ORES provides machine learning as a service for Wikimedia projects. The ORES model articletopic was used for the Growth team project - Suggested edits for newcomers on Special: Homepage.
Testing ORES models always presents several challenges
- understanding the background
- testing the model logic
- UI testing to see how the specific model logic is presented to users
Understanding background and terms
Special:RecentChanges and Special:Watchlist were the previous projects where ORES models damaging and goodfaith were tested. Another project - Special:NewPagesFeed (PageTriage) involved testing articlequality ORES model. Testing those models was insightful and quite helpful when articletopic model was used for the Homepage Suggested edits project.
The starting point for all ORES models testing is to understand the most basic terminology that machine learning tools are using - recall and precision.
The definitions include some deceptively easy looking formulas:
Recall = True Positive/(True Positive + False Negative)
Precision = True Positive/(True Positive + False Positive)
There are many good explanations (e.g. Wikipedia article - Precision and recall), but I was thinking of an example that would help me to fully grasp these important concepts.
My example:
There are two candidates for a QA position who need to perform a technical task. The task includes testing an application that has 10 intentional bugs for them to find.
Candidate #1 finds two bugs (True Positives) and reports them. Using the formulas above
Recall= True Positive/(True Positive + False Negative) = 2/(2+8) = 0.2 (20%)
The eight bugs that were not found by the Candidate #1, are, in fact, true positive outcomes that were rejected. 20% is the fraction of relevant instances that have been retrieved over total relevant instances. It doesn't look as an impressive result, right? However, when we look at the precision (also defined as the fraction of relevant instances among the retrieved instances), Candidate #1 looks much better:
Precision= True Positive/(True Positive + False Positive) = 2/(2+0) = 1 (100%)
Candidate #1 has excellent precision!
Now, Candidate #2 finds all 10 bugs (True Positives) but also reports 10 bugs that are not true bugs (False Positives).
Recall = 10/(10+0) = 1 (100%)
Precision = 10/(10+10) = 0.5 (50%)
And now, we are facing a tough choice - which one of the candidates is better? Candidate #1 who did not find many bugs but is very precise, or Candidate #2 who finds much more bugs but also submits many false bug reports? Well, it turns out to be a typical problem in machine learning. Finding the balance between recall and precision is almost always a tricky process of adjusting and re-calibrating machine learning models.
How to apply all of the above to practical purposes of testing ORES models? Let's review what ORES articletopic is about.
Testing the model logic
The major challenge the Homepage Suggested edits project faces is - how to suggest edits to newcomers who have not yet edited anything?
ORES articletopic recommendations should be based on (1) selecting articles that have maintenance templates (indicating that some work needs to be done) and (2) such articles' content should match specific topics - e.g. "Physics", "Africa", "Biography (women)" etc. As a non-ORES example, you may enter in the search box - morelikethis:Cat hastemplate:Copyedit - you'll see articles that supposedly relate (somehow to Cat) and have the Copyedit maintenance template. The result might be sometime quite surprising.
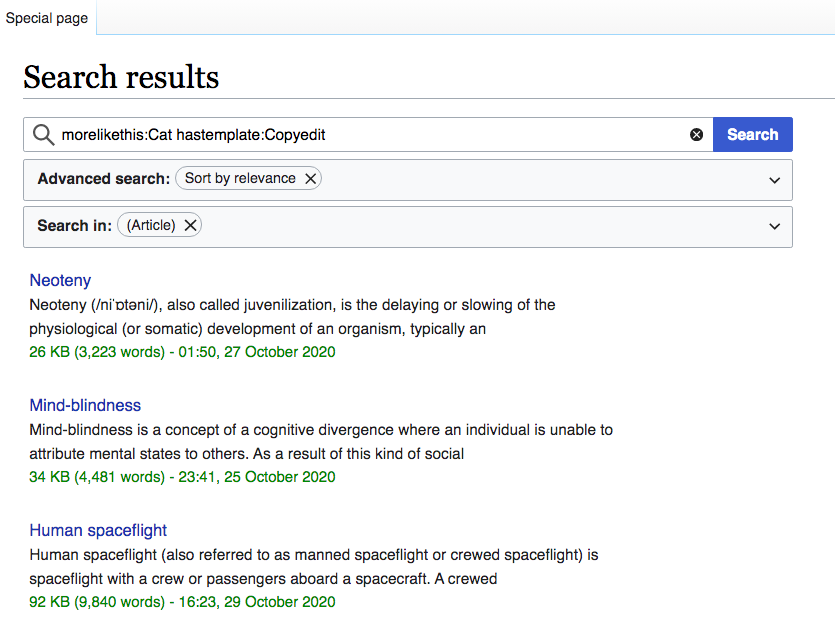
Would powerful AI (in our case ORES articletopic model) improve such searches? Before ORES articletopicmodel could start learning, the experienced editors should complete their own evaluation process - they should identify high-level topics (and map them to subtopics), then they should classify maintenance templates by the level of difficulty for new editors. These steps were done by our target wikis ambassadors who sampled articles with maintenance templates and created a list of high-level topics.
After that, ORES could start its AI magic and human QA testing could start too.
Here is the sample of data analysis (our knowledge of recall and precision comes quite handy here!). And just one more term to learn - a threshold. According to ORES/Thresholds, thresholds are trade-offs between the specificity (precision) and sensitivity (recall).
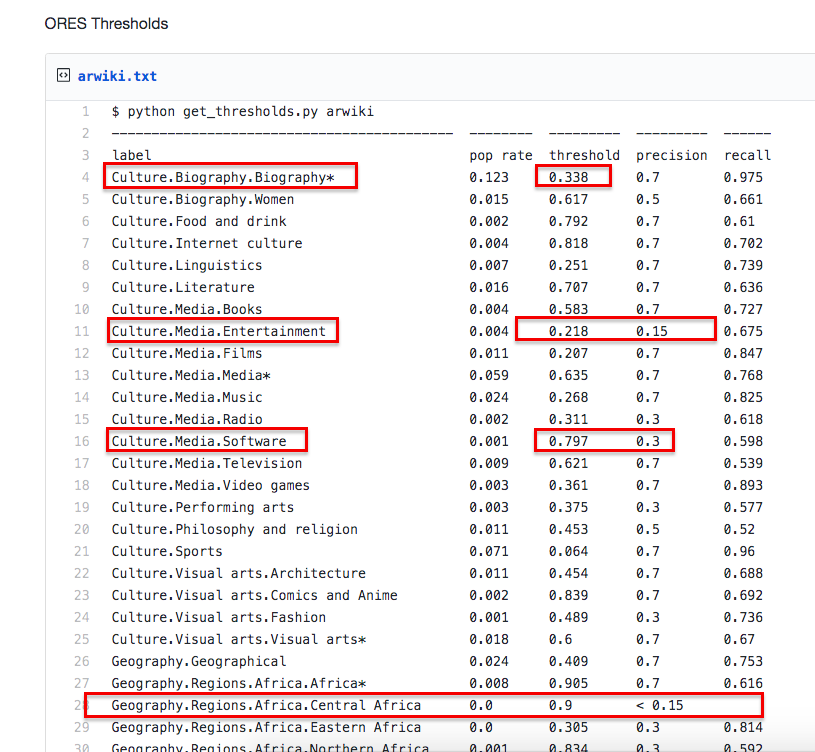
What should be tested? Looking closely at the sample you can see that some topics have lower precision and some topics have lower recall - there might be potential issues (articletopic algorithm might fetch non-relevant articles or some articles might not be included). The high precision/high recall values also should be checked to ensure that the result is, indeed, relevant.
And - voila! - it's easy now to come with a practical test plan - QA testing should watch out for
- highest/lowest thresholds
- low precision
- low recall
- other anomalies
When it comes to an article (with the great help from User:EpochFail) the scores can be easily viewed:
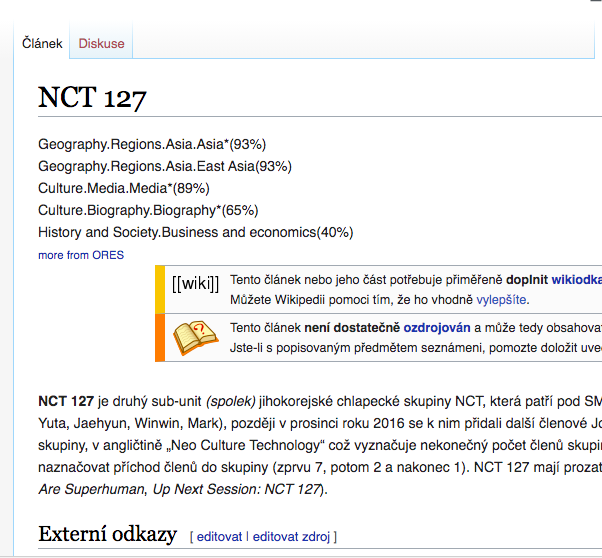
Then, the results of topic relevance (e.g.Culture.Biography.Biography*(65%) for NCT 127) can be compared to other similar (or higher/lower) scores to find out at which thresholds the article should be recommended as a good match for the topics.
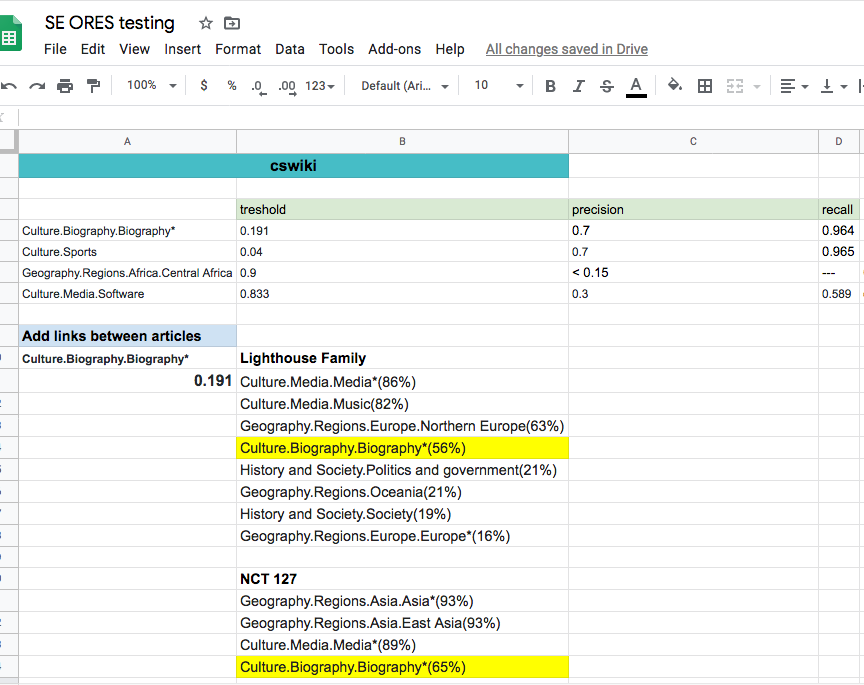
So having good understanding of fundamental terms and having tools for looking inside scoring data, the task of testing ORES articletopic becomes quite enjoyable. And the testing results have helped to adjust machine learning model to optimize new editors experience by providing them with meaningful tasks that match their interests and areas of expertise.
- Projects
- None
- Subscribers
- zeljkofilipin
- Tokens
Event Timeline
Thanks @Etonkovidova for very interesting article. I am not at all familiar with the topic, but I did find your explanation of recall and precision very clear.