User Details
- User Since
- Nov 26 2014, 3:04 AM (491 w, 3 d)
- Roles
- Disabled
- LDAP User
- Nuria
- MediaWiki User
- Unknown
May 21 2023
This data was released. Due to various technical factors, there are three distinct datasets:
https://analytics.wikimedia.org/published/datasets/
This data was released. Due to various technical factors, there are three distinct datasets:
https://analytics.wikimedia.org/published/datasets/
May 4 2023
Feb 22 2023
Jan 30 2023
Sep 1 2022
This is a bot that was crawling this page and realized that it was detected as a bot and it shifted its pattern a bit: (notice these are automated pageviews a while back)
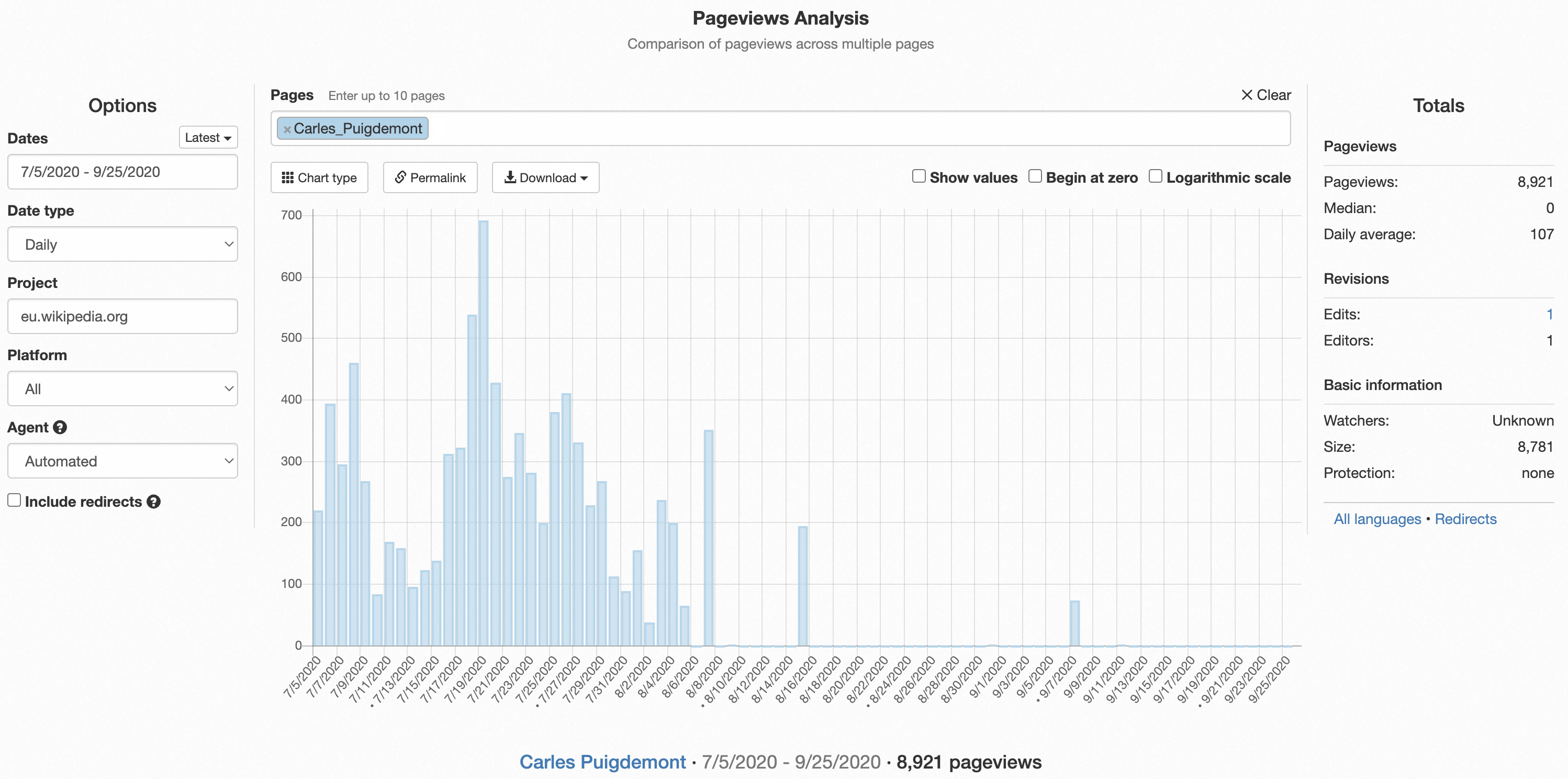
Nov 2 2021
New developments in this are of interest: watermark change data capture framework from netflix that aims to do what this task is about, streaming data from source A to source B taking into account an initial snapshot: https://arxiv.org/pdf/2010.12597v1.pdf
Oct 11 2021
Love openDP @Htriedman
Jun 18 2021
These path is road less travelled it seems, but that is not a reason not to attempt it.
Nice
Jun 4 2021
It might also be possible to do a differentially-private count on a single machine within the Analytics cluster (likely on stat1007, which I think has a lot of RAM). This could be either with Privacy on Beam >(using the local runner) or with Google’s Java/Go implementations of DP.
Part of this task is to make data releases of this type part of the cycle of data releases at WMF so I do not think we should pursue the option of treating this project like a one off data release, rather we should think of it running it as any other data flow as a core requirement.
May 26 2021
My thoughts on the proposals:
May 14 2021
There is no third party (to our knowledge in the last 7 years) that is ever used this system so makes sense to deprecate it via notification.
May 6 2021
May 3 2021
what it would take to migrate some of this to the cluster where the Apache Spark runner could be tested
We probably do not want to install beam on the cluster just for this experiment so can we use jupyter rather and run beam on python? https://beam.apache.org/get-started/quickstart-py/
Apr 20 2021
User is more standard and has stronger guarantees but more complicated
Also, our privacy policy prevent us from keeping data at the user level, so DP notions that are user centric will not really serve our use case. I doubt they serve the case of any service you can use while not authenticated.
Apr 16 2021
Apr 2 2021
Had more time to review this and appreciate the coolness of this: "I apply a flexible threshold in the tool based on an approach from Google where you calculate the likelihood that the real datapoint is within X% of the noisy data point and threshold based on that. So in the tool, noisy data points that are calculated to have less than a 50% chance of being within 25% of the actual value are greyed out. The 50%/25% parameters can be adjusted but are a reasonable starting place"
Jan 21 2021
in a setting like the one you describe, what would the attacker know, and what would they be trying to find out?
Sorry let me clarify: what would be known to an attacker is the exact pageviews per project per article, see: https://dumps.wikimedia.org/other/pageview_complete/readme.html
An attack might try to remove the noise in order to find the pageviews per article, per country.
Jan 20 2021
Parking some thoughts from my conversation with @Isaac after his good work this past couple weeks.
Jan 19 2021
Nice @Isaac need to get back to this now that https://phabricator.wikimedia.org/T269256 is closed
cc @Slaporte that blogpost about technical measures to detect censhorship is been published
Jan 16 2021
@srodlund I see, how about (probably a reworked version of)
Jan 15 2021
@srodlund in mobile specially the initial paragraph : "The act of detecting anomalous events in a series of events (in this case a time series of Wikipedia pageviews) is called anomaly detection. The anomalies we are looking for are sudden drops in pageviews on a per-country basis." looks, I think, much too prominent, can we remove entirely so blogpost starts at "About four years ago"
"derivative of logo" sounds good. No rush on publishing it whenever works for you.
Jan 12 2021
Ping @srodlund
Jan 6 2021
@srodlund I think it is almost final! Accepted all your corrections and elaborated a bit on the conclusion. Please take a second look. Let me know if the tables are to be translated into images (or HTML tables) or how do you prefer to do that.
Jan 5 2021
Thanks for the fast response!
Jan 4 2021
Dec 18 2020
@srodlund perfect, that gives me next week to finalize the text. The new year sounds great.
Dec 2 2020
@Aklapper I assigned to myself again after my account was re-activated
Nov 27 2020
Done both things, many thanks @Reedy
Super thanks!
Nov 18 2020
To keep archives happy, WMF did teh work of productionizing these scripts: https://wikitech.wikimedia.org/wiki/Analytics/Data_quality/Traffic_per_city_entropy
Nov 12 2020
@JAllemandou Given that user fingerprinting on pageview_hourly data is not effective (and if it were to be it would be a problem) I *think* I am going to center my efforts - when, ahem, I can get to this - in other privacy 'units'
Nov 7 2020
This is WIP. please see: T207171: Have a way to show the most popular pages per country
Nov 6 2020
Thanks @TedTed for all these pointers, on my end I need to digest all this info before I can get back to you, others here might have more questions.
We have IPs in a temporary dataset, called pageview_actor that feeds into pageview_hourly, so that's where we'd get the fingerprint Joseph is talking about. We could insert two steps in between these datasets,
Nov 5 2020
Say that field has value 5, does it means that the page had 5 different views, potentially from 5 different users (but all with the same country, user_agent_map, etc.)?
Yes, exactly, same country, same (broadly) user agent and same article.
This approvals are now handled by @Ottomata
@TedTed Super thanks for chiming in
Oct 29 2020
Oct 28 2020
Code merged now, when the entropy counts are re run alarms for may18th will be resend.
Oct 27 2020
@Dzahn : i do not think so, he should be removed from LDAP
Oct 23 2020
done!
NDA signed now but I do not have access to https://phabricator.wikimedia.org/L2?
Also, @Rmaung please take a look at https://wikitech.wikimedia.org/wiki/Analytics/Data_Access_Guidelines and ask any questions you might have about it on task
Oct 22 2020
if this is not super urgent i can work on it on my volunteer capacity.
Oct 21 2020
I would implement the daily "top" 1st and once that is in place I would add the monthly job, given the very different amounts of data needed for both a different strategy might be needed for the second one.
A daily release to provide quick information for editors interested in very targeted editing. I suspect that this could even be just a ranking of most popular articles that meet the privacy thresholds without including any raw count data
Nice, +1 to this idea
I found differences of <0.1% for recent months and <0.3% for older months. I think that's acceptable.
Oct 20 2020
For faster resolution of permits issues add SRE-Access-Requests to ticket, that way the persosn on clinic duty will get to work on it soon after ticket is filed. I understand that process is a bit confusing but permits to access the prod infra (including analytics clusters) are handled by the SRE team at large.
If the intent is to decide whether all errors are from same user you can send the number of errors for that session of that type and that would tell you the piece of info you want to know.
Flushing this a bit more. The number of errors for a device does not need to be per session but rather can be a tally:
We can keep data for longer than 90 days that has no identifying fields. Just need to submit a changeset that lists those fields. Please take a look at docs: https://wikitech.wikimedia.org/wiki/Analytics/Systems/EventLogging/Data_retention
Oct 19 2020
A hashed IP would still tell you how many IPs are involved, without revealing any individual IP
For it to be truly not revealing on an 2^32 space it will probably needs to be salted.
@elukey to create kerberos credentials
Oct 16 2020
So, if you just say "this number is too low to be displayed" , I don't think that anyone will complain
This is actually very useful info, thank you.
Oct 15 2020
Have in mind that per population data is not necessarily needed (it will be great to have at some point but it feels like scope creep in this task).
I think that CKoerner_WMF.'s works fine with editors as well: "When Bethany started editing Malagasy Wikipedia in 2014, there were no Wikipedia editors in her home country of Madagascar" so I do not really see a strong use case for edits versus editors in this case
Adding @Isaac cause I think he can probably be a good person to help to explore more than a simple bucketization solution might be needed.
We talked about doing some data analysis to quantify the issues with privacy and country splits. As we spoke we need to quantify the identification risk, an article with 1 pageview in "Greenlandic-language Wikipedia" might carry an identification risk of 1/55,000 (55,000 being the population of Greenland) and article in Malasyan in San marino might have an identification risk of 1/5 (5 citizens with malsyan names in San Marino) so it is not the "number of pageviews" that defines the identification risk but rather "possible population from which this pageviews are drawn"
Moving to kanban and @razzi to work on this.
Oct 14 2020
Pinging @JAllemandou in case he can think of any reason why we should leave these fields, giving precision.
@CKoerner_WMF just so you know this data has been publicy available for now about a year, the task in question is to visualize it via Wikistats.
Oct 13 2020
This is scheduled to be added to wikistats Q2 2020 (Sep to Dec)
@jwang I think @Mholloway might be able to help given that this seems to bean instrumentation issue.
Oct 12 2020
Sum up: The timeseries of entropy of os_family per access_method works well to as a data quality timeseries for 'mobile web' (see green line in plot above) and 'mobile app' (orange line). For desktop, the timeseries is a lot better from April onwards when filtering of automated agents is deployed (see https://wikitech.wikimedia.org/wiki/Analytics/Data_Lake/Traffic/BotDetection#Why_do_we_need_more_sophisticated_bot_detection). The blue line in above graph starts to clearly oscillate with a weekly cadence from April onwards. Now, as it can also be appreciated on above graph, there are still spikes due to undetected bots. Those are bots that elude our detection for a number of reasons (they are real well spread geographically or their effect on pageviews is not as high as our thresholds).