For a couple weeks, at least, the CI job have shown signs of slowness. The most prominent one is when Docker terminates a container, some takes a few minutes to be deleted which blocks docker run until the container root fs has been deleted. I have been almost full time investigating that issue for the last two weeks in order to rule out any mistake we could have done in the runner (Quibble), Jenkins, our instances configuration, Docker / containerd versions. The glory details of the investigation are in T265615.
Eventually last night I have pointed out the issue is due to I/O being an order of magnitude slower. I have determined it by counting file related system calls on the Docker daemon while it was deleting a container. The output after a few seconds:
% time seconds usecs/call calls errors syscall ------ ----------- ----------- --------- --------- ---------------- 94.50 0.221674 2 145394 11771 unlinkat 3.41 0.008000 2667 3 1 umount2 1.71 0.004000 1000 4 fchmodat 0.29 0.000674 0 11782 openat 0.09 0.000220 0 11774 3 newfstatat 0.00 0.000000 0 4 renameat ------ ----------- ----------- --------- --------- ---------------- 100.00 0.234568 168961 11775 total
Some unlinkat calls even take 100 - 200 ms.
The instance in the integration project collected Linux metrics via Diamond which can be queried via Graphite. They all show a dramatic increase of I/O latency:
Gauge of io in progress, described in Linux Documentation/iostats.txt as:
The only field that should go to zero. Incremented as requests are given to appropriate struct request_queue and decremented as they finish.
One can see them as the number of IO operations in the queue:
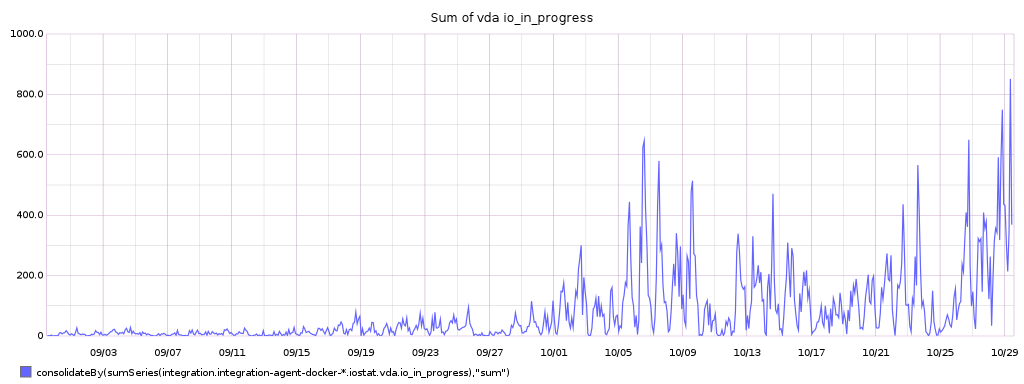
Sum of I/O milliseconds:

The number of I/O per second has not changed:

Details for I/O milliseconds per hosts:
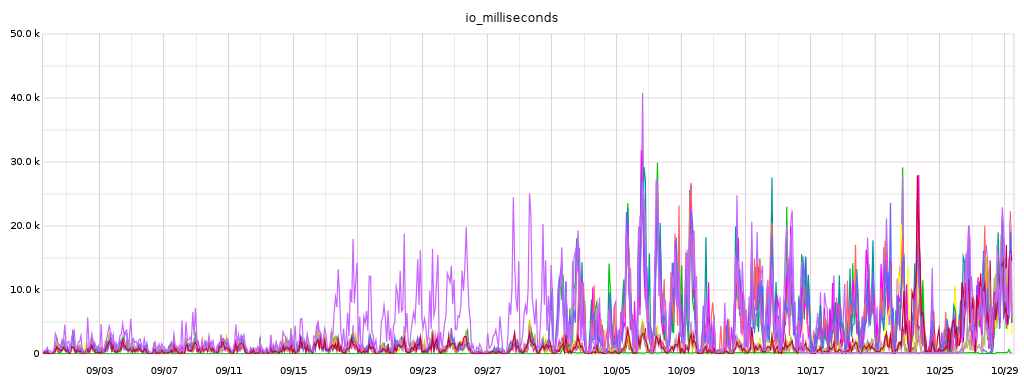
The purple one that stands out on 9/18 to 9/26 is integration-agent-docker-1020. That is the first instance that started using Ceph and got scheduled in August (T260916). I have added it with the aim of being able to assert the performances of moving to Ceph and if I remember properly it behaved fine in September when I looked at it.
A zoom at that host shows it was more or less fine (albeit still way slower than others), and starting 9/18 its performance degraded. The gap mid-october to 26/10 is when I have unpooled it while investigating the issue, it thus had no workload:
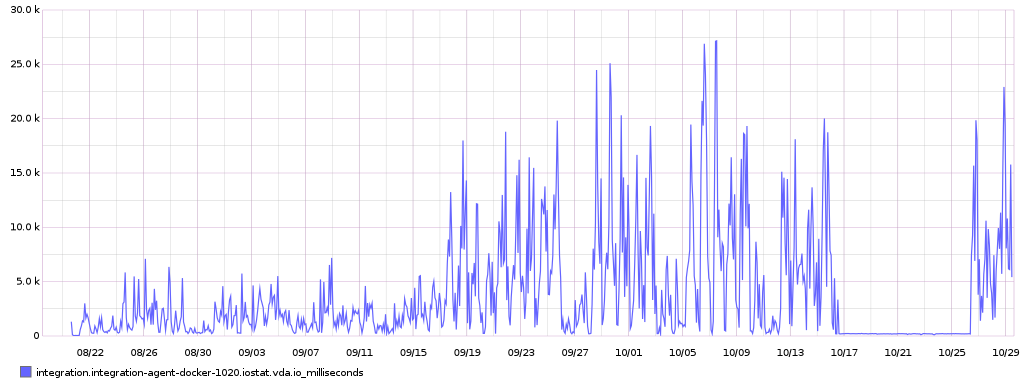
It seems that all instances have been moved to Ceph despite including the CI ones which was supposed to be tracked at T260916.