Repairing this table on the 4 instances of rack 1 would very long (probably more than 2 months), and we decided to snapshot-reload the data from all 12 instances instead.
- Snapshot
- Transfer
- Reload
- QA
| JAllemandou | |
| Sep 21 2021, 9:18 AM |
| F34782508: image.png | |
| Nov 29 2021, 9:45 AM |
| F34751764: image.png | |
| Nov 17 2021, 10:19 AM |
| F34709848: image.png | |
| Oct 25 2021, 8:50 AM |
| F34704576: image.png | |
| Oct 21 2021, 3:17 PM |
| F34693586: image.png | |
| Oct 18 2021, 8:48 AM |
| F34693591: image.png | |
| Oct 18 2021, 8:48 AM |
| F34683872: image.png | |
| Oct 11 2021, 9:16 AM |
| F34678691: image.png | |
| Oct 8 2021, 9:07 AM |
Repairing this table on the 4 instances of rack 1 would very long (probably more than 2 months), and we decided to snapshot-reload the data from all 12 instances instead.
| Status | Subtype | Assigned | Task | ||
|---|---|---|---|---|---|
| Resolved | BTullis | T249755 Cassandra3 migration for Analytics AQS | |||
| Resolved | JAllemandou | T290068 Check AQS with cassandra (serving + data) | |||
| Resolved | JAllemandou | T291473 Test snapshot-reload from all instances using pageview-top data table | |||
| Resolved | JAllemandou | T291472 Snapshot and Reload cassandra2 pageview_per_article data table from all 12 instances |
Mentioned in SAL (#wikimedia-analytics) [2021-09-28T09:55:07Z] <btullis> btullis@cumin1001:~$ sudo cumin --mode async 'aqs100*.eqiad.wmnet' 'nodetool-a snapshot -t T291472 local_group_default_T_pageviews_per_article_flat' 'nodetool-b snapshot -t T291472 local_group_default_T_pageviews_per_article_flat'
The transfer operation has started now. I've opted to omit the -v from rsync because there are too many files to make this output useful.
I experimented with rsync compression, which reduced the network traffic to ~15 MB/s but I don't think that this actually produced a benefit in terms of throughput.
This has completed 4 of the 12 snapshot transfers in around 24 hours. So the task should take around another 2 days to run.
It has now almost completed the 11th snapshot transfer, each taking around three and a quarter hours.
There is a concern around disk space, since we are using the same volume for holding the snapshot as for the cassandra data on each host.
Here is the current anount of free disk space on the cassandra partitions on the new cluster.
Note that aqs1014:/srv/cassandra-b is the only volume that is less than 50% full, because this is the destination for the 12th snapshot, which has yet to start.
btullis@cumin1001:~$ sudo cumin --no-progress 'aqs101[0,1,2,3,4,5].eqiad.wmnet' 'df -h /srv/cassandra-a /srv/cassandra-b' 6 hosts will be targeted: aqs[1010-1015].eqiad.wmnet Ok to proceed on 6 hosts? Enter the number of affected hosts to confirm or "q" to quit 6 ===== NODE GROUP ===== (1) aqs1010.eqiad.wmnet ----- OUTPUT of 'df -h /srv/cassa.../srv/cassandra-b' ----- Filesystem Size Used Avail Use% Mounted on /dev/md1 3.4T 2.1T 1.2T 64% /srv/cassandra-a /dev/md2 3.4T 1.9T 1.4T 58% /srv/cassandra-b ===== NODE GROUP ===== (1) aqs1011.eqiad.wmnet ----- OUTPUT of 'df -h /srv/cassa.../srv/cassandra-b' ----- Filesystem Size Used Avail Use% Mounted on /dev/md1 3.4T 2.0T 1.3T 61% /srv/cassandra-a /dev/md2 3.4T 1.8T 1.5T 55% /srv/cassandra-b ===== NODE GROUP ===== (1) aqs1012.eqiad.wmnet ----- OUTPUT of 'df -h /srv/cassa.../srv/cassandra-b' ----- Filesystem Size Used Avail Use% Mounted on /dev/md1 3.4T 1.8T 1.5T 56% /srv/cassandra-a /dev/md2 3.4T 1.9T 1.4T 59% /srv/cassandra-b ===== NODE GROUP ===== (1) aqs1013.eqiad.wmnet ----- OUTPUT of 'df -h /srv/cassa.../srv/cassandra-b' ----- Filesystem Size Used Avail Use% Mounted on /dev/md1 3.4T 1.8T 1.5T 54% /srv/cassandra-a /dev/md2 3.4T 1.8T 1.5T 56% /srv/cassandra-b ===== NODE GROUP ===== (1) aqs1014.eqiad.wmnet ----- OUTPUT of 'df -h /srv/cassa.../srv/cassandra-b' ----- Filesystem Size Used Avail Use% Mounted on /dev/md1 3.4T 1.9T 1.4T 58% /srv/cassandra-a /dev/md2 3.4T 454G 2.8T 14% /srv/cassandra-b ===== NODE GROUP ===== (1) aqs1015.eqiad.wmnet ----- OUTPUT of 'df -h /srv/cassa.../srv/cassandra-b' ----- Filesystem Size Used Avail Use% Mounted on /dev/md1 3.4T 1.8T 1.5T 54% /srv/cassandra-a /dev/md2 3.4T 1.8T 1.5T 55% /srv/cassandra-b ================ 100.0% (6/6) success ratio (>= 100.0% threshold) for command: 'df -h /srv/cassa.../srv/cassandra-b'. 100.0% (6/6) success ratio (>= 100.0% threshold) of nodes successfully executed all commands.
Here is the amount of space taken up by each of the snapshots. Note again the much smaller aqs1014:/srv/cassandra/tmp volume, which does not yet contain a snapshot of the local_group_default_T_pageviews_per_article_flat/data table.
btullis@cumin1001:~$ sudo cumin --no-progress 'aqs101[0,1,2,3,4,5].eqiad.wmnet' 'du -sh /srv/cassandra-a/tmp /srv/cassandra-b/tmp' 6 hosts will be targeted: aqs[1010-1015].eqiad.wmnet Ok to proceed on 6 hosts? Enter the number of affected hosts to confirm or "q" to quit 6 ===== NODE GROUP ===== (1) aqs1010.eqiad.wmnet ----- OUTPUT of 'du -sh /srv/cass.../cassandra-b/tmp' ----- 1.6T /srv/cassandra-a/tmp 1.4T /srv/cassandra-b/tmp ===== NODE GROUP ===== (1) aqs1011.eqiad.wmnet ----- OUTPUT of 'du -sh /srv/cass.../cassandra-b/tmp' ----- 1.4T /srv/cassandra-a/tmp 1.3T /srv/cassandra-b/tmp ===== NODE GROUP ===== (1) aqs1012.eqiad.wmnet ----- OUTPUT of 'du -sh /srv/cass.../cassandra-b/tmp' ----- 1.3T /srv/cassandra-a/tmp 1.4T /srv/cassandra-b/tmp ===== NODE GROUP ===== (1) aqs1013.eqiad.wmnet ----- OUTPUT of 'du -sh /srv/cass.../cassandra-b/tmp' ----- 1.2T /srv/cassandra-a/tmp 1.3T /srv/cassandra-b/tmp ===== NODE GROUP ===== (1) aqs1014.eqiad.wmnet ----- OUTPUT of 'du -sh /srv/cass.../cassandra-b/tmp' ----- 1.3T /srv/cassandra-a/tmp 22G /srv/cassandra-b/tmp ===== NODE GROUP ===== (1) aqs1015.eqiad.wmnet ----- OUTPUT of 'du -sh /srv/cass.../cassandra-b/tmp' ----- 1.3T /srv/cassandra-a/tmp 1.3T /srv/cassandra-b/tmp ================ 100.0% (6/6) success ratio (>= 100.0% threshold) for command: 'du -sh /srv/cass.../cassandra-b/tmp'. 100.0% (6/6) success ratio (>= 100.0% threshold) of nodes successfully executed all commands.
The proposed approach is to load these snapshots individually, at least to begin with, starting from the largest and the fullest disk.
Once this largest snapshot has been successfully loaded, it can be deleted, relieving the pressure on the disk capacity.
We will then proceed to the next largest and most full disk, carefully observing the behaviour during the table loading operation.
For instance, the largest snapshot and the most full disk at the moment is aqs1010:/srv/cassandra-a.
The snapshot is 1.6 TB and there is 1.2 TB free on the /srv/cassandra-a volume.
Our prediction is that the data on the volume will increase by around approximately 400 GB, leaving approximately 800 GB free on the volume after the snapshot has been loaded.
However, after this snapshot has been loaded we can remove it and free up 1.6 TB and increase the free space to 2.2 TB.
Then we move onto the next largest snapshot and so on, until all 12 have been loaded.
Depending on the time taken and the observed behaviour, we may wish to start loading some in parallel.
The transfer of all 12 snapshots has completed.
I will just run the script a second time, which should be a noop and relatively quick.
Yep, that worked 24 seconds to check all 12 copies and no files transferred.
Now moving on to the loading part for aqs1010:/srv/cassandra-a
Running the following script to import this snapshot:
#!/bin/bash set -e DOMAIN='eqiad.wmnet' HOSTS=('aqs1010') INSTANCES=('a') KEYSPACES=$(cat <<-END local_group_default_T_pageviews_per_article_flat END ) USERNAME=cassandra PASSWORD=cassandra for KEYSPACE in ${KEYSPACES} do echo "### Working on keyspace ${KEYSPACE}" for i in $(seq 0 0) do for INSTANCE in "${INSTANCES[@]}" do echo '' DATAPATHS=$(sudo cumin --force --no-progress --no-color -o txt "${HOSTS[$i]}.${DOMAIN}" "find /srv/cassandra-${INSTANCE}/tmp/${KEYSPACE} -maxdepth 1 -mindepth 1 -type d"| \ awk 'x==1 { print $0 } /_____FORMATTED_OUTPUT_____/ { x=1 }'| \ awk '{print $2}') for DATAPATH in ${DATAPATHS} do TABLE=$(echo ${DATAPATH} | awk -F / '{print $NF}' | awk -F - '{print $1}') DESTPATH=/srv/cassandra-${INSTANCE}/tmp/${KEYSPACE}/${TABLE} echo "### Creating destination directory for table ${TABLE} in keyspace ${KEYSPACE}" sudo cumin --force "${HOSTS[$i]}.${DOMAIN}" "mkdir -p ${DESTPATH}" echo "### Moving table ${TABLE} in keyspace ${KEYSPACE} for instance ${INSTANCE} on ${HOSTS[$i]} to ${DESTPATH}" sudo cumin --force --mode async "${HOSTS[$i]}.${DOMAIN}" "find ${DATAPATH} -type f -exec mv {} ${DESTPATH} \;" "find ${DATAPATH} -type d -empty -delete" echo "### Reloading table ${TABLE} in keyspace ${KEYSPACE} on host ${HOSTS[$i]}.${DOMAIN} instance ${INSTANCE}" sudo cumin --force "${HOSTS[$i]}.$DOMAIN" "sstableloader -u ${USERNAME} -f /etc/cassandra-${INSTANCE}/cassandra.yaml -d ${HOSTS[$i]}-${INSTANCE} -pw ${PASSWORD} ${DESTPATH}" echo '' done done done done
I know that for i in $(seq 0 0) is a bit daft, but it will work as is.
The first attempt at loading failed with an out-of-memory error.
----- OUTPUT of 'sstableloader -u...rticle_flat/data' ----- WARN 14:09:16,886 Only 22.198GiB free across all data volumes. Consider adding more capacity to your cluster or removing obsolete snapshots Established connection to initial hosts Opening sstables and calculating sections to stream ERROR 15:22:15,705 OutOfMemory error letting the JVM handle the error: java.lang.OutOfMemoryError: Java heap space
Mwarf :( Let's see if there are some loading settings we could tweak for this to succeed (may @hnowlan has an idea?).
/usr/bin/sstableloader is a shell script and these are the last 10 lines.
btullis@aqs1010:~$ tail /usr/bin/sstableloader
if [ "x$MAX_HEAP_SIZE" = "x" ]; then
MAX_HEAP_SIZE="256M"
fi
"$JAVA" $JAVA_AGENT -ea -cp "$CLASSPATH" $JVM_OPTS -Xmx$MAX_HEAP_SIZE \
-Dcassandra.storagedir="$cassandra_storagedir" \
-Dlogback.configurationFile=logback-tools.xml \
org.apache.cassandra.tools.BulkLoader "$@"
# vi:ai sw=4 ts=4 tw=0 etSo it should be OK to set $MAX_HEAP_SIZE to something higher, lets's say 8GB, before running.
Currently aqs1010 shows this from free, so I can't see a problem with appropriating 8 GB for the loader.
btullis@aqs1010:~$ free -g
total used free shared buff/cache available
Mem: 125 50 6 1 68 72
Swap: 0 0 0That has worked, so loading is now under way. The org.apache.cassandra.tools.BulkLoader task is using 4.5 GB of RAM.
The first snapshot load has completed in 58 hours.
Summary statistics: Connections per host : 1 Total files transferred : 32009 Total bytes transferred : 4435.702GiB Total duration : 209755880 ms Average transfer rate : 21.655MiB/s Peak transfer rate : 24.971MiB/s
I will remove the snapshot from the source (aqs1010:/srv/cassandra-a/tmp) and then move on to the second snapshot loading.
Carefully removed the data from aqs1010:/srv/cassandra-a/tmp and now there is 2.6 TB of space remaining in /srv/cassandra-a/ on aqs1010.
root@aqs1010:/srv/cassandra-a/tmp# df -h /srv/cassandra-a/ Filesystem Size Used Avail Use% Mounted on /dev/md1 3.4T 2.3T 1.0T 69% /srv/cassandra-a root@aqs1010:/srv/cassandra-a/tmp# du -sh /srv/cassandra-a/tmp/ 1.6T /srv/cassandra-a/tmp/ root@aqs1010:/srv/cassandra-a/tmp# rm -rf /srv/cassandra-a/tmp/local_group_default_T_* root@aqs1010:/srv/cassandra-a/tmp# df -h /srv/cassandra-a/ Filesystem Size Used Avail Use% Mounted on /dev/md1 3.4T 686G 2.6T 21% /srv/cassandra-a
The next largest directory is now aqs1011:/srv/cassandra-a at 67% full and 1.1 TB free.
btullis@cumin1001:~$ sudo cumin aqs101*.eqiad.wmnet 'df -h /srv/cassandra-a /srv/cassandra-b' 6 hosts will be targeted: aqs[1010-1015].eqiad.wmnet Ok to proceed on 6 hosts? Enter the number of affected hosts to confirm or "q" to quit 6 ===== NODE GROUP ===== (1) aqs1014.eqiad.wmnet ----- OUTPUT of 'df -h /srv/cassa.../srv/cassandra-b' ----- Filesystem Size Used Avail Use% Mounted on /dev/md1 3.4T 2.1T 1.2T 64% /srv/cassandra-a /dev/md2 3.4T 1.9T 1.5T 56% /srv/cassandra-b ===== NODE GROUP ===== (1) aqs1012.eqiad.wmnet ----- OUTPUT of 'df -h /srv/cassa.../srv/cassandra-b' ----- Filesystem Size Used Avail Use% Mounted on /dev/md1 3.4T 2.1T 1.3T 63% /srv/cassandra-a /dev/md2 3.4T 2.1T 1.2T 64% /srv/cassandra-b ===== NODE GROUP ===== (1) aqs1011.eqiad.wmnet ----- OUTPUT of 'df -h /srv/cassa.../srv/cassandra-b' ----- Filesystem Size Used Avail Use% Mounted on /dev/md1 3.4T 2.2T 1.1T 67% /srv/cassandra-a /dev/md2 3.4T 2.0T 1.3T 61% /srv/cassandra-b ===== NODE GROUP ===== (1) aqs1013.eqiad.wmnet ----- OUTPUT of 'df -h /srv/cassa.../srv/cassandra-b' ----- Filesystem Size Used Avail Use% Mounted on /dev/md1 3.4T 1.9T 1.4T 59% /srv/cassandra-a /dev/md2 3.4T 2.0T 1.3T 61% /srv/cassandra-b ===== NODE GROUP ===== (1) aqs1015.eqiad.wmnet ----- OUTPUT of 'df -h /srv/cassa.../srv/cassandra-b' ----- Filesystem Size Used Avail Use% Mounted on /dev/md1 3.4T 1.9T 1.4T 59% /srv/cassandra-a /dev/md2 3.4T 2.0T 1.4T 60% /srv/cassandra-b ===== NODE GROUP ===== (1) aqs1010.eqiad.wmnet ----- OUTPUT of 'df -h /srv/cassa.../srv/cassandra-b' ----- Filesystem Size Used Avail Use% Mounted on /dev/md1 3.4T 686G 2.6T 21% /srv/cassandra-a /dev/md2 3.4T 2.1T 1.2T 64% /srv/cassandra-b ================ PASS |███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 100% (6/6) [00:00<00:00, 2.68hosts/s] FAIL | | 0% (0/6) [00:00<?, ?hosts/s] 100.0% (6/6) success ratio (>= 100.0% threshold) for command: 'df -h /srv/cassa.../srv/cassandra-b'. 100.0% (6/6) success ratio (>= 100.0% threshold) of nodes successfully executed all commands.
I will modify the reloader script to load this snapshot next.
I believe that we will have to remove the source snapshots from the aqs100x servers, because there is not enough available disk space to maintain the snapshot of this keyspace for long.
btullis@aqs1004:~$ df -h /srv/cassandra-a/ /srv/cassandra-b/ Filesystem Size Used Avail Use% Mounted on /dev/md1 2.9T 2.6T 104G 97% /srv/cassandra-a /dev/md2 2.9T 2.2T 546G 81% /srv/cassandra-b btullis@aqs1004:~$ sudo nodetool-a listsnapshots Snapshot Details: Snapshot name Keyspace name Column family name True size Size on disk T291472 local_group_default_T_pageviews_per_article_flatdata 621.2 GB 1.34 TB T291472 local_group_default_T_pageviews_per_article_flatmeta 0 bytes 13 bytes Total TrueDiskSpaceUsed: 621.2 GB btullis@aqs1004:~$ sudo nodetool-b listsnapshots Snapshot Details: Snapshot name Keyspace name Column family name True size Size on disk T291472 local_group_default_T_pageviews_per_article_flatdata 323.73 GB 1.2 TB T291472 local_group_default_T_pageviews_per_article_flatmeta 0 bytes 13 bytes Total TrueDiskSpaceUsed: 323.73 GB
@JAllemandou - do you agree?
The second snapshot loading operation completed successfully in 47 hours.
progress: [/10.64.32.128]0:2618/2618 100% [/10.64.32.145]0:2364/2364 100% [/10.64.48.65]0:2611/2611 100% [/10.64.32.146]0:2501/2501 100% [/10.64.32.147]0:2408/2408 100% [/10.64.48.67]0:2155/2155 100% [/10.64.48.68]0:1906/1906 100% [/10.64.48.69]0:2496/2496 100% [/10.64.0.88]0:2108/2108 100% [/10.64.0.120]0:2370/2370 100% [/10.64.16.204]0:2358/2358 100% [/10.64.16.206]0:2258/2258 100% total: 100% 0.000KiB/s (avg: 23.219MiB/s) Summary statistics: Connections per host : 1 Total files transferred : 28153 Total bytes transferred : 3835.600GiB Total duration : 169154853 ms Average transfer rate : 23.219MiB/s Peak transfer rate : 24.973MiB/s ================ PASS |████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 100% (1/1) [46:59:17<00:00, 169157.49s/hosts] FAIL | | 0% (0/1) [46:59:17<?, ?hosts/s] 100.0% (1/1) success ratio (>= 100.0% threshold) for command: 'MAX_HEAP_SIZE=8G...rticle_flat/data'. 100.0% (1/1) success ratio (>= 100.0% threshold) of nodes successfully executed all commands.
Proceeding to delete this snapshot on aqs1011:/srv/cassandra-a/tmp and begin the process of loading the next snapshot.
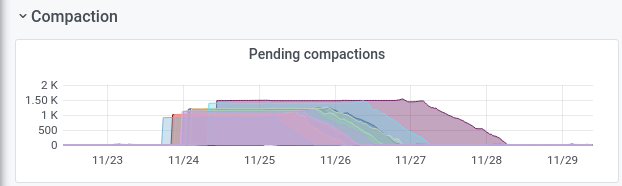
We can see from the graph of compaction here that the compactions following the loading of the first snapshot took around 72 hours to complete. Compactions start on each instance once its portion of the snapshot has been fully loaded.
Compactions have been running on the second snapshot for around 10 hours so far, so it will be interesting to see what impact the concurrent compactions have on loading performance, or vice versa.
If there is any detrimental effect to the data loading job I can cancel the loading and wait until the compactions for a snapshot have completed.

Below is a record of the amount of disk space free at the moment (sorted for clarity):
73% is the highest amount of space used at the moment, but the differences are marginal.
I'm going to proceed with aqs1010:/srv/cassandra-b/ (72%) next, followed by aqs1011:/srv/cassandra-b/ (70%)
The reason for this is that it will help us to free the disk space on these hosts to proceed with our other ticket: T291470: Repair and reload cassandra2 mediarequest_per_file data table
btullis@cumin1001:~$ sudo cumin --no-progress aqs101*.eqiad.wmnet 'df -h /srv/cassandra-a /srv/cassandra-b' 6 hosts will be targeted: aqs[1010-1015].eqiad.wmnet Ok to proceed on 6 hosts? Enter the number of affected hosts to confirm or "q" to quit 6 ===== NODE GROUP ===== (1) aqs1010.eqiad.wmnet ----- OUTPUT of 'df -h /srv/cassa.../srv/cassandra-b' ----- Filesystem Size Used Avail Use% Mounted on /dev/md1 3.4T 966G 2.3T 30% /srv/cassandra-a /dev/md2 3.4T 2.4T 929G 72% /srv/cassandra-b ===== NODE GROUP ===== (1) aqs1011.eqiad.wmnet ----- OUTPUT of 'df -h /srv/cassa.../srv/cassandra-b' ----- Filesystem Size Used Avail Use% Mounted on /dev/md1 3.4T 1.1T 2.2T 33% /srv/cassandra-a /dev/md2 3.4T 2.3T 1020G 70% /srv/cassandra-b ===== NODE GROUP ===== (1) aqs1012.eqiad.wmnet ----- OUTPUT of 'df -h /srv/cassa.../srv/cassandra-b' ----- Filesystem Size Used Avail Use% Mounted on /dev/md1 3.4T 2.3T 943G 72% /srv/cassandra-a /dev/md2 3.4T 2.4T 915G 73% /srv/cassandra-b ===== NODE GROUP ===== (1) aqs1013.eqiad.wmnet ----- OUTPUT of 'df -h /srv/cassa.../srv/cassandra-b' ----- Filesystem Size Used Avail Use% Mounted on /dev/md1 3.4T 2.2T 1.1T 68% /srv/cassandra-a /dev/md2 3.4T 2.3T 1.1T 69% /srv/cassandra-b ===== NODE GROUP ===== (1) aqs1014.eqiad.wmnet ----- OUTPUT of 'df -h /srv/cassa.../srv/cassandra-b' ----- Filesystem Size Used Avail Use% Mounted on /dev/md1 3.4T 2.4T 904G 73% /srv/cassandra-a /dev/md2 3.4T 2.1T 1.2T 65% /srv/cassandra-b ===== NODE GROUP ===== (1) aqs1015.eqiad.wmnet ----- OUTPUT of 'df -h /srv/cassa.../srv/cassandra-b' ----- Filesystem Size Used Avail Use% Mounted on /dev/md1 3.4T 2.2T 1.1T 68% /srv/cassandra-a /dev/md2 3.4T 2.2T 1.1T 68% /srv/cassandra-b ================ 100.0% (6/6) success ratio (>= 100.0% threshold) for command: 'df -h /srv/cassa.../srv/cassandra-b'. 100.0% (6/6) success ratio (>= 100.0% threshold) of nodes successfully executed all commands.
The script is running now.
### Moving table data in keyspace local_group_default_T_pageviews_per_article_flat for instance b on aqs1010 to /srv/cassandra-b/tmp/local_group_default_T_pageviews_per_article_flat/data ### Reloading table data in keyspace local_group_default_T_pageviews_per_article_flat on host aqs1010.eqiad.wmnet instance b
Just a note - if you're importing tables from two racks, doing a nodetool cleanup will probably return a significant amount of space from orphaned sstables, but will also probably take a while given the size of the data being imported.
Thanks @hnowlan - Perhaps we should run nodetool cleanup sequentially on all instances after importing everything.
The third snapshot loading has completed successfully. Compactions are still running and the prediction was about right. There was only a brief overlap when two instances were running compactions at the same time.
progress: [/10.64.32.128]0:1878/1878 100% [/10.64.32.145]0:2680/2680 100% [/10.64.48.65]0:2425/2425 100% [/10.64.32.146]0:2221/2221 100% [/10.64.32.147]0:2091/2091 100% [/10.64.48.67]0:1948/1948 100% [/10.64.48.68]0:2040/2040 100% [/10.64.48.69]0:2330/2330 100% [/10.64.0.120]0:2275/2275 100% [/10.64.0.88]0:2298/2298 100% [/10.64.16.204]0:2629/2629 100% [/10.64.16.206]0:1999/1999 100% total: 100% 0.000KiB/s (avg: 21.576MiB/s)
Summary statistics:
Connections per host : 1
Total files transferred : 26814
Total bytes transferred : 3710.538GiB
Total duration : 176106394 ms
Average transfer rate : 21.576MiB/s
Peak transfer rate : 24.972MiB/s
================
PASS |████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 100% (1/1) [48:55:09<00:00, 176109.15s/hosts]
FAIL | | 0% (0/1) [48:55:09<?, ?hosts/s]
100.0% (1/1) success ratio (>= 100.0% threshold) for command: 'MAX_HEAP_SIZE=8G...rticle_flat/data'.
100.0% (1/1) success ratio (>= 100.0% threshold) of nodes successfully executed all commands.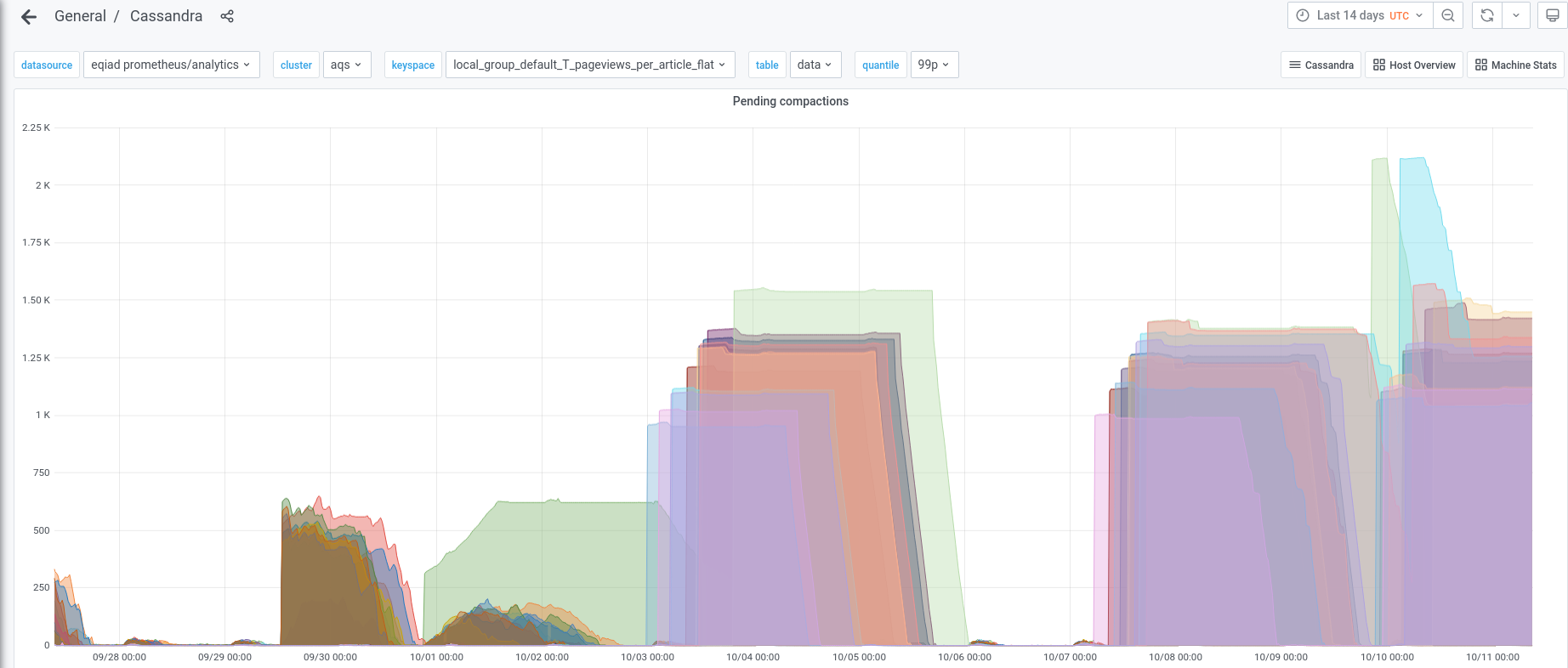
Cleared the space from aqs1010:/srv/cassandra-b/
root@aqs1010:/srv/cassandra-b/tmp# df -h /srv/cassandra-a/ /srv/cassandra-b/ Filesystem Size Used Avail Use% Mounted on /dev/md1 3.4T 1.2T 2.1T 37% /srv/cassandra-a /dev/md2 3.4T 2.6T 638G 81% /srv/cassandra-b root@aqs1010:/srv/cassandra-b/tmp# rm -rf local_group_default_T_* root@aqs1010:/srv/cassandra-b/tmp# df -h /srv/cassandra-a/ /srv/cassandra-b/ Filesystem Size Used Avail Use% Mounted on /dev/md1 3.4T 1.2T 2.1T 37% /srv/cassandra-a /dev/md2 3.4T 1.3T 2.0T 40% /srv/cassandra-b
Fourth snapshot loading operation is under way now.
### Moving table data in keyspace local_group_default_T_pageviews_per_article_flat for instance b on aqs1011 to /srv/cassandra-b/tmp/local_group_default_T_pageviews_per_article_flat/data ### Reloading table data in keyspace local_group_default_T_pageviews_per_article_flat on host aqs1011.eqiad.wmnet instance b
The fourth snapshot has finished loading:
progress: [/10.64.32.128]0:1996/1996 100% [/10.64.48.65]0:2172/2172 100% [/10.64.32.145]0:2099/2099 100% [/10.64.32.146]0:2124/2124 100% [/10.64.48.67]0:1369/1369 100% [/10.64.32.147]0:2386/2386 100% [/10.64.48.68]0:2422/2422 100% [/10.64.48.69]0:1819/1819 100% [/10.64.0.120]0:2002/2002 100% [/10.64.0.88]0:1798/1798 100% [/10.64.16.204]0:2294/2294 100% [/10.64.16.206]0:2450/2450 100% total: 100% 0.000KiB/s (avg: 22.607MiB/s)
Summary statistics:
Connections per host : 1
Total files transferred : 24931
Total bytes transferred : 3442.321GiB
Total duration : 155923699 ms
Average transfer rate : 22.607MiB/s
Peak transfer rate : 24.971MiB/s
================
PASS |████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 100% (1/1) [43:18:46<00:00, 155926.36s/hosts]
FAIL | | 0% (0/1) [43:18:46<?, ?hosts/s]
100.0% (1/1) success ratio (>= 100.0% threshold) for command: 'MAX_HEAP_SIZE=8G...rticle_flat/data'.
100.0% (1/1) success ratio (>= 100.0% threshold) of nodes successfully executed all commands.Reclaiming the space from aqs1011:/srv/cassandra-b/tmp and moving on to the next snapshot.
Reclaiming the space from this snapshot:
root@aqs1011:/srv/cassandra-b/tmp# df -h /srv/cassandra-b/ Filesystem Size Used Avail Use% Mounted on /dev/md2 3.4T 2.6T 645G 81% /srv/cassandra-b root@aqs1011:/srv/cassandra-b/tmp# rm -rf local_group_default_T_* root@aqs1011:/srv/cassandra-b/tmp# df -h /srv/cassandra-b/ Filesystem Size Used Avail Use% Mounted on /dev/md2 3.4T 1.4T 1.9T 43% /srv/cassandra-b
The current state of the data volumes, after loading 40% of the snapshots.
(1) aqs1010.eqiad.wmnet ----- OUTPUT of 'df -h /srv/cassa.../srv/cassandra-b' ----- Filesystem Size Used Avail Use% Mounted on /dev/md1 3.4T 1.3T 2.0T 39% /srv/cassandra-a /dev/md2 3.4T 1.4T 1.9T 44% /srv/cassandra-b (1) aqs1011.eqiad.wmnet ----- OUTPUT of 'df -h /srv/cassa.../srv/cassandra-b' ----- Filesystem Size Used Avail Use% Mounted on /dev/md1 3.4T 1.5T 1.8T 47% /srv/cassandra-a /dev/md2 3.4T 1.4T 1.9T 43% /srv/cassandra-b (1) aqs1012.eqiad.wmnet ----- OUTPUT of 'df -h /srv/cassa.../srv/cassandra-b' ----- Filesystem Size Used Avail Use% Mounted on /dev/md1 3.4T 2.7T 607G 82% /srv/cassandra-a /dev/md2 3.4T 2.8T 509G 85% /srv/cassandra-b (1) aqs1013.eqiad.wmnet ----- OUTPUT of 'df -h /srv/cassa.../srv/cassandra-b' ----- Filesystem Size Used Avail Use% Mounted on /dev/md1 3.4T 2.6T 682G 80% /srv/cassandra-a /dev/md2 3.4T 2.7T 619G 82% /srv/cassandra-b (1) aqs1014.eqiad.wmnet ----- OUTPUT of 'df -h /srv/cassa.../srv/cassandra-b' ----- Filesystem Size Used Avail Use% Mounted on /dev/md1 3.4T 2.8T 483G 86% /srv/cassandra-a /dev/md2 3.4T 2.4T 933G 72% /srv/cassandra-b (1) aqs1015.eqiad.wmnet ----- OUTPUT of 'df -h /srv/cassa.../srv/cassandra-b' ----- Filesystem Size Used Avail Use% Mounted on /dev/md1 3.4T 2.5T 743G 78% /srv/cassandra-a /dev/md2 3.4T 2.6T 736G 78% /srv/cassandra-b ================ 100.0% (6/6) success ratio (>= 100.0% threshold) for command: 'df -h /srv/cassa.../srv/cassandra-b'. 100.0% (6/6) success ratio (>= 100.0% threshold) of nodes successfully executed all commands.
So the next most pressing snapshot to work on will be aqs1014:/srv/cassandra-a/ which is at 86% of capacity with 481 GB free.
Reload operation five of twelve under way now.
### Moving table data in keyspace local_group_default_T_pageviews_per_article_flat for instance a on aqs1014 to /srv/cassandra-a/tmp/local_group_default_T_pageviews_per_article_flat/data ### Reloading table data in keyspace local_group_default_T_pageviews_per_article_flat on host aqs1014.eqiad.wmnet instance a
The fifth snapshot has finished loading.
progress: [/10.64.32.128]0:2230/2230 100% [/10.64.32.145]0:2804/2804 100% [/10.64.48.65]0:2659/2659 100% [/10.64.32.146]0:2248/2248 100% [/10.64.48.67]0:1914/1914 100% [/10.64.32.147]0:2484/2484 100% [/10.64.48.68]0:1879/1879 100% [/10.64.48.69]0:2120/2120 100% [/10.64.0.120]0:2189/2189 100% [/10.64.0.88]0:2131/2131 100% [/10.64.16.204]0:2149/2149 100% [/10.64.16.206]0:2389/2389 100% total: 100% 0.000KiB/s (avg: 20.587MiB/s)
Summary statistics:
Connections per host : 1
Total files transferred : 27196
Total bytes transferred : 3652.375GiB
Total duration : 181673965 ms
Average transfer rate : 20.587MiB/s
Peak transfer rate : 24.969MiB/s
================
PASS |████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 100% (1/1) [50:27:56<00:00, 181676.77s/hosts]
FAIL | | 0% (0/1) [50:27:56<?, ?hosts/s]
100.0% (1/1) success ratio (>= 100.0% threshold) for command: 'MAX_HEAP_SIZE=8G...rticle_flat/data'.
100.0% (1/1) success ratio (>= 100.0% threshold) of nodes successfully executed all commands.I will reclaim the space from aqs1014:/srv/cassandra-a/tmp and move on to the next snapshot.
Reclaiming the space from aqs1014:/srv/cassandra-a/tmp
root@aqs1014:/srv/cassandra-a/tmp# df -h /srv/cassandra-a/ Filesystem Size Used Avail Use% Mounted on /dev/md1 3.4T 3.0T 259G 93% /srv/cassandra-a root@aqs1014:/srv/cassandra-a/tmp# rm -rf local_group_default_T_* root@aqs1014:/srv/cassandra-a/tmp# df -h /srv/cassandra-a/ Filesystem Size Used Avail Use% Mounted on /dev/md1 3.4T 1.7T 1.6T 53% /srv/cassandra-a root@aqs1014:/srv/cassandra-a/tmp#
Current state of the data volumes.
(1) aqs1010.eqiad.wmnet ----- OUTPUT of 'df -h /srv/cassa.../srv/cassandra-b' ----- Filesystem Size Used Avail Use% Mounted on /dev/md1 3.4T 1.5T 1.8T 45% /srv/cassandra-a /dev/md2 3.4T 1.7T 1.6T 51% /srv/cassandra-b (1) aqs1011.eqiad.wmnet ----- OUTPUT of 'df -h /srv/cassa.../srv/cassandra-b' ----- Filesystem Size Used Avail Use% Mounted on /dev/md1 3.4T 1.7T 1.6T 52% /srv/cassandra-a /dev/md2 3.4T 1.7T 1.7T 51% /srv/cassandra-b (1) aqs1012.eqiad.wmnet ----- OUTPUT of 'df -h /srv/cassa.../srv/cassandra-b' ----- Filesystem Size Used Avail Use% Mounted on /dev/md1 3.4T 2.9T 373G 89% /srv/cassandra-a /dev/md2 3.4T 3.0T 291G 92% /srv/cassandra-b (1) aqs1013.eqiad.wmnet ----- OUTPUT of 'df -h /srv/cassa.../srv/cassandra-b' ----- Filesystem Size Used Avail Use% Mounted on /dev/md1 3.4T 2.8T 453G 87% /srv/cassandra-a /dev/md2 3.4T 2.9T 391G 89% /srv/cassandra-b (1) aqs1014.eqiad.wmnet ----- OUTPUT of 'df -h /srv/cassa.../srv/cassandra-b' ----- Filesystem Size Used Avail Use% Mounted on /dev/md1 3.4T 1.7T 1.6T 53% /srv/cassandra-a /dev/md2 3.4T 2.6T 733G 78% /srv/cassandra-b (1) aqs1015.eqiad.wmnet ----- OUTPUT of 'df -h /srv/cassa.../srv/cassandra-b' ----- Filesystem Size Used Avail Use% Mounted on /dev/md1 3.4T 2.6T 635G 81% /srv/cassandra-a /dev/md2 3.4T 2.7T 569G 83% /srv/cassandra-b
So the next most pressing snapshot to load is aqs1012:/srv/cassandra-b which is at 92% full and has 291 GB free.
### Moving table data in keyspace local_group_default_T_pageviews_per_article_flat for instance b on aqs1012 to /srv/cassandra-b/tmp/local_group_default_T_pageviews_per_article_flat/data ### Reloading table data in keyspace local_group_default_T_pageviews_per_article_flat on host aqs1012.eqiad.wmnet instance b
This was started at 12:00 UTC today.
Two of the volumes have hit 100% of capacity after the most recent loading operation completed. Here is the final output from the loading command.
progress: [/10.64.32.128]0:2544/2544 100% [/10.64.48.65]0:2052/2052 100% [/10.64.32.145]0:2091/2091 100% [/10.64.32.146]0:2521/2521 100% [/10.64.48.67]0:2001/2001 100% [/10.64.32.147]0:2151/2151 100% [/10.64.48.68]0:2077/2077 100% [/10.64.48.69]0:2331/2331 100% [/10.64.0.120]0:2156/2156 100% [/10.64.0.88]0:2239/2239 100% [/10.64.16.204]0:2384/2384 100% [/10.64.16.206]0:2640/2640 100% total: 100% 0.000KiB/s (avg: 22.302MiB/s)
Summary statistics:
Connections per host : 1
Total files transferred : 27187
Total bytes transferred : 3709.598GiB
Total duration : 170328561 ms
Average transfer rate : 22.302MiB/s
Peak transfer rate : 24.972MiB/s
================
PASS |████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 100% (1/1) [47:18:51<00:00, 170331.15s/hosts]
FAIL | | 0% (0/1) [47:18:51<?, ?hosts/s]
100.0% (1/1) success ratio (>= 100.0% threshold) for command: 'MAX_HEAP_SIZE=8G...rticle_flat/data'.
100.0% (1/1) success ratio (>= 100.0% threshold) of nodes successfully executed all commands.However, these two volumes have now hit 100%:
aqs1012:/srv/cassandra-b
aqs1013:/srv/cassandra-b
The cassandra services on these instances have stopped:


Cassandra hourly jobs in Oozie are also failing as a result.
I am going to copy the following two directories to an-presto1001.eqiad.wmnet:
The destination directories will be:
Once I have completed these copies I can remove the source directories and restart the cassandra-b services on aqs1012 and aqs1013.
I have begun the first transfer.
btullis@cumin1001:~$ sudo transfer.py aqs1012.eqiad.wmnet:/srv/cassandra-b/tmp/local_group_default_T_pageviews_per_article_flat an-presto1001.eqiad.wmnet:/srv/cassandra_migration/aqs1012-b/ 2021-10-18 09:17:09 INFO: About to transfer /srv/cassandra-b/tmp/local_group_default_T_pageviews_per_article_flat from aqs1012.eqiad.wmnet to ['an-presto1001.eqiad.wmnet']:['/srv/cassandra_migration/aqs1012-b/'] (1426294625885 bytes)
Running a second, concurrent transfer operation:
btullis@cumin1001:~$ sudo transfer.py aqs1013.eqiad.wmnet:/srv/cassandra-b/tmp/local_group_default_T_pageviews_per_article_flat an-presto1001.eqiad.wmnet:/srv/cassandra_migration/aqs1013-b/ 2021-10-18 09:25:08 INFO: About to transfer /srv/cassandra-b/tmp/local_group_default_T_pageviews_per_article_flat from aqs1013.eqiad.wmnet to ['an-presto1001.eqiad.wmnet']:['/srv/cassandra_migration/aqs1013-b/'] (1335360082154 bytes)
I have extracted the cassandra package to /home/btullis/cassandra/ on an-presto1001 using the commands:
mkdir cassandra ; cd cassandra apt-get download cassandra dpkg-deb -x cassandra_2.2.6-wmf5_all.deb .
I have copied the default cassandra.in file to my home directory and modified it:
cp usr/share/cassandra/cassandra.in.sh ~/.cassandra.in.sh
btullis@an-presto1001:~/cassandra/usr$ cat ~/.cassandra.in.sh
# The directory where Cassandra's configs live (required)
CASSANDRA_CONF=/home/btullis/cassandra/etc/cassandra
CASSANDRA_HOME=/home/btullis/cassandra/usr/share/cassandra
# The java classpath (required)
if [ -n "$CLASSPATH" ]; then
CLASSPATH=$CLASSPATH:$CASSANDRA_CONF
else
CLASSPATH=$CASSANDRA_CONF
fi
for jar in /home/btullis/cassandra/usr/share/cassandra/lib/*.jar; do
CLASSPATH=$CLASSPATH:$jar
done
for jar in /home/btullis/cassandra/usr/share/cassandra/*.jar; do
CLASSPATH=$CLASSPATH:$jar
done
CLASSPATH="$CLASSPATH:$EXTRA_CLASSPATH"
# set JVM javaagent opts to avoid warnings/errors
if [ "$JVM_VENDOR" != "OpenJDK" -o "$JVM_VERSION" \> "1.6.0" ] \
|| [ "$JVM_VERSION" = "1.6.0" -a "$JVM_PATCH_VERSION" -ge 23 ]
then
JAVA_AGENT="$JAVA_AGENT -javaagent:$CASSANDRA_HOME/lib/jamm-0.3.0.jar"
fiI can now run sstableloader correctly.
The two transfers have completed:
2021-10-18 09:16:27 ERROR: The specified target path /srv/cassandra_migration/cassandra_migration/aqs1012-b/ doesn't exist on an-presto1001.eqiad.wmnet btullis@cumin1001:~$ sudo transfer.py aqs1012.eqiad.wmnet:/srv/cassandra-b/tmp/local_group_default_T_pageviews_per_article_flat an-presto1001.eqiad.wmnet:/srv/cassandra_migration/aqs1012-b/ 2021-10-18 09:17:09 INFO: About to transfer /srv/cassandra-b/tmp/local_group_default_T_pageviews_per_article_flat from aqs1012.eqiad.wmnet to ['an-presto1001.eqiad.wmnet']:['/srv/cassandra_migration/aqs1012-b/'] (1426294625885 bytes) 2021-10-18 11:45:12 WARNING: Original size is 1426294625885 but transferred size is 1426294679133 for copy to an-presto1001.eqiad.wmnet 2021-10-18 11:45:13 INFO: Parallel checksum of source on aqs1012.eqiad.wmnet and the transmitted ones on an-presto1001.eqiad.wmnet match. 2021-10-18 11:45:14 INFO: 1426294679133 bytes correctly transferred from aqs1012.eqiad.wmnet to an-presto1001.eqiad.wmnet 2021-10-18 11:45:15 WARNING: Firewall's temporary rule could not be deleted 2021-10-18 11:45:15 INFO: Cleaning up....
btullis@cumin1001:~$ sudo transfer.py aqs1013.eqiad.wmnet:/srv/cassandra-b/tmp/local_group_default_T_pageviews_per_article_flat an-presto1001.eqiad.wmnet:/srv/cassandra_migration/aqs1013-b/ 2021-10-18 09:25:08 INFO: About to transfer /srv/cassandra-b/tmp/local_group_default_T_pageviews_per_article_flat from aqs1013.eqiad.wmnet to ['an-presto1001.eqiad.wmnet']:['/srv/cassandra_migration/aqs1013-b/'] (1335360082154 bytes) 2021-10-18 11:42:11 WARNING: Original size is 1335360082154 but transferred size is 1335360135402 for copy to an-presto1001.eqiad.wmnet 2021-10-18 11:42:12 INFO: Parallel checksum of source on aqs1013.eqiad.wmnet and the transmitted ones on an-presto1001.eqiad.wmnet match. 2021-10-18 11:42:13 INFO: 1335360135402 bytes correctly transferred from aqs1013.eqiad.wmnet to an-presto1001.eqiad.wmnet 2021-10-18 11:42:14 WARNING: Firewall's temporary rule could not be deleted 2021-10-18 11:42:14 INFO: Cleaning up....
Now I will delete those files from the source.
root@aqs1012:/srv/cassandra-b/tmp# rm -rf local_group_default_T_*
root@aqs1013:/srv/cassandra-b/tmp# rm -rf local_group_default_T_*
Restarted the services with: systemctl restart cassandra-b.service on aqs1012 and aqs1013.
The endpoints check is now healthy.
However, an error is shown in the logs for aqs1013-b:
ERROR [main] 2021-10-18 12:11:03,867 LogTransaction.java:492 - Unexpected disk state: failed to read transaction log [md_txn_compaction_5781ef20-2f13-11ec-9f15-87b73e7cd879.log in /srv/cassandra-b/data/local_group_default_T_pageviews_per_article_flat/data-fdc06f708b2511ebbe315f83af3c046e] Files and contents follow: /srv/cassandra-b/data/local_group_default_T_pageviews_per_article_flat/data-fdc06f708b2511ebbe315f83af3c046e/md_txn_compaction_5781ef20-2f13-11ec-9f15-87b73e7cd879.log ADD:[/srv/cassandra-b/data/local_group_default_T_pageviews_per_article_flat/data-fdc06f708b2511ebbe315f83af3c046e/md-103478-big,0,8][246899800] REMOVE:[/srv/cassandra-b/data/local_group_default_T_pageviews_per_article_flat/data-fdc06f708b2511ebbe315f83af3c046e/md-103435-big,1634450759000,8][3033021324] ***Unexpected files detected for sstable [md-103435-big-]: last update time [06:05:59] should have been [06:05:59] REMOVE:[/srv/cassandra-b/data/local_group_default_T_pageviews_per_article_flat/data-fdc06f708b2511ebbe315f83af3c046e/md-103445-big,1634451447000,8][2422083217] REMOVE:[/srv/cassandra-b/data/local_group_default_T_pageviews_per_article_flat/data-fdc06f708b2511ebbe315f83af3c046e/md-103443-big,1634451368000,8][854943471] REMOVE:[/srv/cassandra-b/data/local_group_default_T_pageviews_per_article_flat/data-fdc06f708b2511ebbe315f83af3c046e/md-103452-big,1634452064000,8][335100835] COMMIT:[,0,0][2613697770] ERROR [main] 2021-10-18 12:11:03,867 CassandraDaemon.java:749 - Cannot remove temporary or obsoleted files for local_group_default_T_pageviews_per_article_flat.data due to a problem with transaction log files. Please check records with problems in the log messages above and fix them. Refer to the 3.0 upgrading instructions in NEWS.txt for a description of transaction log files.
The documentation that is referenced says this:
New transaction log files have been introduced to replace the compactions_in_progress
system table, temporary file markers (tmp and tmplink) and sstable ancerstors.
Therefore, compaction metadata no longer contains ancestors. Transaction log files
list sstable descriptors involved in compactions and other operations such as flushing
and streaming. Use the sstableutil tool to list any sstable files currently involved
in operations not yet completed, which previously would have been marked as temporary.
A transaction log file contains one sstable per line, with the prefix "add:" or "remove:".
They also contain a special line "commit", only inserted at the end when the transaction
is committed. On startup we use these files to cleanup any partial transactions that were
in progress when the process exited. If the commit line is found, we keep new sstables
(those with the "add" prefix) and delete the old sstables (those with the "remove" prefix),
vice-versa if the commit line is missing. Should you lose or delete these log files,
both old and new sstable files will be kept as live files, which will result in duplicated
sstables. These files are protected by incremental checksums so you should not manually
edit them. When restoring a full backup or moving sstable files, you should clean-up
any left over transactions and their temporary files first. You can use this command:
sstableutil -c ks table
I have run the command provided, but all I can get is the same error message.
root@aqs1013:/srv/cassandra-b/data/local_group_default_T_pageviews_per_article_flat/data-fdc06f708b2511ebbe315f83af3c046e# export CASSANDRA_INCLUDE=/etc/cassandra.in.sh root@aqs1013:/srv/cassandra-b/data/local_group_default_T_pageviews_per_article_flat/data-fdc06f708b2511ebbe315f83af3c046e# export CASSANDRA_CONF=/etc/cassandra-b root@aqs1013:/srv/cassandra-b/data/local_group_default_T_pageviews_per_article_flat/data-fdc06f708b2511ebbe315f83af3c046e# sstableutil -c local_group_default_T_pageviews_per_article_flat data Cleanuping up... ERROR 12:40:17 Unexpected disk state: failed to read transaction log [md_txn_compaction_5781ef20-2f13-11ec-9f15-87b73e7cd879.log in /srv/cassandra-b/data/local_group_default_T_pageviews_per_article_flat/data-fdc06f708b2511ebbe315f83af3c046e] Files and contents follow: /srv/cassandra-b/data/local_group_default_T_pageviews_per_article_flat/data-fdc06f708b2511ebbe315f83af3c046e/md_txn_compaction_5781ef20-2f13-11ec-9f15-87b73e7cd879.log ADD:[/srv/cassandra-b/data/local_group_default_T_pageviews_per_article_flat/data-fdc06f708b2511ebbe315f83af3c046e/md-103478-big,0,8][246899800] REMOVE:[/srv/cassandra-b/data/local_group_default_T_pageviews_per_article_flat/data-fdc06f708b2511ebbe315f83af3c046e/md-103435-big,1634450759000,8][3033021324] ***Unexpected files detected for sstable [md-103435-big-]: last update time [06:05:59] should have been [06:05:59] REMOVE:[/srv/cassandra-b/data/local_group_default_T_pageviews_per_article_flat/data-fdc06f708b2511ebbe315f83af3c046e/md-103445-big,1634451447000,8][2422083217] REMOVE:[/srv/cassandra-b/data/local_group_default_T_pageviews_per_article_flat/data-fdc06f708b2511ebbe315f83af3c046e/md-103443-big,1634451368000,8][854943471] REMOVE:[/srv/cassandra-b/data/local_group_default_T_pageviews_per_article_flat/data-fdc06f708b2511ebbe315f83af3c046e/md-103452-big,1634452064000,8][335100835] COMMIT:[,0,0][2613697770]
I don't know whether I should try removing that line from the log file. and reloading.
As it says:
These files are protected by incremental checksums so you should not manually
edit them.
I think I might take a backup of this file and remove the 3rd line, to see if the service starts.
root@aqs1013:/srv/cassandra-b/data/local_group_default_T_pageviews_per_article_flat/data-fdc06f708b2511ebbe315f83af3c046e# cat md_txn_compaction_5781ef20-2f13-11ec-9f15-87b73e7cd879.log ADD:[/srv/cassandra-b/data/local_group_default_T_pageviews_per_article_flat/data-fdc06f708b2511ebbe315f83af3c046e/md-103478-big,0,8][246899800] REMOVE:[/srv/cassandra-b/data/local_group_default_T_pageviews_per_article_flat/data-fdc06f708b2511ebbe315f83af3c046e/md-103435-big,1634450759000,8][3033021324] REMOVE:[/srv/cassandra-b/data/local_group_default_T_pageviews_per_article_flat/data-fdc06f708b2511ebbe315f83af3c046e/md-103445-big,1634451447000,8][2422083217] REMOVE:[/srv/cassandra-b/data/local_group_default_T_pageviews_per_article_flat/data-fdc06f708b2511ebbe315f83af3c046e/md-103443-big,1634451368000,8][854943471] REMOVE:[/srv/cassandra-b/data/local_group_default_T_pageviews_per_article_flat/data-fdc06f708b2511ebbe315f83af3c046e/md-103452-big,1634452064000,8][335100835] COMMIT:[,0,0][2613697770]
However, this does run the risk of leaving duplicate sstables.
I had to remove all four of the REMOVE lines above, before the service would start successfully on aqs1013.
i.e. the transaction log replayed was:
ADD:[/srv/cassandra-b/data/local_group_default_T_pageviews_per_article_flat/data-fdc06f708b2511ebbe315f83af3c046e/md-103478-big,0,8][246899800] COMMIT:[,0,0][2613697770]
This may result in duplicated sstables, as per the documenation above.
In summary:
We need to:
The 5 snapshots that still need to be copied and deleted are:
I will start these transfers now.
btullis@cumin1001:~$ sudo transfer.py aqs1012.eqiad.wmnet:/srv/cassandra-a/tmp/local_group_default_T_pageviews_per_article_flat an-presto1001.eqiad.wmnet:/srv/cassandra_migration/aqs1012-a/
btullis@cumin1001:~$ sudo transfer.py aqs1013.eqiad.wmnet:/srv/cassandra-a/tmp/local_group_default_T_pageviews_per_article_flat an-presto1001.eqiad.wmnet:/srv/cassandra_migration/aqs1013-a/
Transfers of aqs1012-a and aqs1013-a completed successfully.
btullis@cumin1001:~$ sudo transfer.py aqs1012.eqiad.wmnet:/srv/cassandra-a/tmp/local_group_default_T_pageviews_per_article_flat an-presto1001.eqiad.wmnet:/srv/cassandra_migration/aqs1012-a/ 2021-10-18 21:02:25 INFO: About to transfer /srv/cassandra-a/tmp/local_group_default_T_pageviews_per_article_flat from aqs1012.eqiad.wmnet to ['an-presto1001.eqiad.wmnet']:['/srv/cassandra_migration/aqs1012-a/'] (1347992213935 bytes) 2021-10-18 23:25:34 WARNING: Original size is 1347992213935 but transferred size is 1347992197551 for copy to an-presto1001.eqiad.wmnet 2021-10-18 23:25:35 INFO: Parallel checksum of source on aqs1012.eqiad.wmnet and the transmitted ones on an-presto1001.eqiad.wmnet match. 2021-10-18 23:25:36 INFO: 1347992197551 bytes correctly transferred from aqs1012.eqiad.wmnet to an-presto1001.eqiad.wmnet 2021-10-18 23:25:37 WARNING: Firewall's temporary rule could not be deleted 2021-10-18 23:25:37 INFO: Cleaning up....
btullis@cumin1001:~$ sudo transfer.py aqs1013.eqiad.wmnet:/srv/cassandra-a/tmp/local_group_default_T_pageviews_per_article_flat an-presto1001.eqiad.wmnet:/srv/cassandra_migration/aqs1013-a/ 2021-10-18 21:03:02 INFO: About to transfer /srv/cassandra-a/tmp/local_group_default_T_pageviews_per_article_flat from aqs1013.eqiad.wmnet to ['an-presto1001.eqiad.wmnet']:['/srv/cassandra_migration/aqs1013-a/'] (1304018299961 bytes) 2021-10-18 23:22:59 WARNING: Original size is 1304018299961 but transferred size is 1304018230329 for copy to an-presto1001.eqiad.wmnet 2021-10-18 23:23:00 INFO: Parallel checksum of source on aqs1013.eqiad.wmnet and the transmitted ones on an-presto1001.eqiad.wmnet match. 2021-10-18 23:23:00 INFO: 1304018230329 bytes correctly transferred from aqs1013.eqiad.wmnet to an-presto1001.eqiad.wmnet 2021-10-18 23:23:01 WARNING: Firewall's temporary rule could not be deleted 2021-10-18 23:23:01 INFO: Cleaning up....
Reclaiming the space from those source volumes now.
Starting the next two transfer operations now. aqs1014-b and aqs1015-a
btullis@cumin1001:~$ sudo transfer.py aqs1014.eqiad.wmnet:/srv/cassandra-b/tmp/local_group_default_T_pageviews_per_article_flat an-presto1001.eqiad.wmnet:/srv/cassandra_migration/aqs1014-b/
btullis@cumin1001:~$ sudo transfer.py aqs1015.eqiad.wmnet:/srv/cassandra-a/tmp/local_group_default_T_pageviews_per_article_flat an-presto1001.eqiad.wmnet:/srv/cassandra_migration/aqs1015-a/
Those two transfers have completed successfully. I will now start on the final one.
btullis@cumin1001:~$ sudo transfer.py aqs1014.eqiad.wmnet:/srv/cassandra-b/tmp/local_group_default_T_pageviews_per_article_flat an-presto1001.eqiad.wmnet:/srv/cassandra_migration/aqs1014-b/ 2021-10-19 08:23:24 INFO: About to transfer /srv/cassandra-b/tmp/local_group_default_T_pageviews_per_article_flat from aqs1014.eqiad.wmnet to ['an-presto1001.eqiad.wmnet']:['/srv/cassandra_migration/aqs1014-b/'] (1349129774609 bytes) 2021-10-19 11:10:02 WARNING: Original size is 1349129774609 but transferred size is 1349129741841 for copy to an-presto1001.eqiad.wmnet 2021-10-19 11:10:03 INFO: Parallel checksum of source on aqs1014.eqiad.wmnet and the transmitted ones on an-presto1001.eqiad.wmnet match. 2021-10-19 11:10:04 INFO: 1349129741841 bytes correctly transferred from aqs1014.eqiad.wmnet to an-presto1001.eqiad.wmnet 2021-10-19 11:10:05 WARNING: Firewall's temporary rule could not be deleted 2021-10-19 11:10:05 INFO: Cleaning up....
btullis@cumin1001:~$ sudo transfer.py aqs1015.eqiad.wmnet:/srv/cassandra-a/tmp/local_group_default_T_pageviews_per_article_flat an-presto1001.eqiad.wmnet:/srv/cassandra_migration/aqs1015-a/ 2021-10-19 08:24:35 INFO: About to transfer /srv/cassandra-a/tmp/local_group_default_T_pageviews_per_article_flat from aqs1015.eqiad.wmnet to ['an-presto1001.eqiad.wmnet']:['/srv/cassandra_migration/aqs1015-a/'] (1346240104063 bytes) 2021-10-19 11:26:16 WARNING: Original size is 1346240104063 but transferred size is 1346240108159 for copy to an-presto1001.eqiad.wmnet 2021-10-19 11:26:17 INFO: Parallel checksum of source on aqs1015.eqiad.wmnet and the transmitted ones on an-presto1001.eqiad.wmnet match. 2021-10-19 11:26:18 INFO: 1346240108159 bytes correctly transferred from aqs1015.eqiad.wmnet to an-presto1001.eqiad.wmnet 2021-10-19 11:26:19 WARNING: Firewall's temporary rule could not be deleted 2021-10-19 11:26:19 INFO: Cleaning up....
This is running now.
btullis@cumin1001:~$ sudo transfer.py aqs1015.eqiad.wmnet:/srv/cassandra-b/tmp/local_group_default_T_pageviews_per_article_flat an-presto1001.eqiad.wmnet:/srv/cassandra_migration/aqs1015-b/
The sixth and final snapshot that we still need to load has now been transferred to an-presto1001.
btullis@cumin1001:~$ sudo transfer.py aqs1015.eqiad.wmnet:/srv/cassandra-b/tmp/local_group_default_T_pageviews_per_article_flat an-presto1001.eqiad.wmnet:/srv/cassandra_migration/aqs1015-b/ 2021-10-19 13:27:19 INFO: About to transfer /srv/cassandra-b/tmp/local_group_default_T_pageviews_per_article_flat from aqs1015.eqiad.wmnet to ['an-presto1001.eqiad.wmnet']:['/srv/cassandra_migration/aqs1015-b/'] (1334101610937 bytes) 2021-10-19 17:29:23 WARNING: Original size is 1334101610937 but transferred size is 1334101627321 for copy to an-presto1001.eqiad.wmnet 2021-10-19 17:29:24 INFO: Parallel checksum of source on aqs1015.eqiad.wmnet and the transmitted ones on an-presto1001.eqiad.wmnet match. 2021-10-19 17:29:24 INFO: 1334101627321 bytes correctly transferred from aqs1015.eqiad.wmnet to an-presto1001.eqiad.wmnet 2021-10-19 17:29:25 WARNING: Firewall's temporary rule could not be deleted 2021-10-19 17:29:25 INFO: Cleaning up....
I can now reclaim all of the remaining space that these snapshots were using on the aqs_next cluster.
There are still compactions running on the new cluster, although they have almost completed. We have decided to wait until they have completely finished before running any more loading operations.
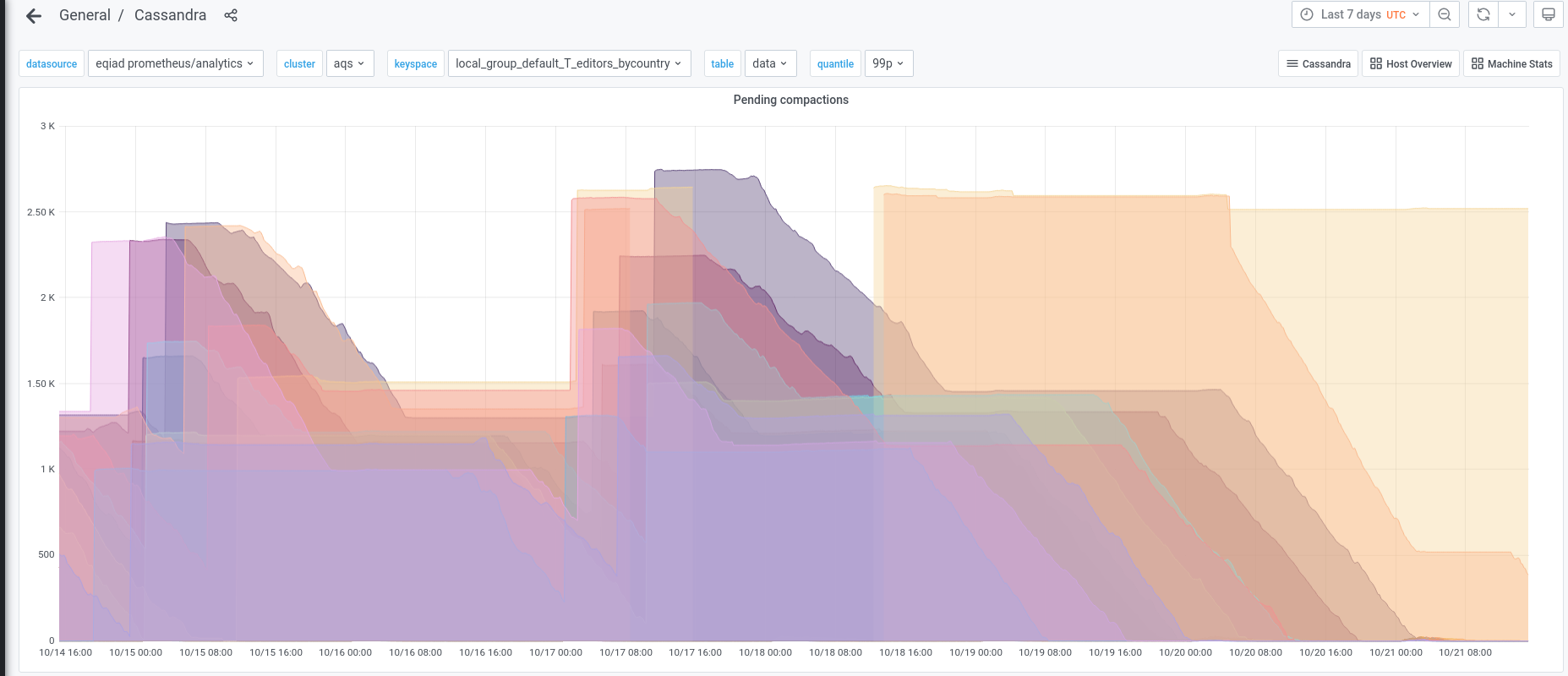
Compactions from previous operations have now completely finished, so it now back to a regular daily pattern.
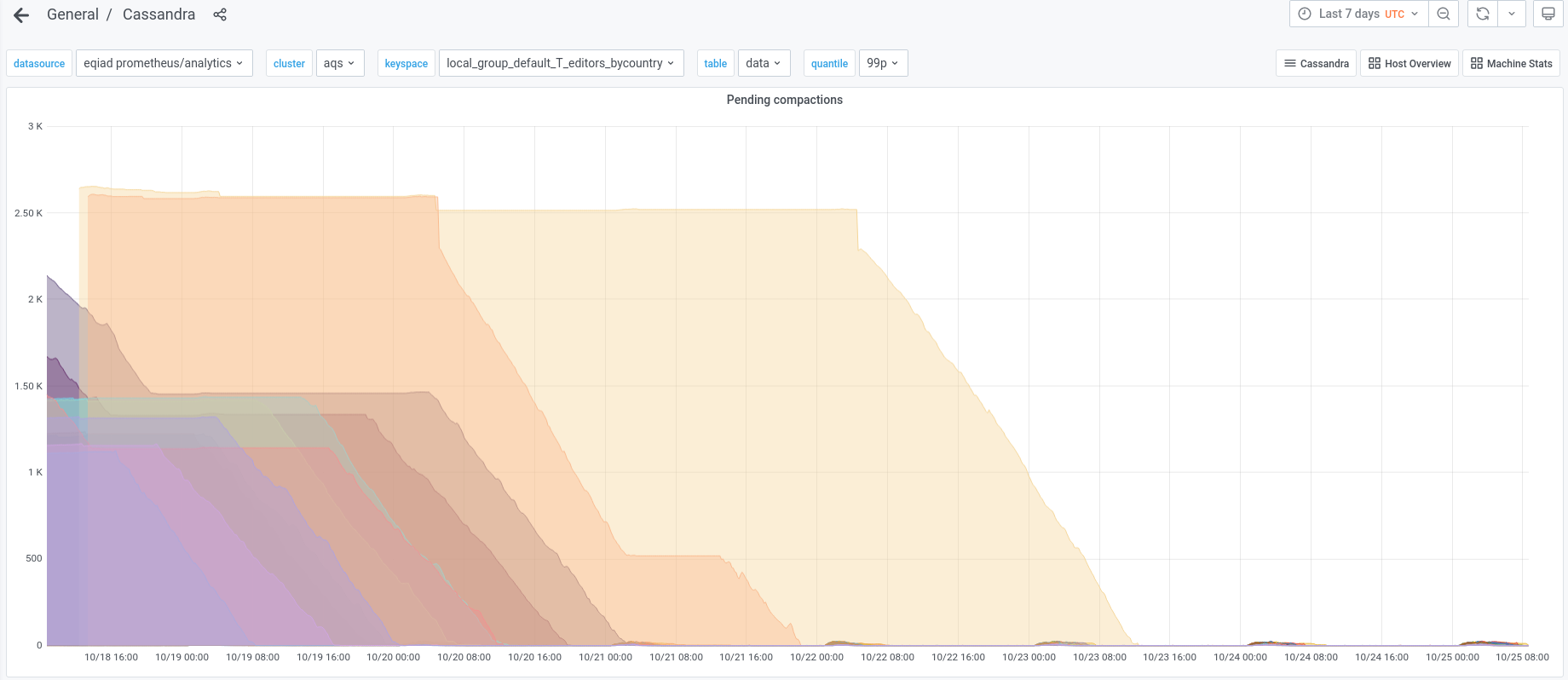
aqs1012-a aqs1013-a aqs1013-b aqs1014-b aqs1015-a aqs1015-b
This is under way now.
### Reloading table data in keyspace local_group_default_T_pageviews_per_article_flat from snapshot aqs1012.eqiad.wmnet instance a
I had a slight issue because I was trying to use an sstableloader command from cassandra2 to load to cassandra 3.
Once I did this, everything was OK:
btullis@an-presto1001:~/cassandra$ wget https://apt.wikimedia.org/wikimedia/pool/component/cassandra311/c/cassandra/cassandra_3.11.4_all.deb btullis@an-presto1001:~/cassandra$ dpkg-deb -x cassandra_3.11.4_all.deb .
The new sstableloader version worked with the updated loader script.
Unfortunately, this failed with a streaming error to all peers.
ERROR 15:24:06,580 [Stream #28804bf0-35a7-11ec-8975-cdf3bbce68ef] Streaming error occurred on session with peer 10.64.32.128 ERROR 15:24:06,580 [Stream #28804bf0-35a7-11ec-8975-cdf3bbce68ef] Streaming error occurred on session with peer 10.64.32.145 ERROR 15:24:06,580 [Stream #28804bf0-35a7-11ec-8975-cdf3bbce68ef] Streaming error occurred on session with peer 10.64.0.120 ERROR 15:24:06,580 [Stream #28804bf0-35a7-11ec-8975-cdf3bbce68ef] Streaming error occurred on session with peer 10.64.16.206 ERROR 15:24:06,580 [Stream #28804bf0-35a7-11ec-8975-cdf3bbce68ef] Streaming error occurred on session with peer 10.64.32.147 ERROR 15:24:06,580 [Stream #28804bf0-35a7-11ec-8975-cdf3bbce68ef] Streaming error occurred on session with peer 10.64.48.68 ERROR 15:24:06,580 [Stream #28804bf0-35a7-11ec-8975-cdf3bbce68ef] Streaming error occurred on session with peer 10.64.48.65 ERROR 15:24:06,580 [Stream #28804bf0-35a7-11ec-8975-cdf3bbce68ef] Streaming error occurred on session with peer 10.64.0.88 ERROR 15:24:06,579 [Stream #28804bf0-35a7-11ec-8975-cdf3bbce68ef] Streaming error occurred on session with peer 10.64.32.146 ERROR 15:24:06,580 [Stream #28804bf0-35a7-11ec-8975-cdf3bbce68ef] Streaming error occurred on session with peer 10.64.48.69 ERROR 15:24:06,580 [Stream #28804bf0-35a7-11ec-8975-cdf3bbce68ef] Streaming error occurred on session with peer 10.64.48.67 ERROR 15:24:06,580 [Stream #28804bf0-35a7-11ec-8975-cdf3bbce68ef] Streaming error occurred on session with peer 10.64.16.204
This would suggest that it's a firewall related issue. I will continue to investigate.
Ah, I found this from the docs:
Because sstableloader uses the streaming protocol, it requires a direct connection over port 7000 (storage port) to each connected node.
I will need to add a rule for this port, as I had only checked the availability of the CQL port.
Change 734609 had a related patch set uploaded (by Btullis; author: Btullis):
[operations/puppet@production] Add a temporary firewall rule to support cassandra3 migration
I have now created a patch to open port 7000 on the aqs_next servers to an-presto1001. https://gerrit.wikimedia.org/r/c/operations/puppet/+/734609
Change 734609 merged by Btullis:
[operations/puppet@production] Add a temporary firewall rule to support cassandra3 migration
Change 734643 had a related patch set uploaded (by Btullis; author: Btullis):
[operations/homer/public@master] Add access to port 7000 on aqs_group temporarily
Change 734643 merged by jenkins-bot:
[operations/homer/public@master] Add access to port 7000 on aqs_group temporarily
At last, loading of snapshot 7 of 12 is now under way.
progress: [/10.64.32.128]0:0/2131 0 % [/10.64.32.145]0:0/2750 0 % [/10.64.48.65]0:0/2470 0 % [/10.64.32.146]0:0/2124 0 % [/10.64.32.147]0:0/2509 0 % [/10.64.48.67]0:0/1373 0 % [/10.64.48.68]0:0/2180 0 % [/10.64.48.69]0:1/1752 0 % [/10.64.0.120]0:0/1984 0 % [/10.64.0.88]0:0/2146 0 % [/10.64.16.204]0:0/2596 0 % [/10.64.16.206]0:0/2333 0 % total: 0% 25.068MiB/s (avg: 1.319MiB/s)
I had to enable not only the ferm rule on the aqs_next nodes, but also I had to add port 7000 to the policy on homer, to configure the network devices with temporary access for port 7000.
The loading of snapshot 7 completed successfully:
progress: [/10.64.32.128]0:2131/2131 100% [/10.64.32.145]0:2750/2750 100% [/10.64.48.65]0:2470/2470 100% [/10.64.32.146]0:2124/2124 100% [/10.64.32.147]0:2509/2509 100% [/10.64.48.67]0:1373/1373 100% [/10.64.48.68]0:2180/2180 100% [/10.64.48.69]0:1752/1752 100% [/10.64.0.120]0:1984/1984 100% [/10.64.0.88]0:2146/2146 100% [/10.64.16.204]0:2596/2596 100% [/10.64.16.206]0:2333/2333 100% total: 100% 0.000KiB/s (avg: 21.651MiB/s)
Summary statistics:
Connections per host : 1
Total files transferred : 26348
Total bytes transferred : 3503.810GiB
Total duration : 165716971 ms
Average transfer rate : 21.651MiB/s
Peak transfer rate : 24.970MiB/s
================
PASS |████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 100% (1/1) [46:01:59<00:00, 165719.51s/hosts]
FAIL | | 0% (0/1) [46:01:59<?, ?hosts/s]
100.0% (1/1) success ratio (>= 100.0% threshold) for command: 'MAX_HEAP_SIZE=8G...rticle_flat/data'.
100.0% (1/1) success ratio (>= 100.0% threshold) of nodes successfully executed all commands.@JAllemandou and I have discussed and have decided to wait until the compactions are complete from this operation, before starting the next loading operation.
All compactions from the 7th snapshot loading operation have completed successfully. Starting the 8th snapshot loading operation now.
This is the snapshot from aqs1013-a.
### Reloading table data in keyspace local_group_default_T_pageviews_per_article_flat from snapshot aqs1013.eqiad.wmnet instance a
All compactions from the previous load have completed.
Starting the reload of the 9th snapshot now.
### Reloading table data in keyspace local_group_default_T_pageviews_per_article_flat from snapshot aqs1013.eqiad.wmnet instance b
All compactions from the 9th snapshot loading operation have completed.
Starting the reload of the 10th snapshot now.
### Reloading table data in keyspace local_group_default_T_pageviews_per_article_flat from snapshot aqs1014.eqiad.wmnet instance b
The 10th snapshot has finished loading and compactions are now in progress from all 12 instances.
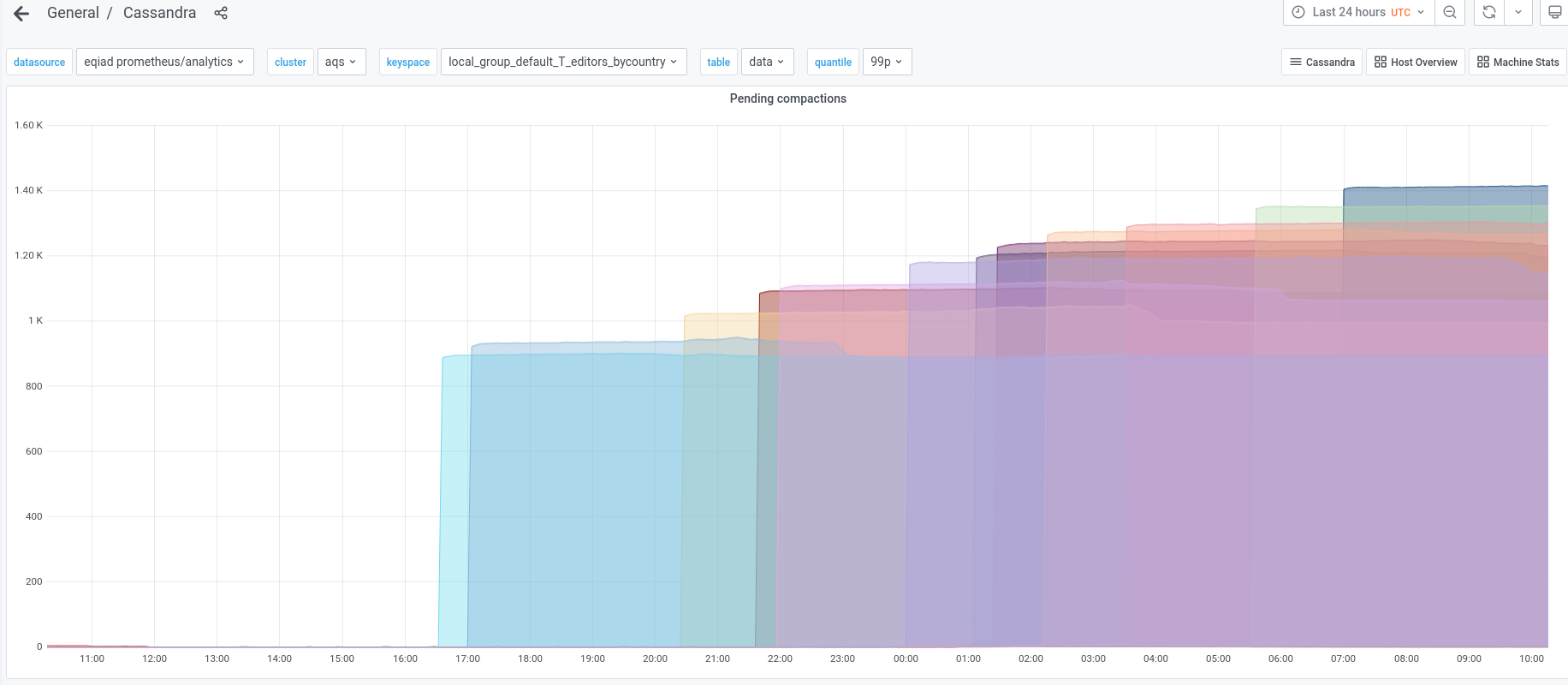
Commancing reloading of the 11th snapshot.
### Reloading table data in keyspace local_group_default_T_pageviews_per_article_flat from snapshot aqs1015.eqiad.wmnet instance a
Loading of the 11th snapshot has finished successfully and all instances are now compacting.
All compactions for the 11th snapshot have completed.
### Reloading table data in keyspace local_group_default_T_pageviews_per_article_flat from snapshot aqs1015.eqiad.wmnet instance b
The 12th snapshot has finished loading.
progress: [/10.64.32.128]0:2090/2090 100% [/10.64.48.65]0:2377/2377 100% [/10.64.32.145]0:2220/2220 100% [/10.64.32.146]0:2286/2286 100% [/10.64.32.147]0:2219/2219 100% [/10.64.48.67]0:1725/1725 100% [/10.64.48.68]0:2057/2057 100% [/10.64.48.69]0:2047/2047 100% [/10.64.0.88]0:2128/2128 100% [/10.64.0.120]0:1845/1845 100% [/10.64.16.204]0:2293/2293 100% [/10.64.16.206]0:2046/2046 100% total: 100% 0.000KiB/s (avg: 23.014MiB/s) Summary statistics: Connections per host : 1 Total files transferred : 25333 Total bytes transferred : 3473.173GiB Total duration : 154537770 ms Average transfer rate : 23.014MiB/s Peak transfer rate : 24.924MiB/s
Compactions have started on this table, but I believe that we can start the QA process on this now, or we can wait for the compactions to finish before doing so.
I'll reassign to @JAllemandou for him to decide on that point and schedule the QA accordingly.
QA done on 4 million points per day on 4 files, one of them being a know problematic day from datasources. No difference to be found on both clusters, with the confirmation of data being problematic on the expected day as using cassandra LOCAL_ONE default leads to missing data on the old cluster (not the new one), and using LOCAL_QUORUM makes old and new match exactly.
Change 759546 had a related patch set uploaded (by Btullis; author: Btullis):
[operations/homer/public@master] Remove temporary additional port for AQS servers.
Change 759546 merged by jenkins-bot:
[operations/homer/public@master] Remove temporary additional port for AQS servers.