I rebooted it once due to this behavior and didn't see anything obvious so I left it in service and it happened again shortly thereafter. @faidon depooled on palladium and I did a hard reboot.
Suspect hardware issue
| • chasemp | |
| Sep 24 2015, 6:10 PM |
| F2631696: Screen Shot 2015-09-24 at 1.28.31 PM.png | |
| Sep 24 2015, 6:33 PM |
I rebooted it once due to this behavior and didn't see anything obvious so I left it in service and it happened again shortly thereafter. @faidon depooled on palladium and I did a hard reboot.
Suspect hardware issue
I don't see anything damning in dmesg and I can't find anything that is narrowing down a hardware issue.
The best though i have is MEM used seems to have spiked before the last crash:
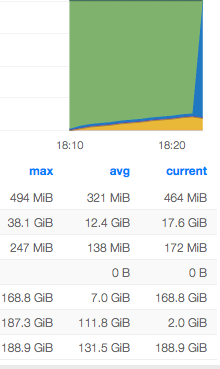
It jumped from 3.8 G used to 168G in what seems like one polling cycle (60s I think) and then diamond stops reporting in and the server becomes unresponsive. It was also somewhat indicative of resource decay as I could telnet to varnish from LVS for a bit after ssh was hanging and icinga was freaking out and then finally that was taken out too. I don't see any OOM stuff happening though.
I committed the depool on palladium for LVS, and also depooled it in confd for cache<->cache stuff. It's crashed twice in recent history now, so there's clearly a hw problem we should address here before turning it back on.
See also T113184 for previous crash. Apparently it crashed again this morning (while still depooled). Will downtime it in icinga and start tracking down what the real problem is here in this ticket.
Checked the serial console, and it's showing this:
Alert! System fatal error during previous boot
PCI Express Error
Uncorrectable Memory Error
Management Engine Mode : Active
Management Engine Firmware Version : 0002.0001
Patch : 0005
Build : 006D
Strike the F1 key to continue, F2 to run the system setup program@Cmjohnson can you take a look at this machine locally when you get a chance?
A pull of the idrac log revealed this error
Record: 50
Date/Time: 09/25/2015 02:12:31
Source: system
Severity: Critical
Description: Multi-bit memory errors detected on a memory device at location(s) DIMM1,DIMM2,DIMM3,DIMM4,DIMM5,DIMM6,DIMM7,DIMM8.
So mem errors on all DIMMs, and the other one on the console about the PCI bus. Bad CPU? Bad board?
Steps Taken
-removed all of B side Dimm and cpu
-cleared log
-rebooted
-Swapping cpu2 with cpu1 and booted without issue
-Added B side Dimm back and rebooted and kernel loaded with OS and system is back up.
Let's see if the problem returns but right now I do not have anything definitive to report to Dell
I've left cp1046 depooled the past several days since @Cmjohnson did the hardware work above. So far it's been stable under no load. Today I've wiped it's long-term storage again (in case of missed purges, or corruption from the previous crash) and re-pooled it to see how it fares under load. Will close this if it makes it into early next week without incident.