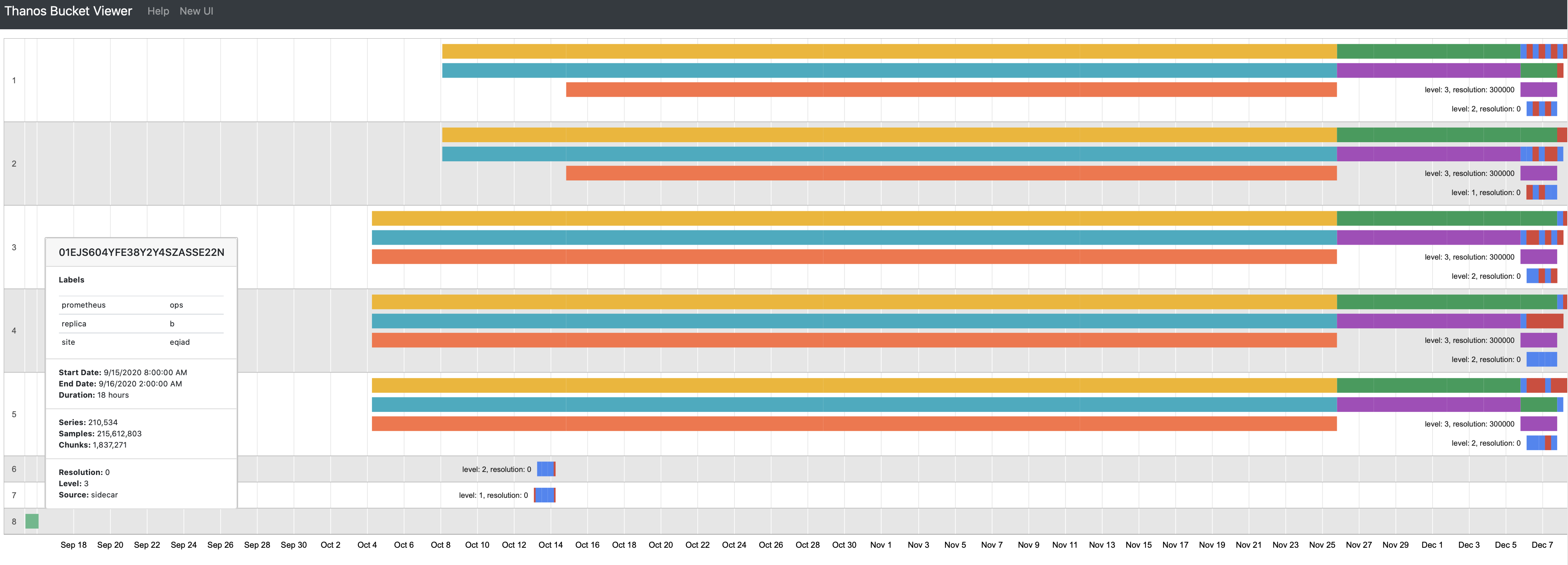
While investigating something else I noticed that data post-migration in T243057 wasn't being uploaded to Thanos. We've reenabled uploads however there's a gap that needs to be backfilled for each of eqsin/esams/ulsfo as seen from https://thanos.wikimedia.org/bucket/ :
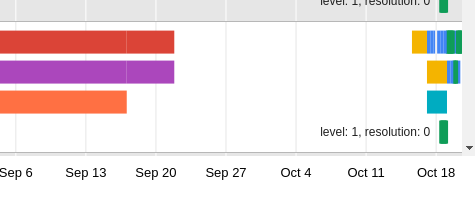
One question is how the missing data will fit in with the rest: the existing blocks on e.g. prometheus5001 are compacted already (in 24h blocks) and maybe the Thanos compactor will DTRT if we upload the blocks and pretend they belong to prometheus5001 (i.e. upload said blocks with the exact same labels, most importantly replica: a)
Alternatively I think a viable solution that should not bother/involve the Thanos compactor is uploading the missing data as if it were on another replica (e.g. replica: b, site: eqsin, prometheus:ops in the example above). Then at query time Thanos will DTRT and merge/deduplicate results from different replicas.
At any rate, we'll need to test any/all of those scenarios first, before actually uploading data to the production Thanos bucket. Therefore we'll need to:
- replicate the subset of data we're interested in that's already uploaded (i.e. data from PoPs that contains the gap) from the production bucket to a test bucket
- upload the missing prometheus blocks from PoPs into the test bucket
- run the compactor on the test bucket and see what happens