While turning up the new GTT links, I ended up in a catch 22 situation for the eqdfw-knams OSPF metric.
The eqdfw-knams needs have a lower metric than the current primary (codfw-eqiad + eqiad-esams) links so traffic from codfw to esams prefer that link.
At the same time, have a higher metric than the current primary (eqiad-esams - codfw-eqiad) links so traffic from eqiad still prefers the direct link.
So:
840-320 < x < 320+840
520 < x < 1160
But if the primary eqiad-esams link goes down, it's backup has a metric of 1820 (vs. 840), this is due I think to the current policy to add a weight of 1000 to the backup link.
This means, to respect the same conditions stated previously, the metric now have to be:
1820-320 < x < 1820+320
1500 < x < 2140
The low hanging fruit if we only focus on that part of OSPF metrics is to lower the backup eqiad-esams link's metric.
For example I used:
Primary eqiad-esams: 880
Backup eqiad-esams: 968
880-320 < x < 320+880
560 < x < 1200
With primary eqiad-esams down:
968-320 < x < 968+320
648 < x < 1288
So a metric of 1089 for eqdfw-knams works.
Looking into that issue, I drew a map of all our links with the current metrics.
I noticed that in a few places the current metrics don't match the latency anymore, one link is asymmetrical, prefix the backups links with a "1" doesn't work everywhere, and special cases are not explained.
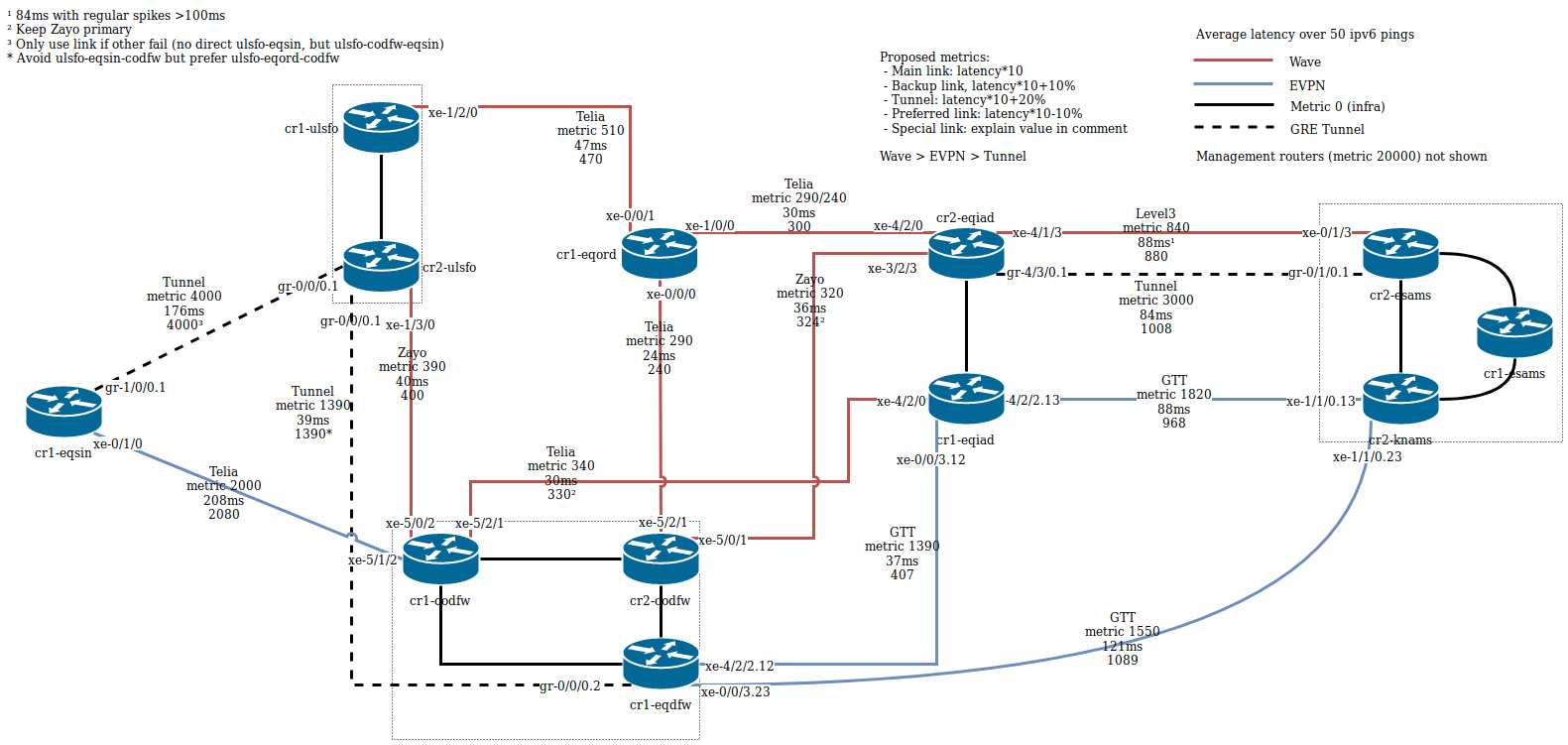
On that diagram, the 4th number for each link is the suggested new metric, based on the new tested latency and the following rules:
- Main link: latency*10
- Backup link, latency*10+10%
- Tunnel: latency*10+20%
- Preferred link: latency*10-10%
- Special link: explain value in comment
Thoughts?