inteGraality has never been particularly fast, but overall this is understandable because it does a lot (a NxM SPARQL queries [with N=#groupings and M=#properties]).
The queries (aka looking glass) feature, however, does comparatively very little: using Pywikibot to read the find the wikipage, read the config from the template, generate hyperlinks to two SPARQL queries, done. Yet, it can be excruciatingly slow (as reported by @Dominicbm among others).
I have reproduced this locally, throwing in some Jaeger based distributed tracing. Here is a trace:
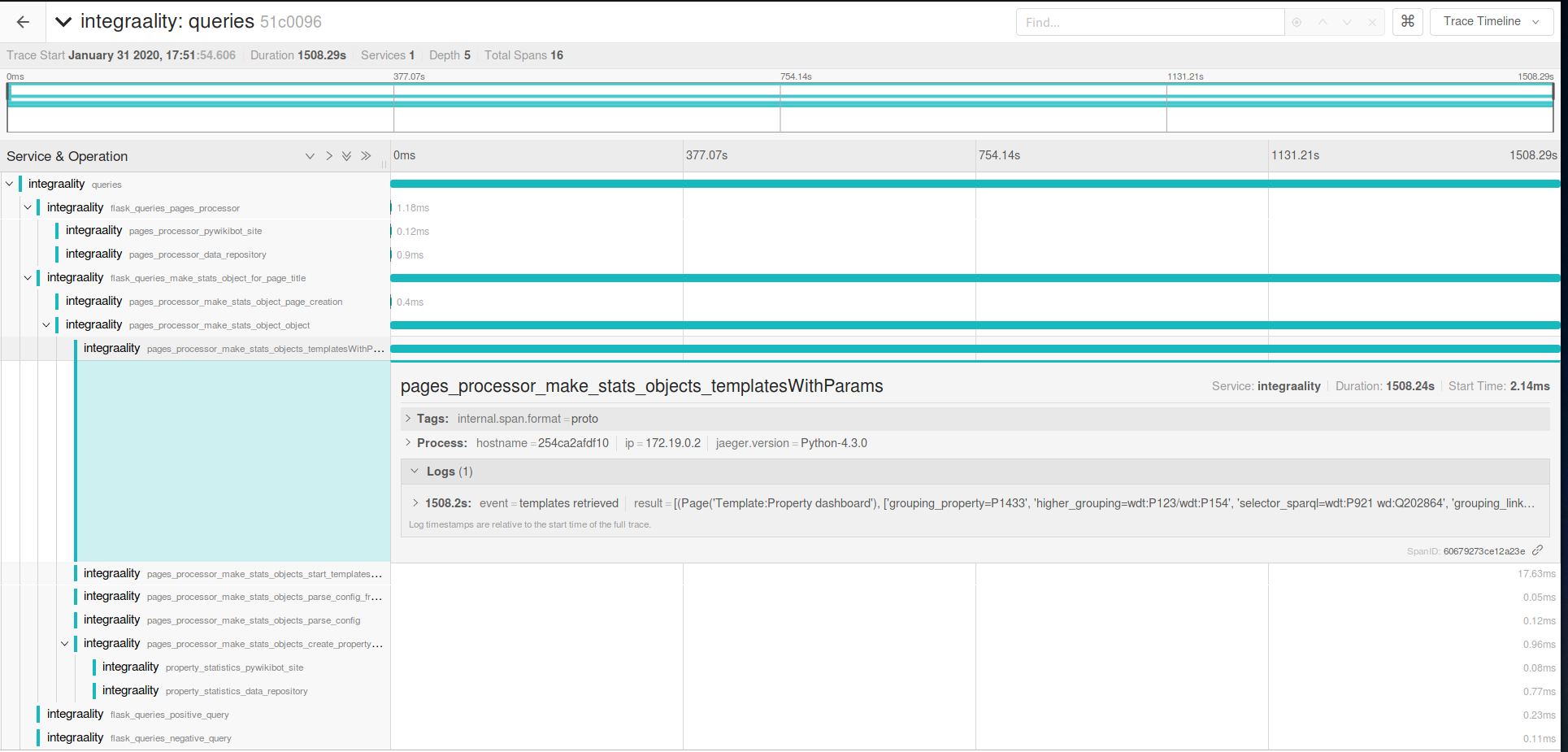
Integraality spends less than a millisecond creating the site object, or looking up the data_repository, or creating the pywikibot.Page object… then spends 25 minutes doing page.templatesWithParams(). Admittedly, that page has some 500+ templates − so I tried again on an 'empty' integraality page, with only two templates − 28 minutes.
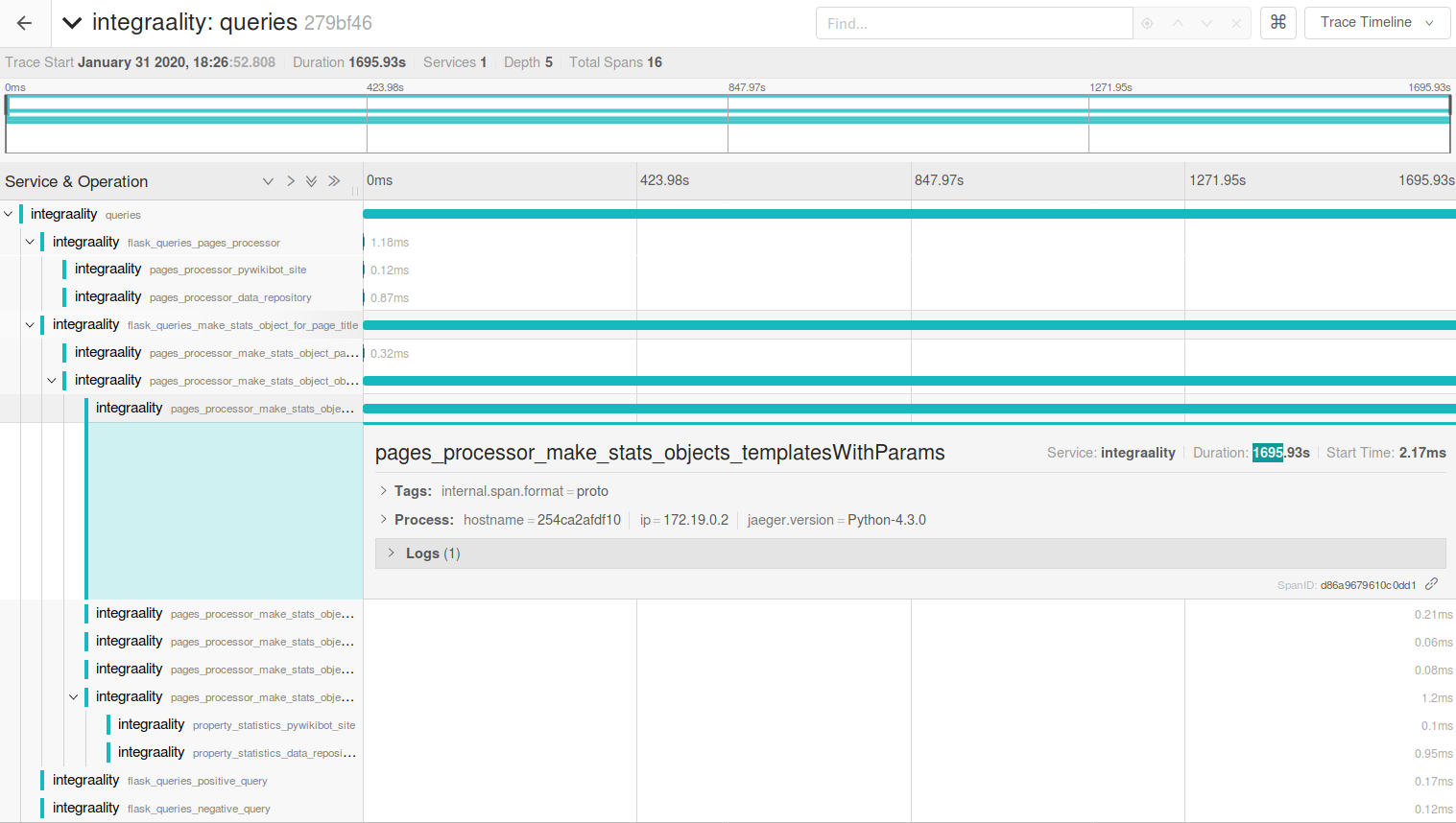
I really don’t see what I could be doing anything wrong here.