Description: https://wikitech.wikimedia.org/wiki/WMDE/Wikidata/SSR_Service
Timeline: 2019-01-31 would be fantastic. 2019-02-28 would be great. We will start to get worried if we don't have the service by end of March 2019.
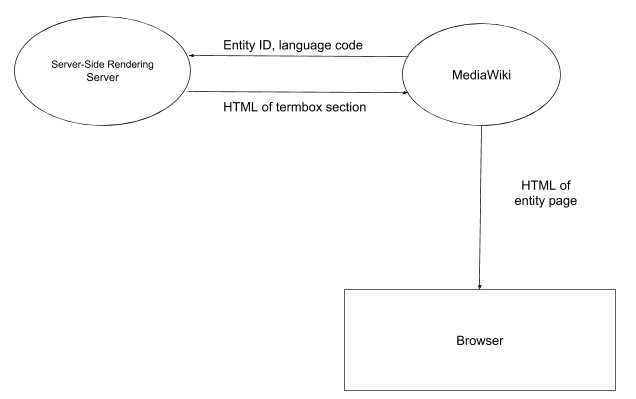
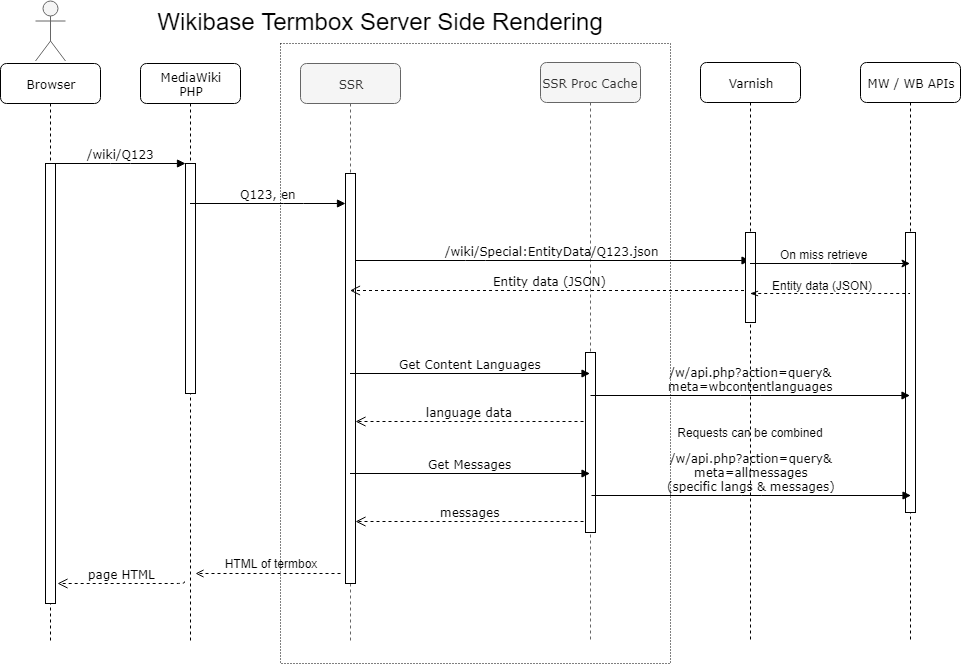
Diagram:
Technologies: nodejs
Point person: @WMDE-leszek, @Addshore as a backup (especially deployment topics)
Source code: https://github.com/wmde/wikibase-termbox, move to gerrit to happen latest in early Jan 2019.
Load Details
The initial responsibility of this service will be the rendering of the term box for wikidata items and properties for mobile web views.
Currently wikidata.org gets no more that 80k mobile web requests per day (including cached pages, and non item/property pages).
If we were to assume all of these requests were actually to item and property pages that were not cached this would result in this SSR service being hit 55 times per minute.
(In reality some of these page views are not to item or property pages, and some will be cached) so we are looking at no more than 1 call per second.