Write the description below
From alertmanager:
alertname: PuppetAgentFailure project: tools summary: Puppet agent failure detected on instance tools-k8s-worker-53 in project tools 6 hours ago instance: tools-k8s-worker-53 job: node severity: warn
| dcaro | |
| Sep 22 2021, 8:56 AM |
| F34650716: 2021-09-22T11:27:52,285520659+02:00.png | |
| Sep 22 2021, 9:42 AM |
From alertmanager:
alertname: PuppetAgentFailure project: tools summary: Puppet agent failure detected on instance tools-k8s-worker-53 in project tools 6 hours ago instance: tools-k8s-worker-53 job: node severity: warn
Also from the email:
Date: Wed, 22 Sep 2021 08:15:07 +0000
From: root <root@tools.wmflabs.org>
To: dcaro@wikimedia.org
Subject: [Cloud VPS alert][tools] Puppet failure on tools-k8s-worker-53.tools.eqiad.wmflabs (172.16.1.128)
Puppet is having issues on the "tools-k8s-worker-53.tools.eqiad.wmflabs (172.16.1.128)" instance in project
tools in Wikimedia Cloud VPS.
Puppet is running with failures.
Working Puppet runs are needed to maintain instance security and logins.
As long as Puppet continues to fail, this system is in danger of becoming
unreachable.
You are receiving this email because you are listed as member for the
project that contains this instance. Please take steps to repair
this instance or contact a Cloud VPS admin for assistance.
If your host is expected to fail puppet runs and you want to disable this
alert, you can create a file under /.no-puppet-checks, that will skip the checks.
You might find some help here:
https://wikitech.wikimedia.org/wiki/Portal:Cloud_VPS/Admin/Runbooks/Cloud_VPS_alert_Puppet_failure_on
For further support, visit #wikimedia-cloud on libera.chat or
<https://wikitech.wikimedia.org>
Some extra info follows:
---- Last run summary:
changes: {total: 1}
events: {failure: 2, success: 1, total: 3}
resources: {changed: 1, corrective_change: 2, failed: 2, failed_to_restart: 0, out_of_sync: 3,
restarted: 0, scheduled: 0, skipped: 30, total: 656}
time: {augeas: 0.014297675, catalog_application: 167.13470970466733, config_retrieval: 4.7948452569544315,
convert_catalog: 0.39457596093416214, exec: 160.45495918400005, fact_generation: 1.1547216065227985,
file: 2.7668943010000007, file_line: 0.009206697000000002, filebucket: 0.000101214,
group: 0.000973877, host: 0.000516996, last_run: 1632297098, mailalias: 0.000729282,
mount: 0.005470849, node_retrieval: 0.28941362351179123, notify: 0.004017614, package: 1.4282494300000002,
plugin_sync: 0.5997322611510754, schedule: 0.000672459, service: 0.9838402580000001,
tidy: 0.000157168, total: 174.38122133, transaction_evaluation: 167.0233521424234,
user: 0.001699015}
version: {config: "(429cfa2180) Moritz M\xFChlenhoff - dhcp: Switch mx1001 to bullseye",
puppet: 5.5.10}
---- Failed resources if any:
* Exec[create-/mnt/nfs/labstore-secondary-tools-home]
* Exec[create-/mnt/nfs/labstore-secondary-tools-project]
---- Exceptions that happened when running the script if any:
No exceptions happened.Manually sshing and running puppet worked though:
root@tools-k8s-worker-53:~# puppet agent --test Info: Using configured environment 'production' Info: Retrieving pluginfacts Info: Retrieving plugin Info: Retrieving locales Info: Loading facts Info: Caching catalog for tools-k8s-worker-53.tools.eqiad.wmflabs Info: Applying configuration version '(385872e29c) Arturo Borrero Gonzalez - openstack: manila: install manila-data package' Notice: The LDAP client stack for this host is: sssd/sudo Notice: /Stage[main]/Profile::Ldap::Client::Labs/Notify[LDAP client stack]/message: defined 'message' as 'The LDAP client stack for this host is: sssd/sudo' Notice: Applied catalog in 7.43 seconds
That was after it was taken out of the pool though. Looking...
It seems that something happened at ~2:36:
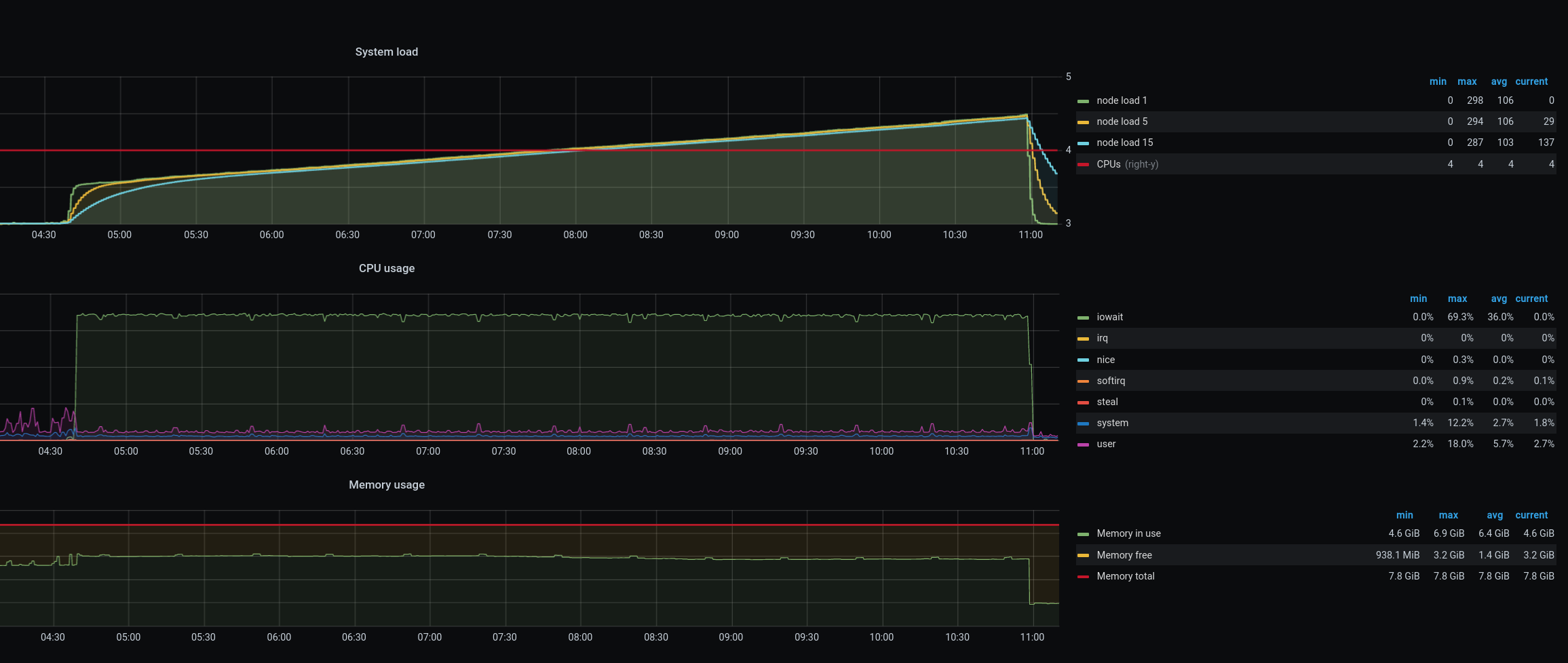
That timestamp matches with an invocation of the OOM killer (note that dmesg times are not accurate, times from journalctl are):
Sep 22 02:36:18 tools-k8s-worker-53 kernel: python invoked oom-killer: gfp_mask=0x6000c0(GFP_KERNEL), nodemask=(null), order=0, oom_score_adj=968 Sep 22 02:36:18 tools-k8s-worker-53 kernel: python cpuset=docker-dc657872f2a8e8d33afb07ae86e268412f78e59db1bc2dc4c1fe9e4d7c3a5137.scope mems_allowed=0 ... Sep 22 02:36:18 tools-k8s-worker-53 kernel: Task in /kubepods.slice/kubepods-burstable.slice/kubepods-burstable-podb18a021d_3812_41b0_9117_50d7a97e0f31.slice/docker-dc657872f2a8e8d33afb07ae86e268412f78e59db1bc2dc4c1fe9e4d7c3a5137.scope killed as a result of limit of /kubepods.slice/kubepods-burstable.slice/kubepods-burstable.slice/kubepods-burstable-podb18a021d_3812_41b0_9117_50d7a97e0f31.slice
Mentioned in SAL (#wikimedia-cloud) [2021-09-22T11:37:01Z] <dcaro> controlled undrain tools-k8s-worker-53 (T291546)