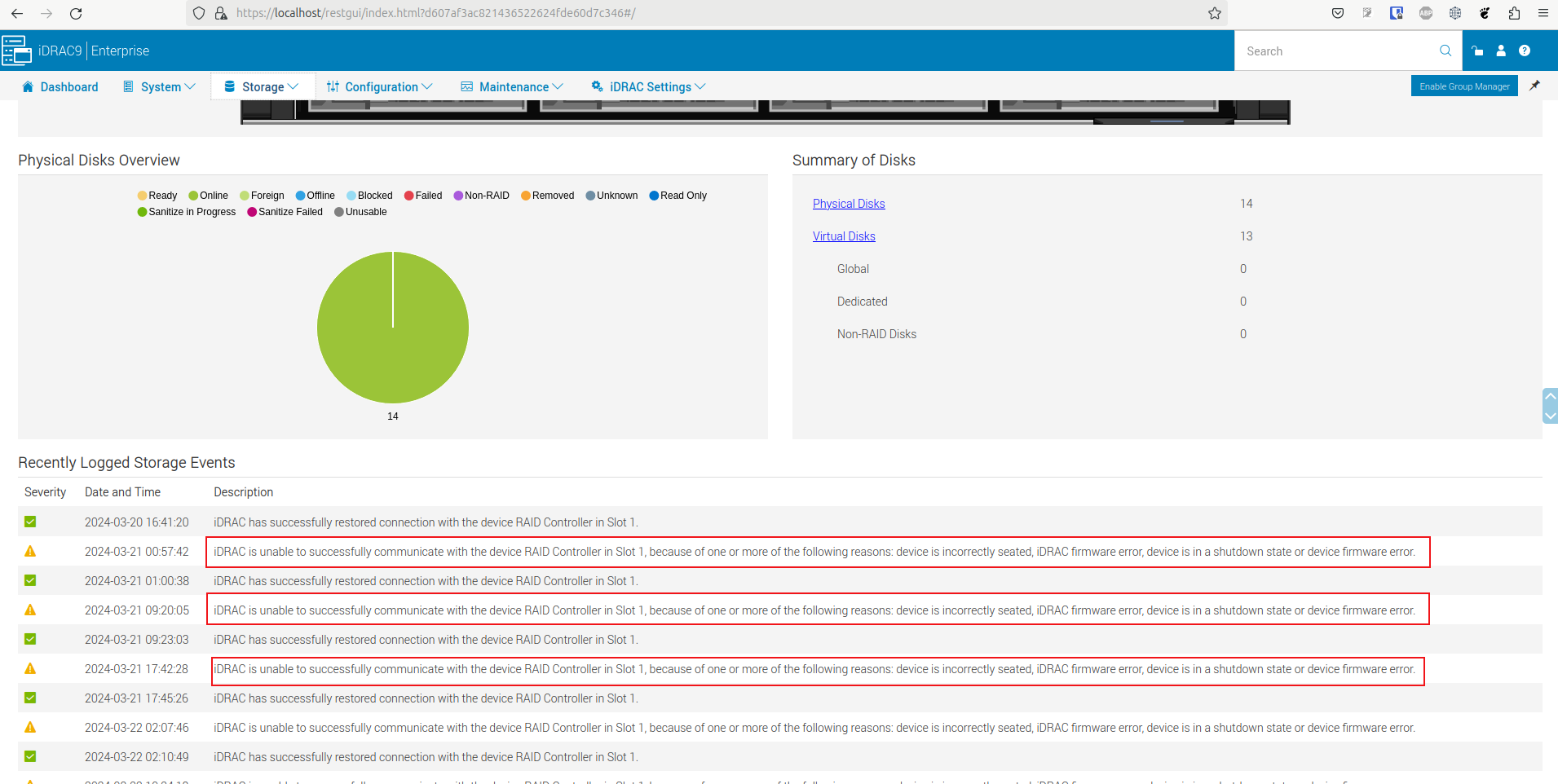
Since 2024-03-10 19:46:40 an-worker1168 is alerting for different alerts
PROCS CRITICAL: 0 processes with command name 'java', args 'org.apache.hadoop.yarn.server.nodemanager.NodeManager'
and
ERROR ferm input drop default policy not set, ferm might not have been started correctly
and
NRPE: Unable to read output
and
Failed to execute ['/usr/local/lib/nagios/plugins/get-raid-status-perccli']: KeyError 'System Overview'
and
PROCS CRITICAL: 0 processes with command name 'java', args 'org.apache.hadoop.hdfs.server.datanode.DataNode'
I tried to ssh in and got
ssh an-worker1168.eqiad.wmnet -bash: [: : integer expression expected -bash: /etc/profile.d/bash_completion.sh: Input/output error -bash: /usr/bin/tput: Input/output error -bash: /usr/bin/tput: Input/output error -bash: /usr/bin/tput: Input/output error -bash: /usr/bin/tput: Input/output error -bash: /usr/lib/systemd/user-environment-generators/30-systemd-environment-d-generator: Input/output error -bash: /usr/bin/dircolors: Input/output error -bash: /etc/bash_completion: Input/output error Connection to an-worker1168.eqiad.wmnet closed.
iDRAC console shows after console com2 is issued
[918641.688106] EXT4-fs (dm-1): I/O error while writing superblock [918641.694150] EXT4-fs error (device dm-1): __ext4_find_entry:1583: inode #787528: comm bash: reading directory lblock 0 [918641.704870] Buffer I/O error on dev dm-1, logical block 0, lost sync page write [918641.712347] EXT4-fs (dm-1): I/O error while writing superblock [918645.811770] blk_update_request: I/O error, dev sdl, sector 23035688 op 0x0:(READ) flags 0x0 phys_seg 1 prio class 0 [918645.822493] blk_update_request: I/O error, dev sdl, sector 23035688 op 0x0:(READ) flags 0x0 phys_seg 1 prio class 0 [918651.986146] blk_update_request: I/O error, dev sdl, sector 116504432 op 0x0:(READ) flags 0x0 phys_seg 1 prio class 0 [918651.996952] blk_update_request: I/O error, dev sdl, sector 116504432 op 0x0:(READ) flags 0x0 phys_seg 1 prio class 0 [918653.356753] blk_update_request: I/O error, dev sdl, sector 51154752 op 0x0:(READ) flags 0x0 phys_seg 1 prio class 0 [918653.367580] blk_update_request: I/O error, dev sdl, sector 114158864 op 0x0:(READ) flags 0x0 phys_seg 1 prio class 0 [918653.378778] blk_update_request: I/O error, dev sdl, sector 114158776 op 0x0:(READ) flags 0x0 phys_seg 1 prio class 0 [918653.389598] blk_update_request: I/O error, dev sdl, sector 114158776 op 0x0:(READ) flags 0x0 phys_seg 1 prio class 0 [918653.400460] blk_update_request: I/O error, dev sdl, sector 114158776 op 0x0:(READ) flags 0x0 phys_seg 1 prio class 0
in a loop
Something has probably gone really bad with the underlying disk. Judging from the many days already this alerts is ongoing and not handled, I assume it's not critical so I am ACKing it in alerts.wikimedia.org pointing to this task.
Can someone from data-engineering investigate more please?