The captchas used on Wikimedia sites are not working very well: they obstruct humans and do not keep out bots well enough, burdening volunteers doing anti-abuse work. Many tasks have been filed about it over the years; this is intended to be a tracking task and a high-level overview of the whole sorry situation, written in the hope that it can influence resourcing choices at the WMF.
tl;dr
| human failure rate | major accessibility issues | spambots kept out | spambots missed |
|---|---|---|---|
| 20-30% (estimated) | visual only; English only | 66-99% (estimated) | ~2.000-10.000 / month |
Our captchas are bad at letting in humans
There is no easy way to separate good (human) and bad (bot) captcha rejections, but per T152219#3405800 a human failure rate between 20-30% seems to be a reasonable estimate. (Also reinforced by mobile app data collected some years ago, which was on the the high end of that range.) That's extremely high. Furthermore our captchas assume you can read (somwehat obscured) English text; users with visual impairments have no way of getting through them at all (T6845: CAPTCHA doesn't work for people with visual impairments, T141490#3404526; arguably, this could cause legal compliance problems as well), nor do users who cannot read or type Latin scripts; and the characters are sufficiently distorted that people who don't speak English are at a disadvantage recognizing them (T7309: Localize captcha images).
| example of current captcha |
|---|
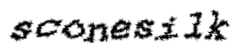 |
The signup page has a fallback link for requesting an account, but it's entirely up to the volunteer community of the wiki to implement that process. Many larger projects direct users to OTRS, and respond to account creation requests arriving there, but the process is hardly user-friendly (e.g. enwiki's account request page welcomes you with this wall of text); smaller projects often don't have the capacity for a dedicated workflow (simple.wikipedia for example just directs users to the village pump).
We are also fairly unsophisticated about how we use captchas (T113700: one CAPTCHA (per action) should be enough to confirm humanity/ smart enough bot) so for some common new user workflows like adding external links the user will get multiple captcha challenges repeatedly.
Our captchas are bad at keeping out bots (and volunteers pay the price)
The captchas keep out the stupidest spambots (which are the majority of spambots, of course; for every captcha pass, including humans, we have about two failures and 100 displays); experimentally disabling them has caused instant spam floods. But they are ineffective against even just slightly sophisticated spambots, even non-Wikimedia-specific ones: per the investigations in T141490 and T125132#4442590, the captchas can be broken with off-the-shelf OCR tools without any training or finetuning. Empirically, thousands of spambots need to be manually blocked and cleaned up after by stewards every month (per T125132#3339987), which is a huge drag on volunteer productivity (and arguably it is unfair and somewhat abusive to rely on volunteers' manual effort for tasks like that). The people doing this are already exasperated; they regularly call for help (see e.g. T125132 or T174877, there's many more) but are mostly ignored.
Occasionally, a more intelligent spambot completely overwhelms our defenses, and we just disable new user registration on that wiki and wait until they get bored and stop. (E.g. T230304, T212667) If someone did that with the intent of disrupting Wikipedia (as opposed to making money via spam), this is probably one of the easier attack vectors today.
Improvements are held back by technical debt
There have been many discussions about improving things, but they went nowhere because
- the captcha code (ConfirmEdit extension) is one of the older and more gnarly parts of the codebase, and hard to work with;
- the captcha infrastructure is essentially unowned (the maintainers page puts the extension under the Editing team, but that does not reflect reality, and does not really make sense anyway given that team's focus on editing interfaces and client-side code);
- we mostly lack the infrastructure for measuring captcha efficiency, so even though some of the proposed changes are relatively easy to do, we'd have to rely on intuition and technical experience instead of data.
Past proposals / efforts
(See also mw:CAPTCHA for various past discussions, and the continuously updated captcha page of the W3C accessibility group.)
Incremental improvements
The type of image distortion we are doing is not well-chosen - looks fuzzy and hard to read to a human but not particularly problematic to a bot since the characters are easy to separate and their shape is barely changed. There are simple alternatives which are easier to read but harder to process programmatically (see T141490 and T125132#4442590 (restricted task) for various proposals, and Bawolff's tool linked there): compare the current captcha (33% success rate of breaking it with off-the shelf OCR) with this proposal (<1% success rate, very easy to read).
A significant amount of effort was put into researching image processing options which would probably improve efficiency with both humans and bots, but none of it was put into practice - probably because of the lack of measurement infrastructure mentioned above.
There was also discussion about matching the site's language (T7309) which should be relatively easy (although that can be famous last sentence territory when it comes to i18n) but that has not happened either.
A more speculative proposal was {T231877} (restricted task) .
Third-party services
Detecting / rejecting automated abuse is a hard task, and (at least when done with software) well outside Wikimedia's core competency; it would be natural to find someone else who is specializing in it (such as a captcha service, an identity provider, a proof-of-work scheme, or some sort of trust / reputation source) and outsource the task to them, but this runs into problems with privacy and loss of control. T215046: RfC: Use Github login for mediawiki.org, while not exclusively focused on the captcha problem, has a good overview of some of these problems.
reCaptcha, especially (being the market leader in captchas) has been often proposed and rejected (see e.g. T174861).
Google has recently suggested, as part of its privacy sandbox, a Trust Token API where cryptographically signed attestations of trustworthiness can be issued and verified in a way that prevents linking the two. In the long term that could be promising, but browser and captcha provider support is lacking so far (see T281397: Test trust tokens as a captcha alternative for Wikimedia).
Recognition tasks
Real-world recognition tasks are popular for captchas: they come naturally for humans but too unpredictable for captcha-breaking software. Google's reCaptcha used OCR, then numbers on street signs, then traffic objects (cars, lights etc); Microsoft's now defunct captcha had users tell apart cats and dogs. These captchas also often have the benefit that the solved task has some real-world value (e.g. used to train machine learning systems or transcribe books).
The problem with real-world tasks is that unlike artificially generated challenges, the captcha system does not know the correct solution (unless you can rely on being far better at artificial intelligence then your adversaries, which is not the case for us). Usually this is solved by some sort of cross-verification: have the user answer two questions, one will be compared to previous answers and used to accept or reject the answer, the other will be (if the first answer was correct) assumed correct, stored and used to verify future users. This introduces significant complexity (you need to store a pool of verifiers and manage the size the of the pool against fluctuating user signup rates). Also, depending on the task they might make the disparate impact on non-English / non-Western wikis worse.
Past proposals along these lines include T34695: Implement, Review and Deploy Wikicaptcha (use Wikisource OCR tasks for captchas) and T87598: Create a CAPTCHA that is also a useful micro edit (T64960: Prototype CAPTCHA optimized for multilingual and mobile also has some related discussion in the comments).
Behavioural analysis
Bots interact with a website differently than humans; a captcha system can try to exploit this. Methods range from simple honeypots and Javascript capability checks to analyzing browsing patterns (the v3 reCaptcha supposedly does something like that) and mouse/keyboard dynamics. The benefit of this approach is that when it works, it is completely invisible to the user; also, less impacted by language and accessibility issues. On the other hand, the simpler methods are only good against the most naive spambots, and the complex ones are hard to design and often come with privacy challenges (e.g. sufficient amounts of mouse/keyboard dynamics data can be used for biometric authentication of the human behind an account).
T158909: Automatically detect spambot registration using machine learning (like invisible reCAPTCHA) was an Outreachy project to investigate bot identification via mouse/keyboard dynamics, but was far insufficient for the scope of the problem.
Another option that has been discussed vaguely is pushing the captchas to a later point (e.g. first edit instead of registration) so there is more data to work with (e.g. for ORES or some similar machine learning based edit scoring mechanism).
Better spam fighting tools
Improving manual spam prevention and cleanup tools is probably a low-hanging fruit. While it does not solve the problem, it reduces the impact on anti-abuse volunteers by offering them better tools. It might potentially reduce the incentive for spamming too - in the end, captchas can always be beaten, the only question is price: human captcha solvers typically cost around $0.001 per captcha, the only reason to use captcha-breaking bots is to do it cheaper than that. The spammer then has to recoup the costs by whatever value they can extract from the spam edits, which will be reduced by better antispam tools. So if we make captcha breaking costlier by using harder-to-automate captchas, and simultaneously reduce the value obtained from breaking captchas via better anti-spam tools, at some point spamming ceases to be profitable.
This has been a neglected area so there is probably a lot that could be done here with relatively little effort - usability and capability improvements to power tools like AbuseFilter and blacklists, semi-automated mass blocking / rollback / deletion / hiding / blacklisting, better monitoring (e.g. feeds of successful and failed link insertions), flagging suspicious accounts on captcha / AbuseFilter rejections...
Some related past discussions: T181217: Deploy StopForumSpam to the Beta Cluster, T100706: Revamp anti-spamming strategies and improve UX, T139810: RFC: Overhaul the CheckUser extension
The Anti-Harassment team is working on a related project, T236225: [Epic] CheckUser 2.0 Improvements ; and also on T166812: Epic⚡️ : User reporting system which has a different primary use case but might have overlaps.
More flexible captcha logic
Currently we present the same captcha challenge to all users; once we have multiple captcha mechanisms, or captchas with an adjustable strength factor, at our disposal, there are many opportunities for doing better than that: we could automatically deploy harder captchas based when registrations spike or easier ones during recruitment campaigns, we could show harder captchas for more suspicious edits etc.
Some related past discussions: T20110: Define AbuseFilter consequence to display a CAPTCHA, T176589: Offer a hook manipulating the need for solving captchas/T189546: Add a hook for altering captcha strength in FancyCaptcha. These are simple in theory, but the ConfirmEdit codebase is very legacy and would probably need significant refactoring first. (On the other hand it is not too large...)
There have also been recent discussions (end of 2019) between the Security-Team and Platform Engineering regarding potential paths forward for improving current production captchas (see notes here; see also the earlier captcha initiative proposal from the Core Platform team).