Prior to committing to a framework and a WSGI server we decided to test the following servers with no framework: cherrypy, gunicorn, meinheld, and uwsgi. The list of servers is short and was chosen based on current uses, documentation, stack overflow resources, and community size. Suggestions for other servers are welcomed.
The servers ran on a Debian virtual machine with 2 CPU cores and 4 GB RAM. They were tested from another identical virtual machine using wrk, an HTTP benchmarking tool. The servers were tested with an increasing number of simultaneous connections, ranging from 10 to 500. Each test lasted 3 minutes and was repeated 3 times. The average of the results can be found in the graphs below. We chose to focus on the requests/second, latency, and errors. uwsgi errors were not included due to wrk misidentifying uwsgi responses as read errors.
More information on the methodology and code base can be found in the repository.
Results
WSGI container/server performance
 | 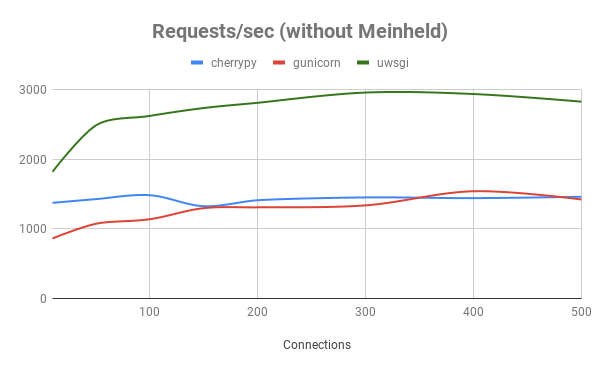 |
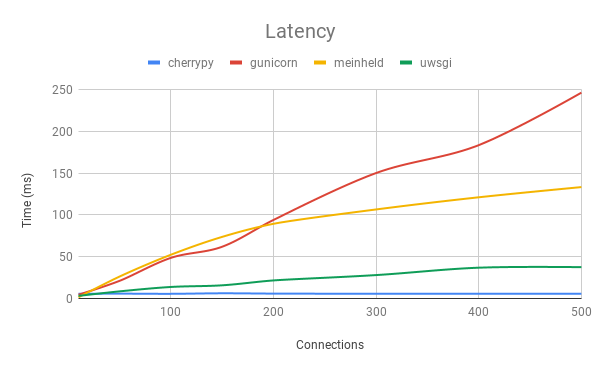 | 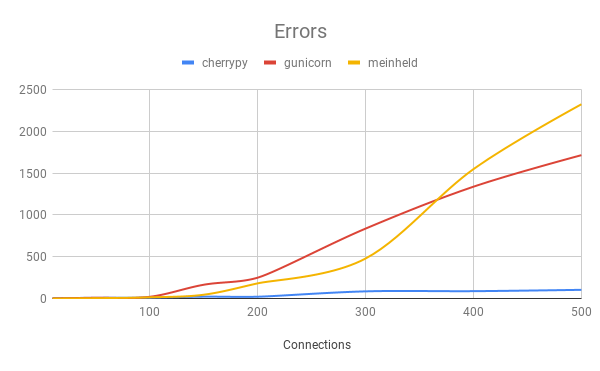 |
Python framework performance
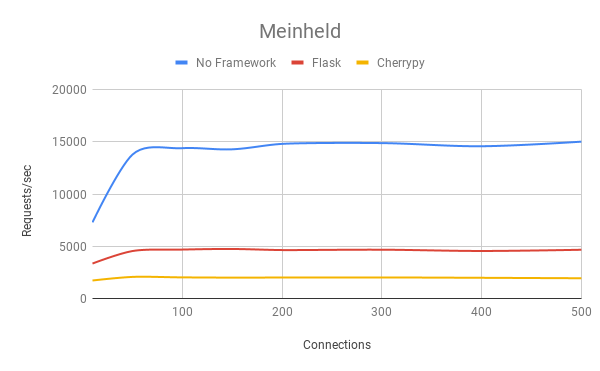 | 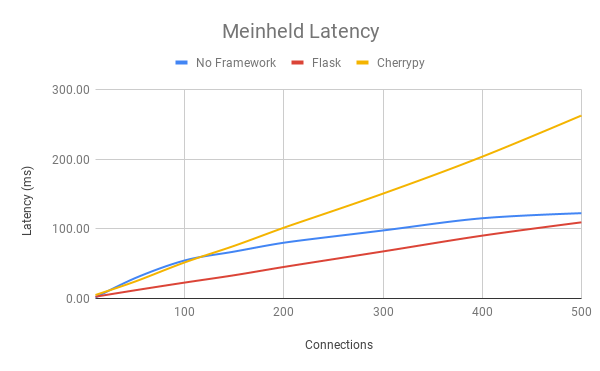 | 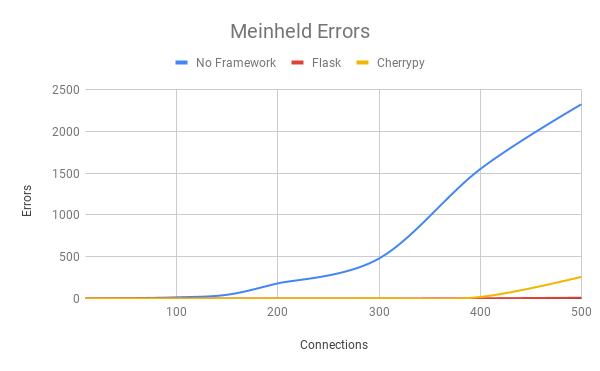 |
To better understand the performance costs of frameworks the tests above were rerun using the same environment but with two popular frameworks, Flask and Cherrypy. Suggestions for other frameworks are welcomed.
The graphs above compare meinheld’s requests/second, latency, and errors in Flask, Cherrypy, and without a framework. Results for the other servers can be found in the spreadsheet.
See also: T221292: Establish performance of the session storage service