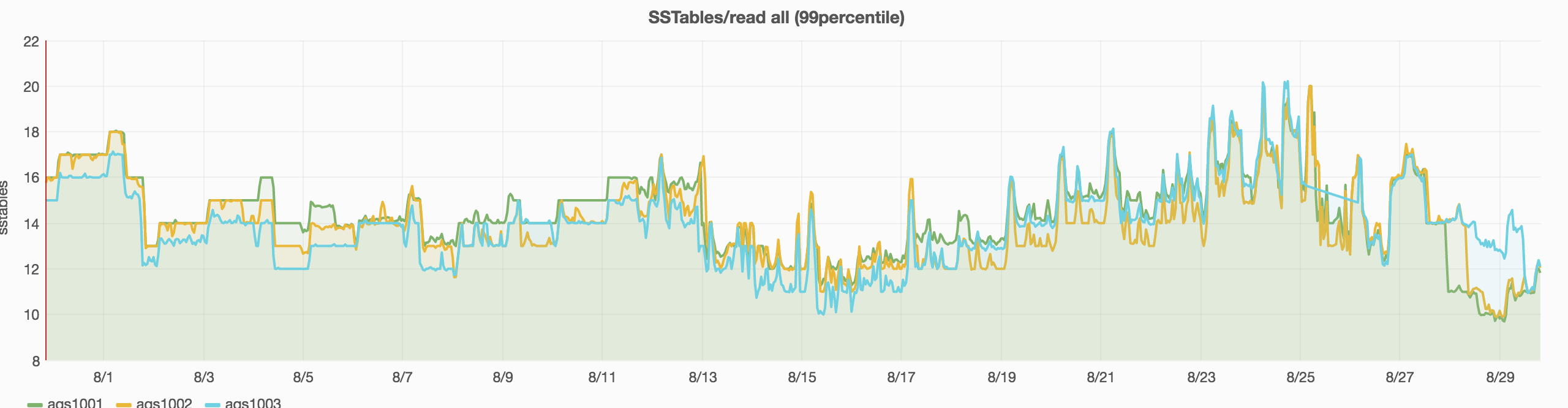
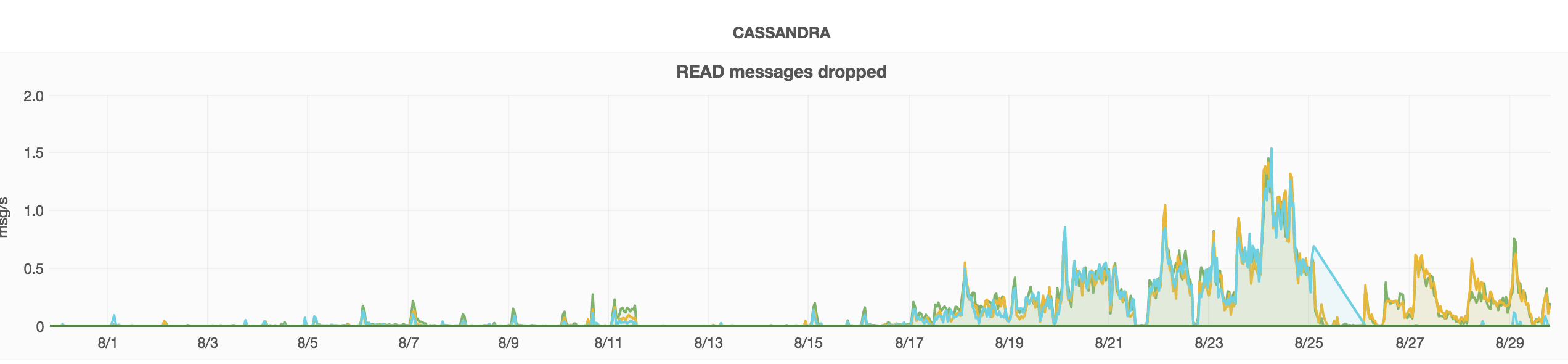
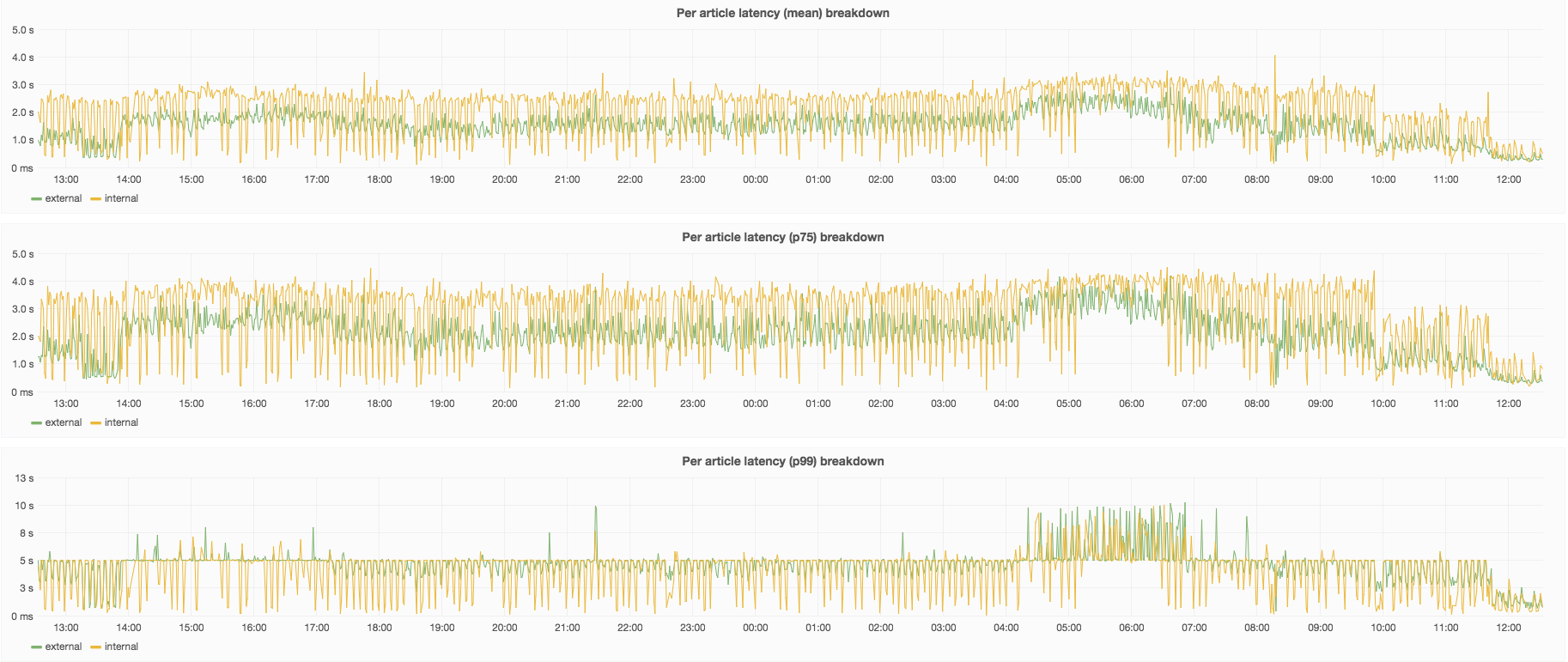
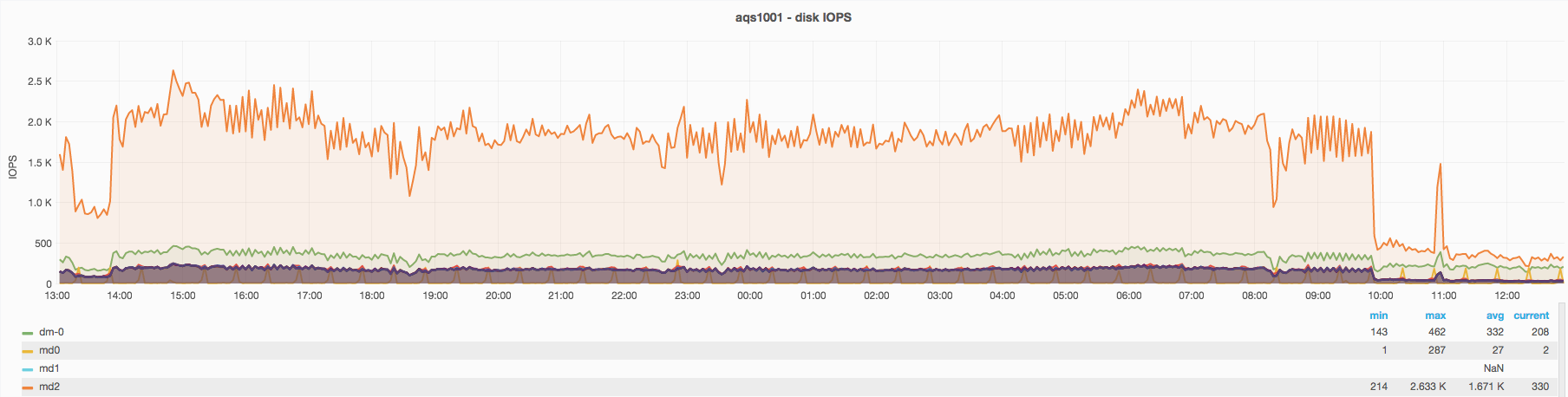
The Cassandra READ timeouts increased a lot from Aug 17th causing also an increase in AQS 503:

From the logs it seems that we are experiencing again a system auth timeout issue. It should have been resolved with our latest patches, namely:
- increasing permissions_validity_in_ms to 10 minutes
- switching Restbase to use the 'aqs' username rather than the 'cassandra' one (admin requiring QUORUM instead of LOCAL ONE)
There seems to be no evident reasons why this started all of a sudden, but we'd need to figure out what caused it.
https://issues.apache.org/jira/browse/CASSANDRA-8194 could be useful but doesn't explain the start of the issue.