Beginning 2020-04-07 around 15:22 UTC, various cache_upload varnish frontends have started showing issues related to transient memory usage:
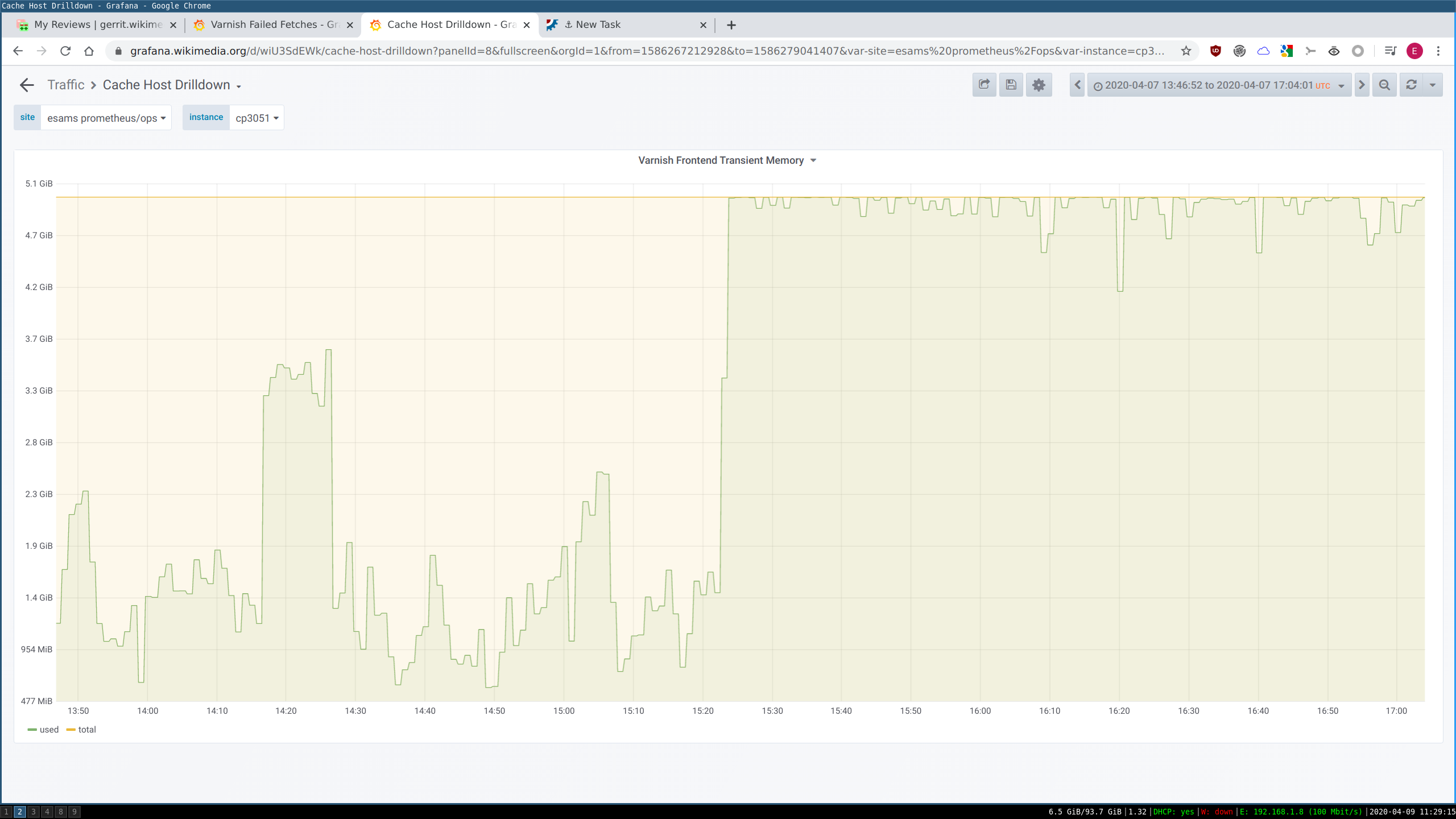
This causes fetch failures in esams, eqsin and eqiad.
While cache_text has had a limit on transient storage usage for a long time, this was not the case on cache_upload. We have started limiting transient storage on cache_upload on 2020-03-17 to address T185968.
To see if a larger amount of transient storage would help we have doubled the limit from 5G to 10G yesterday 2020-04-08 at 16ish. Unfortunately transient storage quickly filled up on the affected hosts after restarting varnish:
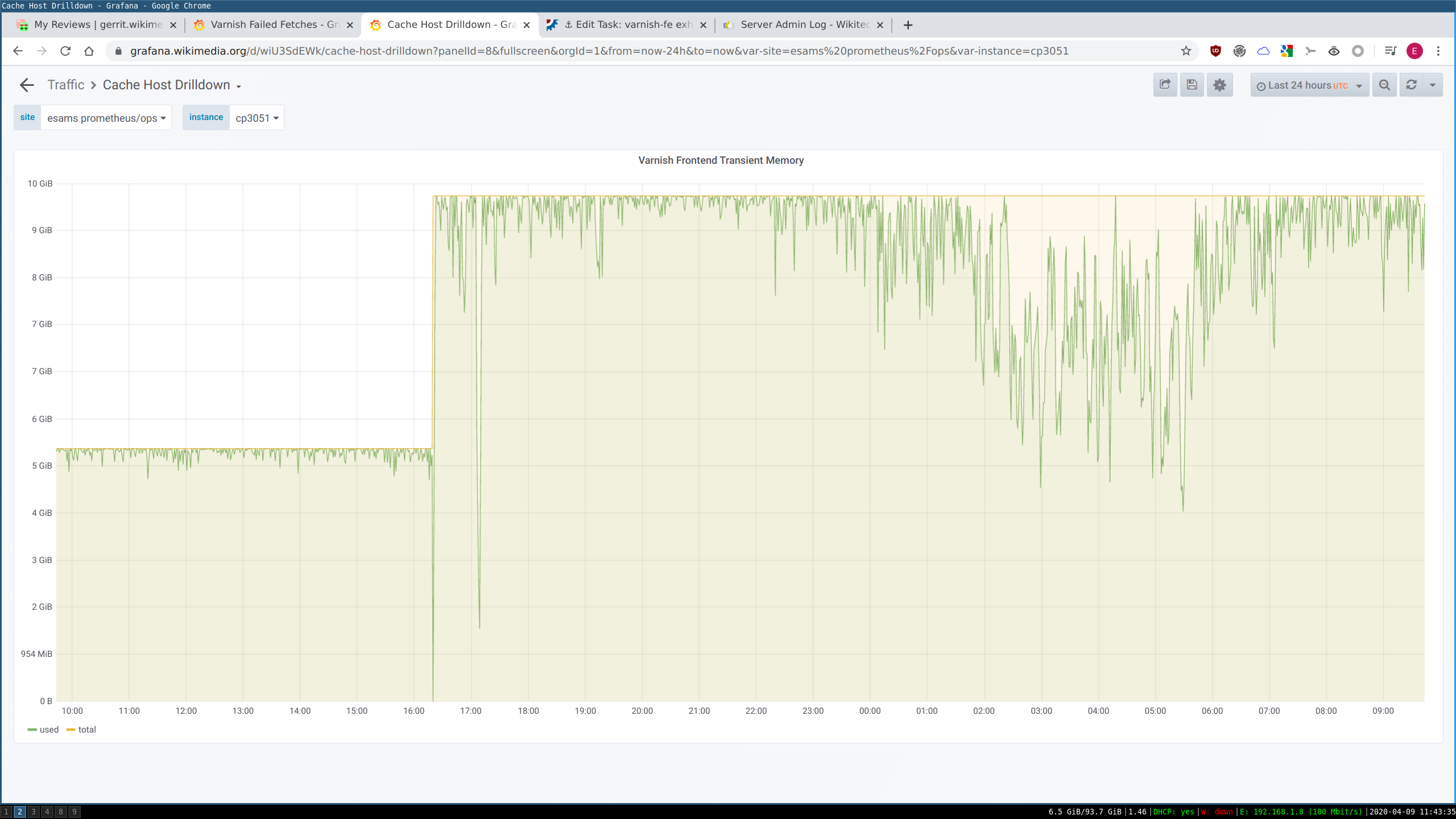
The following theory has been ruled out; after downgrading varnish on cp3051 the problem persists:
On 2020-04-06 around 13:05 we have deployed a patched varnish version addressing a bug that was causing varnishd crashes: T249344. Our patch was merged upstream and we backported it to 5.x. The patch may or may not have something to do with the issue described here.