I am Max Klein,
I work by myself and publish my research at notconfusing.com. And I also work with GroupLens Research.
I am Max Klein,
I work by myself and publish my research at notconfusing.com. And I also work with GroupLens Research.
I thought I had fixed it but some old code was still running after I made the push. I reset the state, so I pe it is now fixed. I will leave the ticket ofen until we feel more confident in stability.
its been running for years and we think we are right
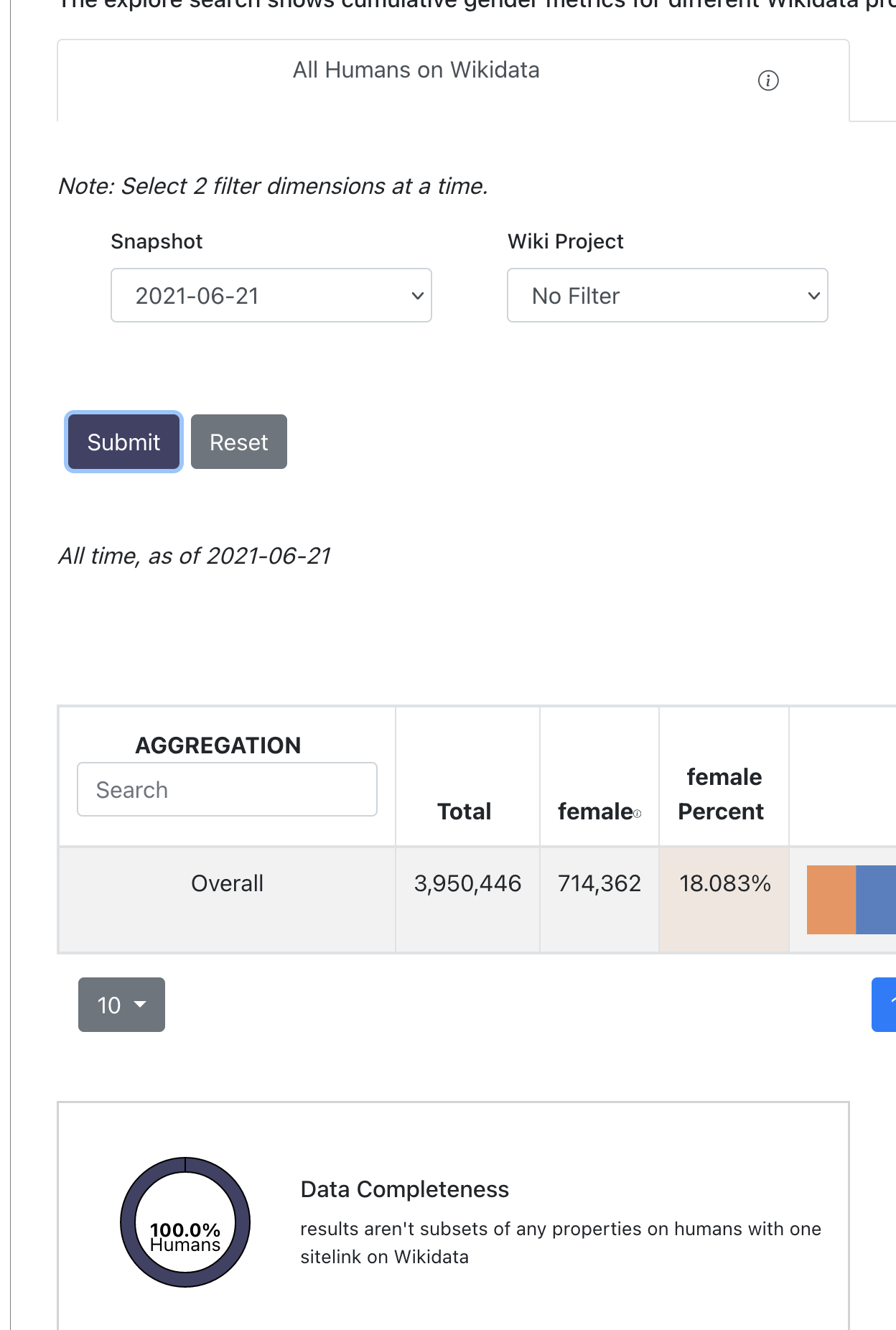
STEPS to implement back-end generation:
need to see this happen in action
moved to 3 on production
ExecStart=/srv/venv/bin/gunicorn --bind unix:humaniki.sock -m 777 -t 60 wsgi:app -e --workers 3
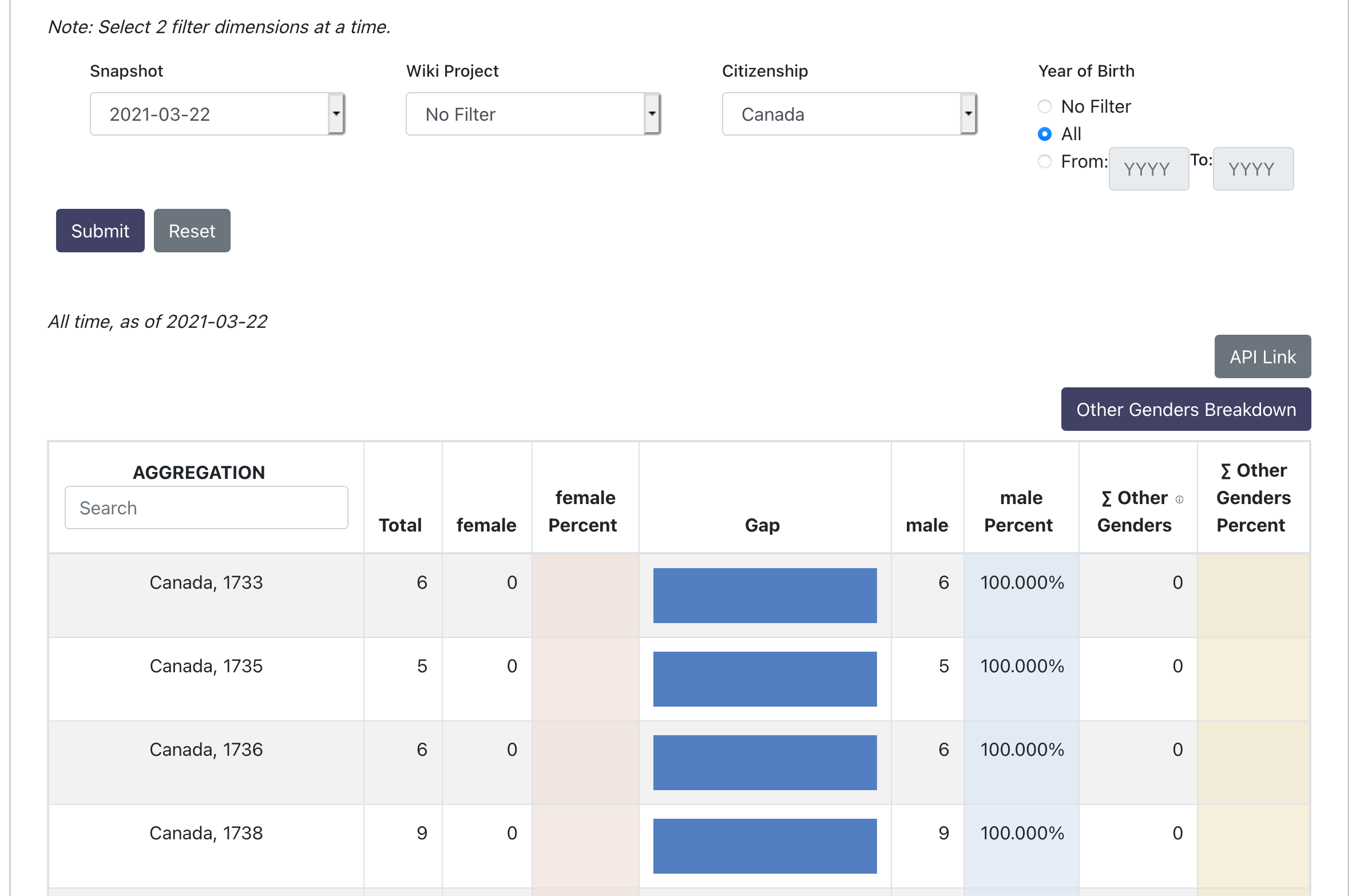
I have isolated this to humaniki-backends query.py we check if "all of the properties are "all"" but not just some of them.
needed to convert to percent first, then fix to 1 digit because fixing causes float to string conversion.