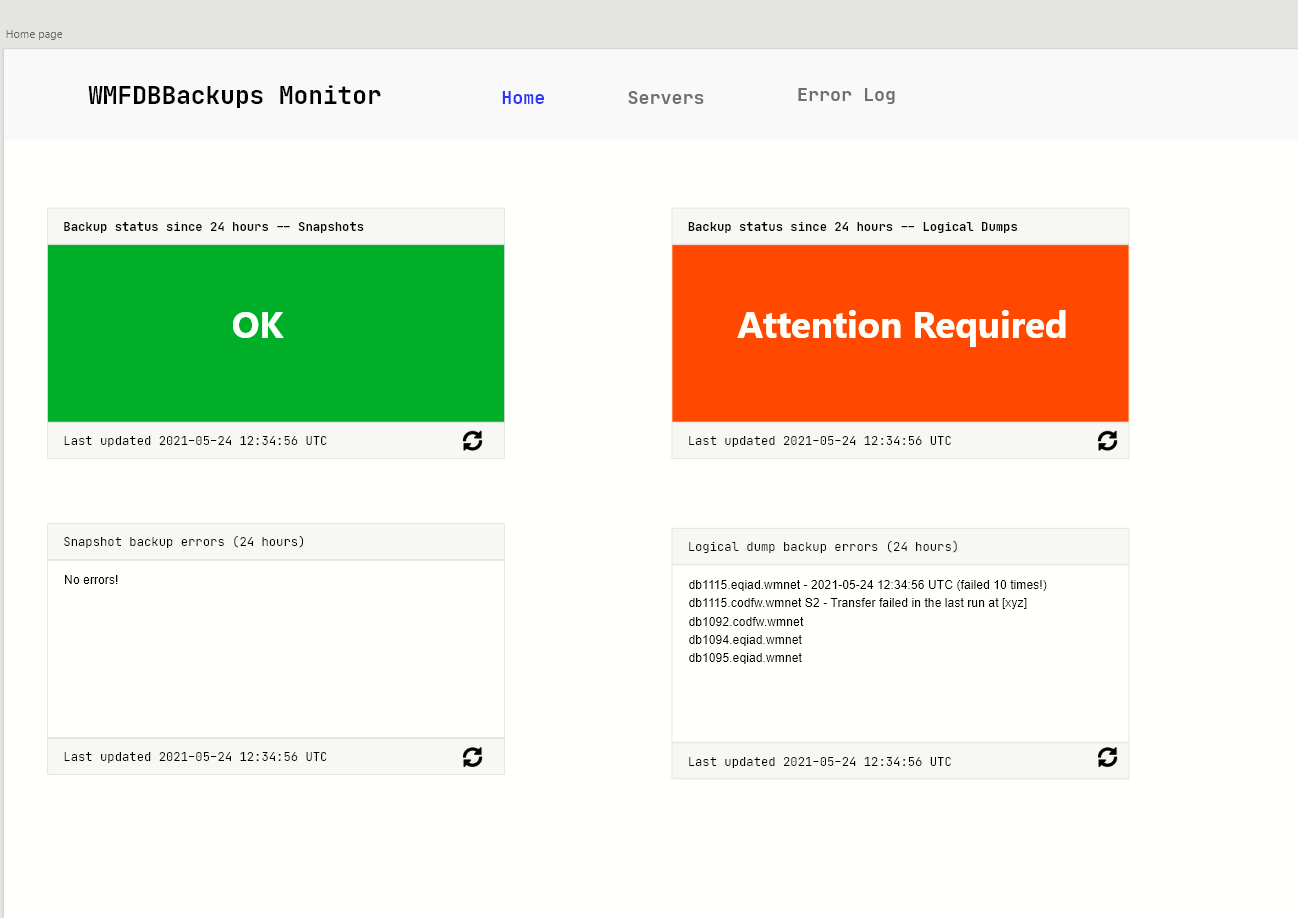
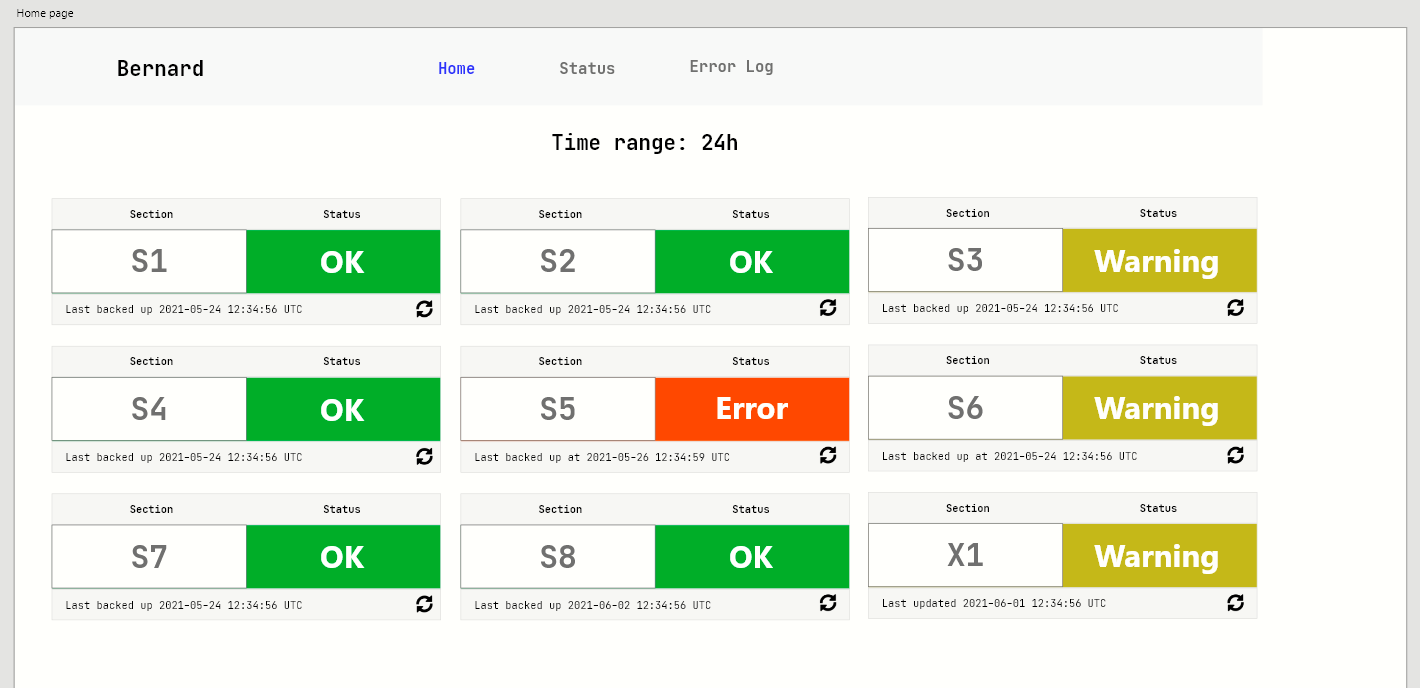
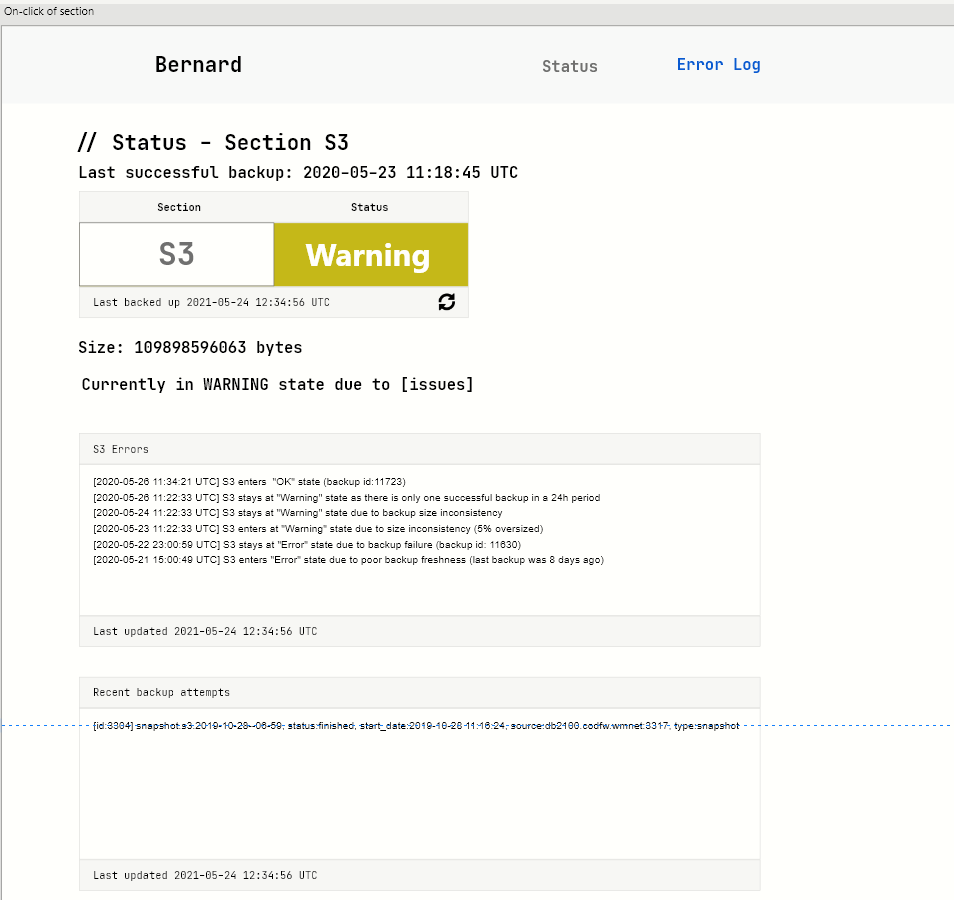
For T279552, GSoC 2021
We will need to create an abstract mockup of the system design for Bernard/WMFDBBackupsDashboard and also a mockup of what a potential front-end would look like
Tasks
- @h.krishna will make a system-design mockup for WMFDBBackupsDashboard and present it to @jcrespo and @Marostegui to gather feedback - DONE 27/05
- @h.krishna will create a front-end design mockup for WMFDBBackupsDashboard and present it to gather feedback - DONE 27/05
- @h.krishna will make changes according to feedback and will upload the designs into this ticket and present it again -- DONE 03/06