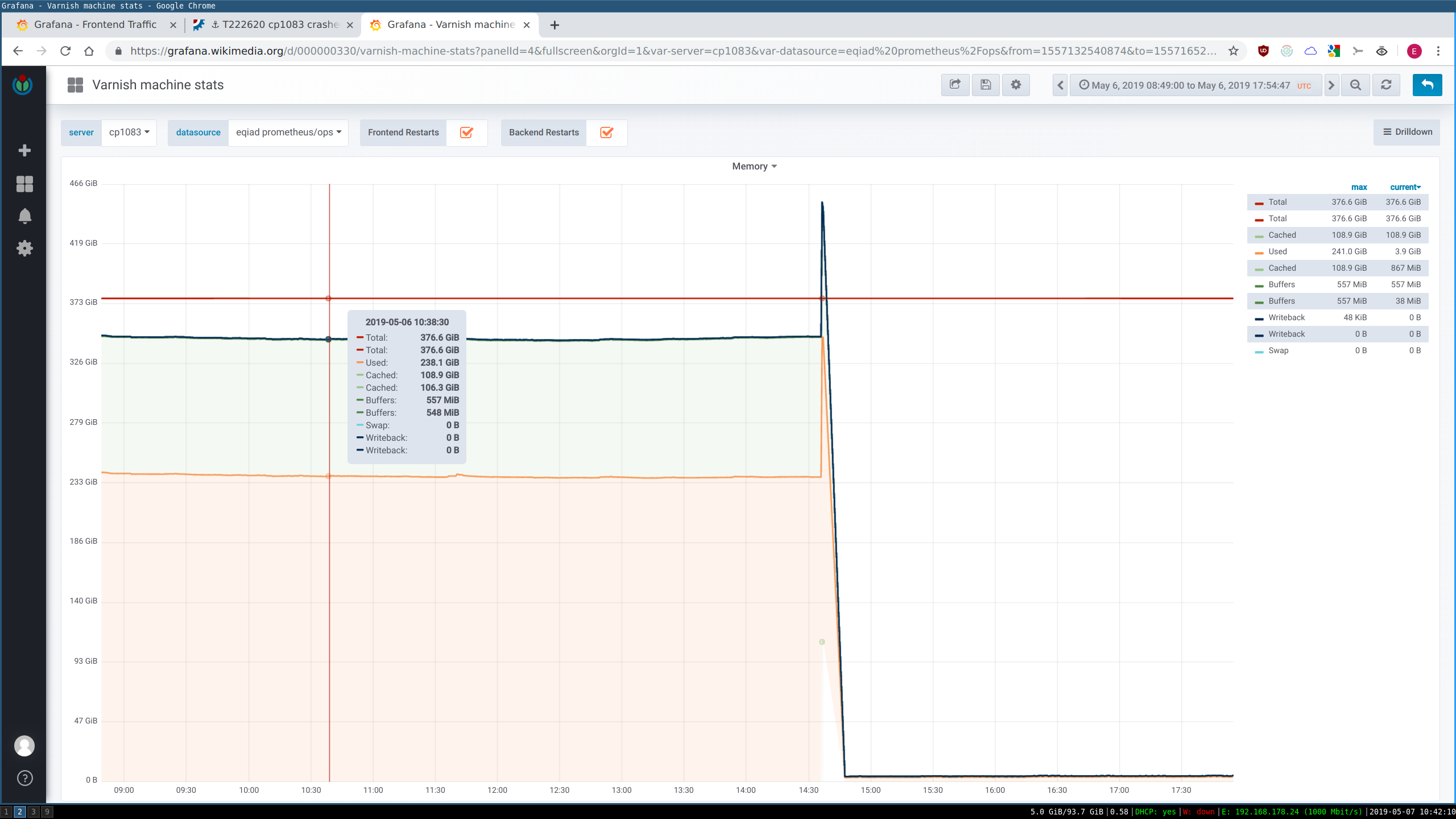
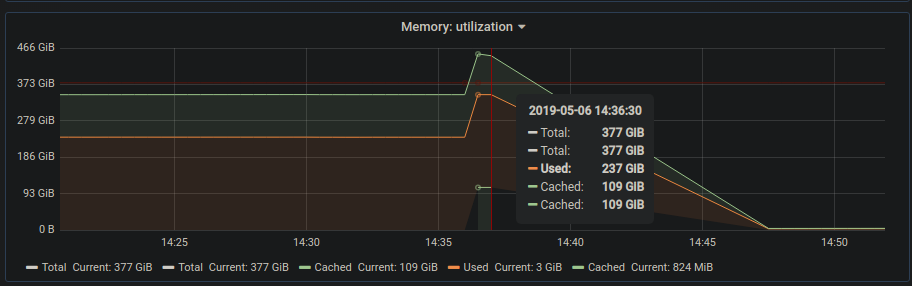
cp1083 suddenly crashed today at 14:37. Nothing in console. It came back online fine after a power cycle. We should check and see if it has any hardware issues.
SEL was apparently cleared today too, though it's not clear why and by whom.
/admin1-> racadm getsel Record: 1 Date/Time: 06/06/2018 13:30:25 Source: system Severity: Ok Description: Log cleared. ------------------------------------------------------------------------------- /admin1->