
User Details
- User Since
- Jun 2 2021, 3:53 PM (151 w, 1 d)
- Availability
- Available
- LDAP User
- Trokhymovych
- MediaWiki User
- Unknown
Thu, Apr 11
Updates
I was working on the experimental model using a multilingual language model.
It was evaluated and compared with the ORES model on the time-based hold-out dataset of the revisions from 2023.
Mar 4 2024
Merged. Thank you!
Mar 3 2024
Dec 20 2023
@isarantopoulos Thank you! I have checked and merged your changes.
Jul 25 2023
I have checked the proposed changes (MR: https://gitlab.wikimedia.org/repos/research/knowledge_integrity/-/merge_requests/17).
Jul 3 2023
I have reviewed the logs with errors from the multilingual model, and it seems to be a problem with resources.
May 22 2023
Cleaned up 'trokhymovych'
Mar 28 2023
@jbond
New Public SSH key:
ssh-ed25519 AAAAC3NzaC1lZDI1NTE5AAAAIFCyl+eu4X9cI/XT6nCSvud+X6LJyVV7Rcr1g4MnP2xf trokhymovych.mykola@gmail.com
Feb 21 2023
Previously, we tested the TreeSHAP algorithm for Multilingual model explainability (from here: https://shap.readthedocs.io/en/latest/). It is supported by the tools provided in the task description. The main benefit is that it works with our classifiers and provides local explainability (so we can have an explanation for each specific sample without any other data needed).
Nov 30 2022
- I have prepared the MR with the multilingual model inference implementation: https://gitlab.wikimedia.org/repos/research/knowledge_integrity/-/tree/mykola/multilingual_initial
- The model is temporary saved on google drive (as it is too large to save it in repo): https://drive.google.com/file/d/1ZffeT-tm99CpI9HgydyhV_7xUS02ZiIr/view?usp=share_link
- I have prepared the little (1000 samples) random test sample to perform inference time evaluation. I got the following results: median inference time is 3.72s, 90% percentile is 9.94s, 95% percentile is 12.56s.
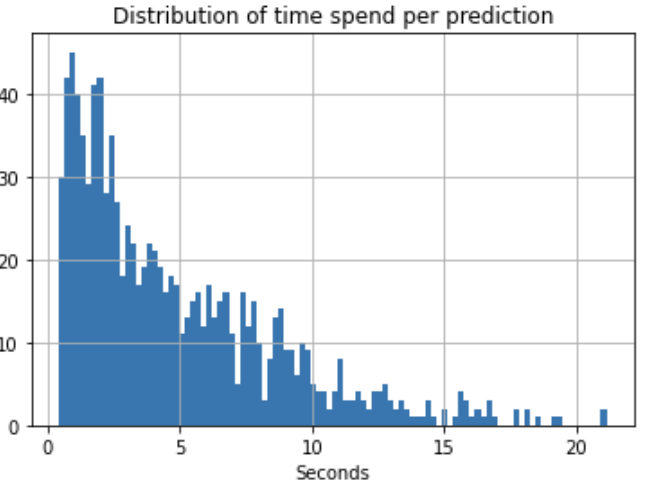
Oct 25 2022
- I was working on model results interpretation and prepared a notebook with examples of per-sample SHAP values for final model results. Also, I was investigating the method to interpret each independent text model for better understanding and further improvement.
- Prepared and held a presentation of intermediate research results.
- Later, I worked on model validation using one week's data, including data collection, features collection, and building report. Also, I was investigating the package that implements the language agnostic model for further possible usage for my model inference feature engineering. Finalized report for complete hold-out data on the one-week dataset. I performed a sample-wise analysis of the differences between models.
- Studied the possibility of building the model on top of the language-agnostic, ores, and multilingual models that generalize the knowledge. Evaluated it using hold-out.
Oct 2 2022
This week I was working on a complex model that considers meta-features and text changes. What was done:
- Finetuned models for text-based feature generation (comments, title semantics, changes, inserts). I evaluated them separately. I later extracted features for the complex model from the last layer before softmax + softmax layer outputs for each model (except title semantics, as it was trained as a regression model).
- Trained model added all features from texts on the data part that was not used in the text model finetuning to omit leakage. As a result, I got a boost in accuracy score (~70%->74% on balanced test)
- Started error analysis and results observation.
Sep 24 2022
- Collected datasets for more languages (pl, de, es) and recollected previous ones to proceed with the time-dependent experiment
- Experimented with multilingual models training for inserts and changes as preparation for finetuning on multiple languages.
- I highly rely on the mwedittypes package, which uses mwparserfromhell for wikitext parsing. It was reported that an open issue exists that mwparserfromhell causes a very long to infinite parsing. It can be a possible signal of vandalism that is a signal that we want to detect. I have checked that ~1.0% of revisions had problems parsing the wikitext (pretty much the same for all languages). The revert rate for both parsed and not parsed revisions was the same, so this signal is probably not as strong as expected. I decided to consider it in the final model with binary feature is_parsed.
- Implemented bootstrap strategy for defining confidence intervals of statistics calculated for regions analysis (it is desired to understand the confidence of results I got while analyzing the revert rate for different regions of user/page)
- Designed the architecture of an end-to-end model that considers both revision features and text features. Started implementing pipeline for experiments with such architecture.
Sep 18 2022
- Recollected dataset for anonymous users only and fixed minor bugs in text processing.
- Checked profanity score package - list of bad words (https://pypi.org/project/profanity-check/) -> not working, very weak signal
- Parsed page's semantic information for further processing (article categories), added wikidata_id.
- Attempted to get Wikidata embedding, but not successfully. Pretrained models are either huge or include less than 20% of needed entities.
- Check topics classification tool and country classification tools: https://wiki-topic.toolforge.org/. I found the country classification tool very insightful. Previously, I found out that the location of anonymous users influences the revert rate. However, combining page location and user location gives even more exciting insights that can be useful for revert event modeling.
Sep 9 2022
- Collect dataset of changes for ruwiki, enwiki, and ukwiki along with text changes (inserts, changes, removes)
- Performed EDA for collected datasets
- Build toxicity features of inserts and changes based on detoxify package, checked the predictive power of those features -> they slightly improve the baseline performance, but not significantly.
- Checked text changes meta-features of inserts and changes extracted using https://pypi.org/project/mwedittypes/, checked the predictive power of those features -> they improve the baseline performance.
- Performed initial analysis of changes in references.
- Checked the hypothesis that user location impacts the model's possibility to detect revisions that would be reverted. As a result, the experiment showed that those have good predictive power, which is comparable with text changes meta-features. In addition, I created a more detailed report for the correlation between anonymous users' locations and revert rates, which can be found in the attachment.
Aug 26 2022
- Performed EDA for wmf.mediawiki_history
- Got familiar with data
- Found out insights important for training dataset building (a significant number of self-revert, different rate of reverts for groups of users)
- Manually explored recent changes (text differences) for ukwiki, ruwiki, enwiki
- Find out the differences in causes of reverts for different languages. It should be taken into account while modeling.
- Got familiar with the logic of reverts, revert-wars
- Came out with a logic that can reduce noise from the training dataset by filtering "bad" reverts caused by revision wars.
- Get familiar with the Analytics cluster
Aug 17 2022
@cmooney I have already reviewed and signed the Server Access Responsibilities Document
Can you please delete all my old keys and leave only the one I have provided in this ticket? Thank you!
Public SSH key:
ssh-ed25519 AAAAC3NzaC1lZDI1NTE5AAAAIB8/dfbAQjsOu3EzPIosLsY0Dxz0LOMtW2dKPndAqDnh trokhymovych.mykola@gmail.com
Jun 20 2021
Updates:
- Experimented with multilingual models
- Developed a methodology to train large multilingual models that does not fit into memory
- Explored existing multilingual NLI datasets
Jun 13 2021
Updates:
- Finished documentation for API.
- Included brief System architecture observation
- Included Pointers to the code
- Included Explanation: how to replicate the API
- Included Description of the 3 end points, and examples
Jun 4 2021
Updates
- Deployed initial version of WikiCheck API.
- Implemented NLI model endpoint
- Implemented fact checking endpoint
- Experimented with aggregation strategies