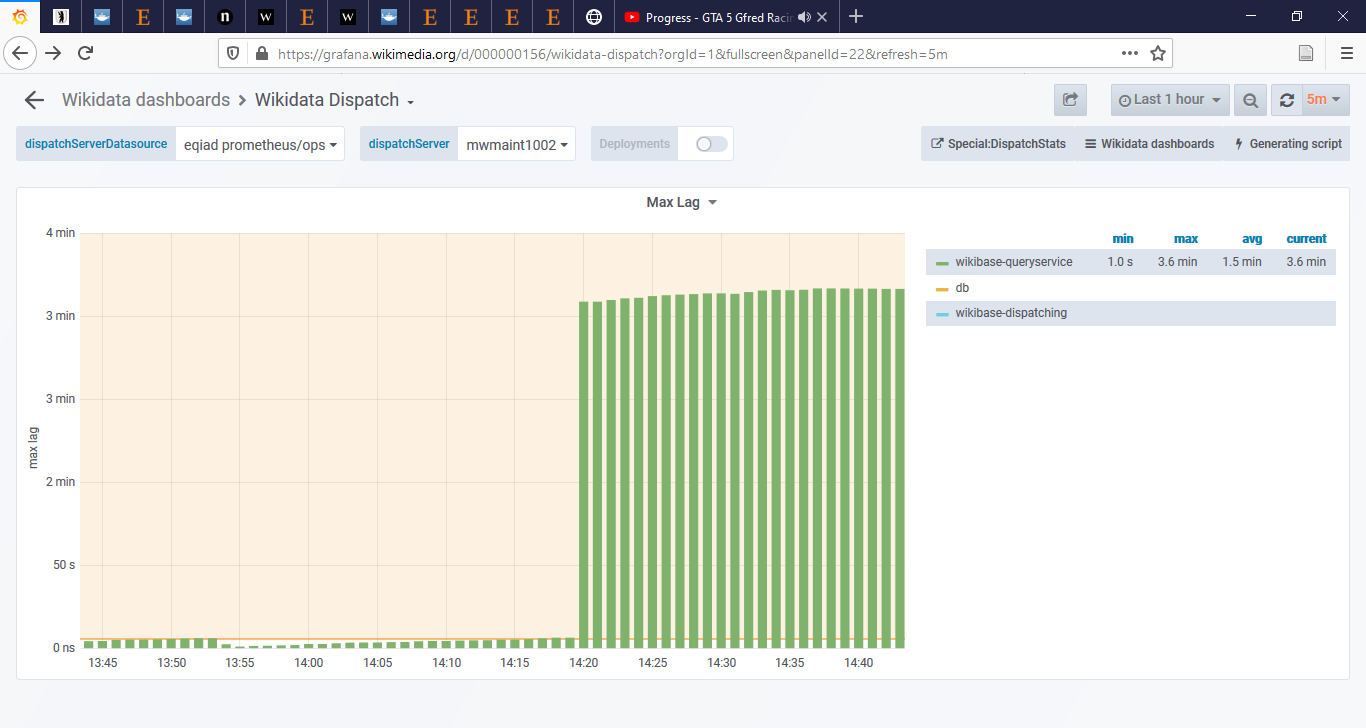
Since Jan 20, 2020 the wikidata-queryservice lag is repeatedly climbing over 5s, as shown in https://grafana.wikimedia.org/d/000000156/wikidata-dispatch?orgId=1&refresh=1m&fullscreen&panelId=22&from=now-7d&to=now
This delays bot runs, making their duration impredictible, which in turn makes interactive runs very hard, if not impossible