Proposal for: https://phabricator.wikimedia.org/T278261
Profile Information
Name: Vinayak Goswami
IRC Handle: vini7148 (freenode)
WikiMedia Page: Vini7148 (https://phabricator.wikimedia.org/p/Vini7148/)
GitHub: vini7148 (https://github.com/vini7148)
Location: Delhi, India
Time Zone: IST (UTC + 0530)
Typical Working Hours: 0900hrs to 0000hrs (UTC + 0530)
Synopsis
ORES is a web service that provides machine learning as a service for Wikimedia Projects, like Wikipedia and Wikidata. The system is designed to help human editors perform critical wiki-work and to increase their productivity by automating tasks like detecting vandalism and removing edits made in bad faith. ORES is developed by Wikimedia Scoring Platform, a team that specialises in building transparent, auditable, open, and ethical artificial intelligence (AI) to support human decision-making. Currently, the two general types of scores that ORES generates are in the context of
- “edit quality”
- “article quality”
The ORES has been enabling Machine Learning at this foundation for about 6 years, it is built on ML libraries like "sklearn" and also requires some custom written libraries like "revscoring", "mwparserfromhell" and others. With the introduction of new ML techniques and libraries like TensorFlow, Keras, Pytorch and many others, not only have they made creating and training new models easier but also provide a higher accuracy than the previously available models. Also, these libraries are regularly updated to make full use of the available hardware for even faster model training and predictions. The goal of this task is to retrain / recreate the ORES model using the latest available libraries but provided it has a higher accuracy than the already existing model. This project will focus on making use of latest ML libraries to develop and train model(s) that provides higher accuracy for predictions, the model should be more reliable even for a complex input.
Mentor(s)
About the Project
The aim of this recreation / retraining of the ORES model is to provide the community with a more accurate / better ML model than the existing ones, and also allow communities to utilise new models that are Lift Wing deployable.
Currently there are the following model classes available for giving scores to the edit / revision for an article: -
- articlequality - this model class predicts the quality of the article based on the "WikiProject article quality grading scheme"
- draftquality - this model class predicts whether the article / revision needs to be deleted or not, the article classified as a spam, vandalism, attack or OK(Accepted)
- drafttopic - this model class provides us with a list of topics / categories that an article might belong to, the list of topics can be found here
Technical details
- Details related to data preprocessing:
- Tokenizing - Breaking text / sentences into words / individual linguistic units, e.g. "This is a book.", after tokenizing this sentence, we will get a list of words that is ["this", "is', "a", "book."]
- Stop words - Certain words like "a", "is", etc. that make a language more understandable to the humans, but are of no use to a ML model, as don't provide the model with more useful information but only add on to the computational expense. e.g. on removing the stop words from the sentence used in the above example, we are left with the word "book". Alone this word would not sound grammatically correct, but for a model it is enough to understand the context of a sentence, i.e. in this case we are talking about a book. Note: Stop words are subjective to the model / use case, in case of using text with an image the word "this" would not have been a stop word, as it points to an object in the image that has been given to the model along with the text. For the input "This is a book" and the following image of a book , the word "this" provides useful information to the model, as it is pointing to the book that is present in the image and it cannot be treated as a stop word.

- N-grams - It is a contiguous sequence of n items / words in this case, the tokenized sentences have lost some useful information that was earlier present in them. The sequence "not good" that should have been classified as a negative comment / review, will be classified as a positive review as the sequence will be broken into "not" and "good", on seeing the word "good" the model will classify the input as positive contrary to the actual classification being negative. To prevent this from happening, we can use 2 grams or taking 2 words together. Now the words "not" and "good" will be taken together as "not good" and the comment will be classified as negative. (Note: in case of textual based models the n (number of contiguous items to be taken together) is taken as 2 or 3, but not more than these values. )
- TF-IDF - Term frequency - Inverse Document Frequency, is a weighting scheme that assigns each term in the document a weight that is based on the term frequency and the inverse document frequency. This weight helps us identify what the article / text is about, e.g. An article about Machine Learning would contain the word dataset or any other related term a greater number of times as compared to another article on python.

- Details for the first model based on articlequality:
- Data preprocessing / input preprocessing
- As mentioned earlier the subject nature of stop words list, a new list of stop words will be generated as this model will be required to find the grammatical correctness of a document, the words like "a", "is", etc. will be required by the model to generate a fitness of the input text.
- Certain classes like the "Redirect", "Portal", etc. can be determined using simple code / algorithms, this will help in reducing the computational complexity of the model.
- The model will also require a plagiarism score for the text, for this a plagiarism checker will be run on the input text and the score received from it will be fed to the model along with the preprocessed corpus / text.
- The model architecture
- The first requirement of the model will be to find the main topic of the article, for this the TF-IDF will help the model to narrow down on the main theme / topic.
- Certain classes like the "stub" can also benefit from the TF-IDF weights, as these frequencies will help the model to analyse the size of the text with respect to the main theme.
- Certain classes like the "FL" that require the article to have a systematic structure, can make use of regex techniques to analyse the flow of the article. The layers for the grammar will also make use of regex, as each sentence can be broken down into "subject" and "predicate" and then these two can be further broken down, giving us more features to play with.
- Certain classes like the "FA" require there to be no / a few grammatical mistakes in the article for this a few new layers will be introduced to check for the same, these layers will be inspired / make use of the BERT and ULMFiT architecture that have been in use for grammar checking (These architectures can be changed as there are a number of available grammar checking architectures)
- Since the model will be a neural network, each output neuron will provide us with a confidence level, if all the neurons have a confidence lower than a threshold the prediction will be "???" class.
- Output
- All the results will be gathered and the final processing will be performed, as mentioned above the criteria for the prediction to be "???" will be implemented here.
- Data preprocessing / input preprocessing
- Details for the second model based on draftquality:
- Data preprocessing
- Unlike the previous model, this model is not required to check for grammatical errors, so the stop words list will remain almost the same.
- But certain words like "this", "that", etc. will be preserved as they point to the main topic / theme of an article and provide the model with more useful information.
- Model Architecture (1st and 2nd sub model combined explanation)
- This model is required to analyse the article with respect to a main theme / topic, for this the subject / main theme will be identified using the TF-IDF weights.
- Later on, in the model architecture a few attention based layers will be added that analysis the nature of the article with respect to the main theme / idea. The output of these layers will be either of the following:
- In favour (words like "great", "good", etc. will help in this)
- Neutral (lack of words like "good", "bad", etc will make the model give out this prediction)
- Against (words like "bad", "not good", etc. will help in this)
- This output of the model on the latest revision / article will be compared to the output of the model on the previous article / revision, and a final judgement will be passed.
- Output
- As mentioned, the model will be executed on both the current revision of the article and the previous revision of the article.
- The output from the previous step will compared and the prediction will be given
- Note: this model relies on the fact that the previous revision of the article was correct and valid
- Data preprocessing
- Detail for the third model based on the drafttopic:
- Data / input preprocessing
- Since this model will revolve more around the main topic / idea of the article, the list stop words (from the data preprocessing step) will be enough for this purpose.
- Model Architecture
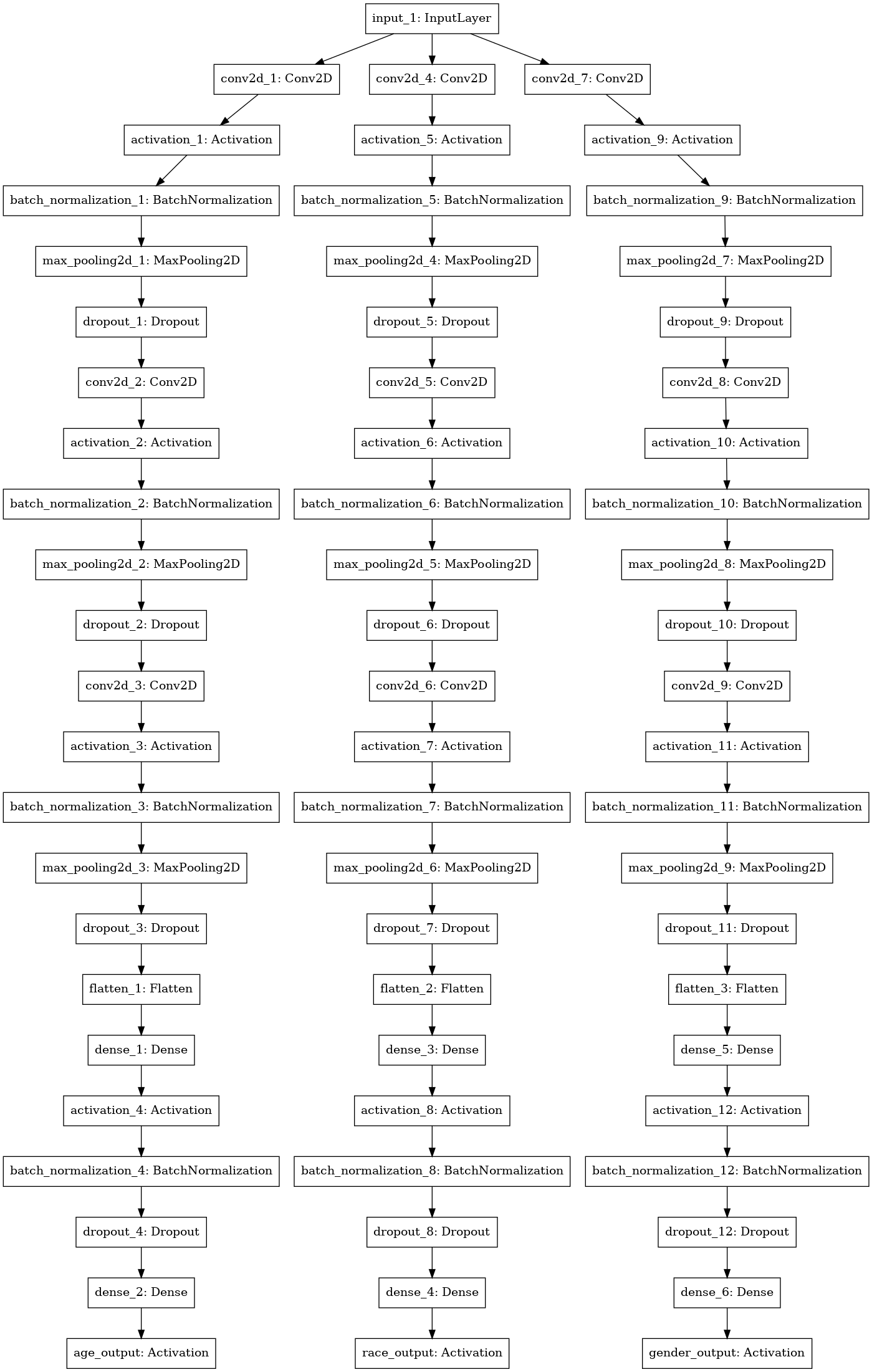
- Since this is a multi-output classification problem, a similar architecture to the one in this image will be used, that is starting with a single input layer and then splitting into multiple layers as move deeper into the model architecture

- There will be 4 different output layers, namely:
- Culture
- Geography
- History and society
- STEM
- This model will also rely on the TF-IDF weights as an article that is about India, will contain the word "Southeast Asia" more as compared to an article about USA, therefore classifying the article about India in Southeast Asia in the Geography category.
- Since this is a multi-output classification problem, a similar architecture to the one in this image
- Output
- The result from all the 4 sub models will be concatenated into one single list, and will be given to the user
- Note: this model will rely on the presence of certain words in the article, if a new discovery is made and new terms are added for any output class, the model will be required to retrain, I will try my best to eradicate this problem or at least make the retraining part easier to be done.
- Data / input preprocessing
Timeline
| Dates / Week | Task | Outcome / Deliverable |
|---|---|---|
| May 17, 2021 - June 7, 2021 | Community bonding Period Interacting with other WikiMedia community members and gathering insights on how the community works, and what are the do and don'ts for the community, other tasks to be carried out during this phase by me are: - Refining my proposal - Developing a better understanding of the current ORES model, and discussing my finds for the same with the mentors - Documenting my findings from the above process and also mentioning the shortcomings of the current models in the same - Analyse the currently available Machine Learning tools and creating a list of tools / model architectures that this model can benefit from | By the end of the process, I would have developed a better understanding of the current ORES model and would have also identified its shortcomings, that are to be worked upon. Deliverable Finalised proposal Document containing my initial findings and the steps that I will be taking to take care of the same |
| June 7, 2021 - June 13, 2021 | Week 1 I would like to begin the process of creating a new model by first understanding the dataset / the data that is to be used for training / testing the model, and how the input data really affects the output or the prediction. This process will include the following tasks: - Since we will be dealing with textual data a lot, the first thing to perform after tokenizing the sentences, will be removing the stop words (the words that helps us, humans in reading / understanding the text better and more easily but are of no use to the model), even though there are already existing list of stop words, but based on the application and the type content one is dealing with the list should be modified accordingly. - Since we have tokenized the sentences into words, some important information like a phrase "not good" has been broken into "not" and "good" and this creates a problem, so to overcome this problem, I would introduce n-grams, that is to group 2 or more (preferably till a group of 3) words together to provide the model with more information than before. - Next thing in preprocessing the data would be to calculate the TF-IDF (Term Frequency - Inverse Document Frequency) for each word, this creates more useful information for the model that will help in more accurately giving predictions / scores. - After the preprocessing is complete the data will be divided into training, validation (only if the model requires validation data) and testing data | Deliverable - A list of stop words (for future predictions) - preprocessed data - a separate training and testing data, also a set of validation data if required will be taken from the training data or testing data based on the scenario - visual representations for the changes in the data (this would include the before and after frequency counts for a word), how our actions have transformed the available data into a more useable form for the model |
| June 14, 2021 - June 27, 2021 | Week 2 and Week 3 The creating and training of the 1st model (articlequality) would begin and should be completed by the end of this period, during this phase the following tasks will be completed: - Any data preprocessing that would be specific to the type model being developed - Creating a basic flow of data through the model and what happens to data at each stage, this will be documented - Since this will be a multi class classification kind of problem, a neural network would be the best approach towards creating and training a model for this task (the architecture of the neural network is not fixed and can be changed to increase the performance of the model) - After a Neural Network, along with its architecture is created, hyper parameter tuning will be used to see if the accuracy of the model can increase or not, for this various loss functions will be tested and the best will be selected, also during this process the architecture of the model might be tweaked to see if there is any increase or benefit from the same, validation might be increased only if it provides a better result (as validation data might not be help full in every situation - After the creation and successful training of the model, it will be tested against the test data that we had earlier separated from the dataset, since the model has never seen this data before it will show how the model will actually perform in the real world, when it will be required to make predictions - The final thing left after all this will be to document all the new information and findings in the .ipynb file or a Jupyter Notebook (It has support for both python code and markup documentation), a readme.md file will also be created for the same, that describe the model and it's working / architecture. | Deliverable - a python notebook (.ipynb file) that contains the model and also the description for the same - a python code (.py file) for the training and then a separate file for getting predictions from the model - a list of labels (output classes) based on the "WikiProject article quality grading scheme" and a description for the same - a saved model weights file (.h5 in the case of TensorFlow or Keras Neural Network model) |
| June 28, 2021 - July 11, 2021 | Week 4 and Week 5 "draftquality" model class-based 2nd model will be created and trained during this period, for this the following tasks will be carried out: - Analysing the data available with respect to the model, and perform any necessary preprocessing required for the same - Unlike the previous model this is a case of bi-class classification problem, that is acceptable or unacceptable (that are further divided into subclasses that are spam, vandalism or attack) - Incase an input is classified as unacceptable, a subclass / the reason for rejecting it, will also be required - To care of the above problem, I will be required to create 2 models, the first model would predict, whether an article is acceptable or not, and the second model will predict the subclass in case the prediction is unacceptable by the first model (the second model will have 4 classes (spam, vandalism, attack, or OK) instead of 3 classes (spam, vandalism, or attack) so that there is a lower change of giving a wrong verdict for a valid article / revision. - Since the first model is a bi-class classification model, any suitable model / algorithm can be used based on the input data, a neural network might not be better than a statistical model, a few models will be tested for this and the best model will be selected - The 2nd model is a multi-class classification based; therefore, a neural network will be a better approach towards tackling these kinds of problems. - After the working models are created, hyper parameter tuning can be used, for this purpose various loss functions will be used and the best one will be selected, also the validation data can be used to see if the models are over fit to the training dataset and can help in early stopping the training process of the model, if required - Finally, the model(s) will be tested on the test dataset that was separated earlier from our dataset. - The model(s) will be documented, the document will contain the architecture and various other parameters of the model(s) | Deliverable - a python notebook (.ipynb file) that contains the model(s) and also the description for them - a python code (.py file) for the training and then a separate file for getting predictions from the model - 2 lists of labels (output classes), that are [spam, vandalism, attack or OK(Accepted)] and [acceptable, unacceptable] in this case and a description for the same - 2 saved model weights files (.h5 in the case of TensorFlow or Keras Neural Network model or a pickle dump in case of a statistical model) |
| July 12, 2021 - July 16, 2021 | First Evaluation, Week 6 | First Evaluation |
| July 17, 2021 - August 8, 2021 | Week 7, Week 8 and Week 9 The 3rd and the final model based on the "drafttopic" model class will be developed during this period, to accomplish this task the following subtasks will be carried out: - The data available will be modified, if required to best suit this model - Since there are 4 broader classes, that are "Culture", "Geography", "History and Society" and "STEM", these 4 classes have more subclasses, that will be the actual prediction of our model(s) - This is a case of multi output classification problem, a neural network will the best suited approach for this - The neural network would initially start with a single input layer but will divide into 4 different branches as we move deeper into the architecture of the neural network, an example network hierarchical structure can be seen here - After a base network is created, its various parameters will be tuned and tested to get the best possible prediction, this task will be a bit more tedious and time consuming than for the models before as the network divides into 4 different subnetworks, each having their own various parameters - The testing process for this will not be same as that done for the other models, as there are 4 different types of predictions, various test cases will be needed to completely test the working, this would include various combinations of the 4 classes, additional data might be required for this process, for this some fake inputs would be generated to check the accuracy of the model - Based on the outcome of the previous step necessary actions will be taken to refine the model, and the model will be again tested on the previous test input, this process will be repeated till satisfactory results are achieved. - After the successful training and testing of the model, the results and model itself will be documented | Deliverable - a python notebook (.ipynb file) that contains the model(s) and also the description for them - a python code (.py file) for the training and then a separate file for getting predictions from the model - a list of labels (output classes), that can be found here and a description for the same - a saved model weights file (.h5 in the case of TensorFlow or Keras Neural Network model) |
| August 9, 2021 - August 15, 2021 | Week 10 - Revisiting the documents created by me earlier during the internship period - Making the necessary changes and refining the documentation - Holding interactive sessions with the mentors to analyse the current shortcomings of my project and documentation work - Work on the drawbacks that would have been revealed by the mentors - After this I would again get back to the mentors to see if the problems that where earlier pointed out have been fixed or not - Finalising the models and their documentation | Deliverable - Final project report - Finalised models and their documentations - Any other documentations created during the above process (this would include all my documentation of the dataset and other findings) |
| August 16, 2021 - August 23, 2021 | Students Submit Code and Evaluations | Final Code and related documents will be submitted for evaluation |
| August 23, 2021 - August 30, 2021 | Mentors Submit Final Evaluations | Mentors Submit Final Evaluations |
| August 31, 2021 | Results Announced | Results Announced |
Participation
- A new GitHub repository will be maintained for this, and two separate branches will be maintained. The code will be regularly pushed to the development branch and will be merged with the main branch once reviewed and tested.
- I will be available on IRC during my working hours, that is from 0900hrs to 0000hrs (UTC + 0530). At any other time, I can be contacted through mail.
- Regular updates will be posted on Phabricator, regarding the completion of subtasks
About Me
I am an undergraduate student, pursuing a degree in B.E. / B.Tech in Computer Science and Engineering from Netaji Subhas University of Technology, New Delhi, India. Currently, I am in the 6th semester of my 8-semester program, I will graduate in 2022 (Batch of 2022). I heard about this program from my seniors. My odd semester will start in the first week of August, but I will be able to dedicated enough time to this project as majority of this period will be covering in my summer break and I will be having enough free time during the beginning of my odd semester that it won't affect me or my ability to contribute towards this project.
Being a student, free open-source resources have been my go-to choice for gaining knowledge or be it a tool for my studies, Wikipedia has played a major role in providing me with free learning opportunities. Through this opportunity I would like to give back to a community that has helped me grow and use this opportunity as a stepping stone for me to make more contributions to similar projects in the future.
Past Experience / Project
I have experience in working with C / C++, Python, Java, HTML, JavaScript, CSS and SQL. I mainly use a UNIX based distribution; my dot files can be found here
Machine Learning related projects
- Handwritten digit recognition using Neural Networks
- A CNN based image classifier, that detects which digit is drawn on the canvas (GUI) and also provides us with a confidence level for the prediction
- Trained the usable model on mnist handwritten digit dataset
- It has an interactive GUI
- It makes use of the TensorFlow library and Python 3
- YOLO v3 API
- An implementation of the YOLO v3 architecture in TensorFlow and Python 3 trained on COCO dataset
- To get results from the model a Flask api was also developed that runs the model on the input image and returns an image with the detected objects
- The api also returns a dictionary of all the object along with their count, that the model has detected
- Image Captioning using python
- RESNET50 architecture is used to extract image features and GLOVE to embed text data fed to the LSTM
- Trained the functional model on the LICKR8K dataset
- Clothing Image Classifier
- This is also a CNN based multi class classifier
- Trained using fashion mnist dataset
- Built using TensorFlow and Python 3
- AI Music Generator
- MIDI music files are generated on the based on the 100 notes that have been provided as input to the model
- RNN / LSTM was used for the model architecture
- Tic Tac Toe
- A C++ implementation of the tic-tac-toe game
- It is a single player game, a human can play against an AI
- The AI is implemented using the minimax algorithm
Other Projects
- Time Table management system
- It helps in maintaining timetable for schools / institutions more easily
- Developed using python / Django
- It makes use of sqlite for database
- School ranking website
- It helps parents in identifying which school is better for their child
- Developed using NodeJs and Python (for web scraping)
- It makes use of mongodb for database
Other Related activities
- Active Member of the NIX customisation community
- I have my own custom NIX desktop / theme
- An active member of the community forums on reddit / askubuntu / GitHub
Activities related to this project / Microtasks completed
- Understand the ORES architecture at a high level
- Understand the revscoring architecture at a high level
- Identify models to recreate by going through the list of current models
- Submit proposal
Other Info
The following will be the deliverables for the above-mentioned project:
- ORES model
- Data Preprocessing
- ReadMe.md
- preprocess.ipynb
- preprocess.py
- stopwords.txt
- Model 1(articlequality)
- ReadMe.md
- preprocess.py
- model.py
- train.py
- test.py
- predict.py
- Model_1.ipynb
- articlequality.h5
- Model 2(draftquality)
- ReadMe.md
- preprocess.py
- model1.py
- train1.py
- model2.py
- train2.py
- test.py
- predict.py
- Model_2.ipynb
- draftquality_1.h5 / draftquality_1.pickle
- draftquality_2.h5
- Model 3(drafttopic)
- ReadMe.md
- preprocess.py
- model.py
- train.py
- test.py
- predict.py
- Model_3.ipynb
- drafttopic.h5
- ReadMe.md
- Data Preprocessing
Link to the google doc: https://docs.google.com/document/d/1pjpYr1yEd8QUgXMgEe5glrJgMvcjbbI_rOG-2ImSwAg/edit?usp=sharing
Summary for the proposal
The aim of this project is to recreate / retrain the ORES model using the latest Machine Learning Technologies.
The outcome from this is expected to be 3 models based on the following model class: -
For completion of this task, I have divided the timeline into the following sections: -
- Section 1 - Community Bonding
- Section 2 - Data preprocessing
- Section 3 - Training and testing the first model
- Section 4 - Training and testing the second model(s)
- Section 5 - First Evaluation
- Section 6 - Training and testing the third model
- Section 7 - Finalizing the models and documentations, getting review from the mentors
- Section 8 - Final code submission
Note: I will be in contact with the mentors throughout this process via IRC or any other medium they might choose.
I have also tried to list down all the deliverables for this project.