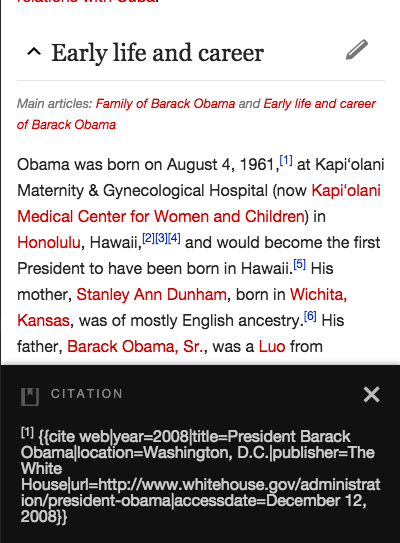
References are often created via templates e.g.
{{cite web|last1=Hicklin|first1=Aaron|title=The Gospel According to Benedict|url=http://www.out.com/entertainment/movies/2014/10/14/sherlock-star-benedict-cumberbatch-poised-make-alan-turing-his-own-imitation-game|website=Out Magazine|date=14 October 2014|accessdate=24 April 2015}}Currently the references returned via Cite::getStoredReferences return the raw wikitext for references.
This reduces the usefulness in serving them via the API for rendering purposes
Expected:
These should return parsed wikitext when an html option is passed.
Open questions:
- How can this be done in a performant way?
Demonstration:
Before:
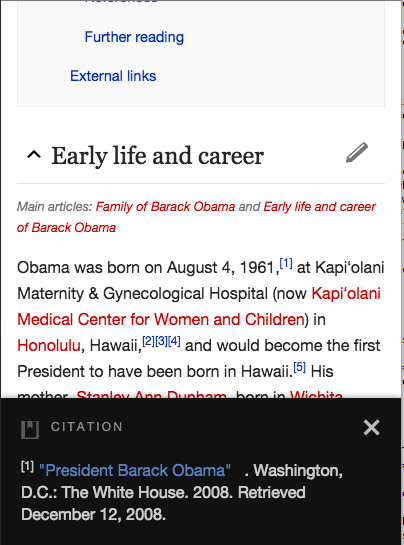
After: