The root cause of T252952: Wikidata dispatching slow and maxlag high on Wikidata due to db1101 replication lag was a host that was lagging behind, just enough to cause MW issues, but not enough to get pages sent out.
This is the graph:
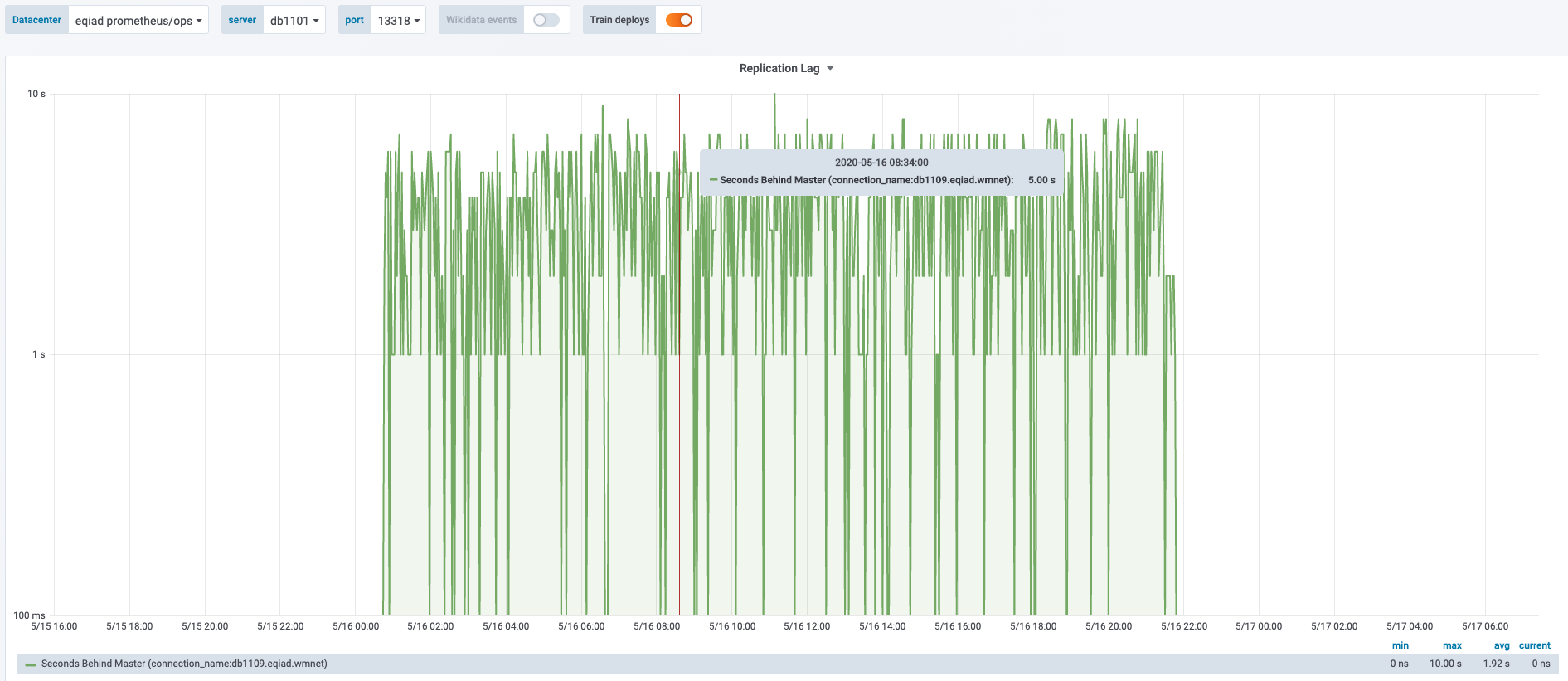
This is not the first time this happens, and tends to happen when big maintenance scripts run, specially on wikidatawiki, that cause 5-10 seconds sustained lag.
As discussed, this is hard to detect, but maybe a start can be to create a prometheus alert that would notify us when a host has such a pattern of spikes over a period of time.
This will need tuning as it is prone to cause lots of falses positives. But it is a start to prevent this from happening again.