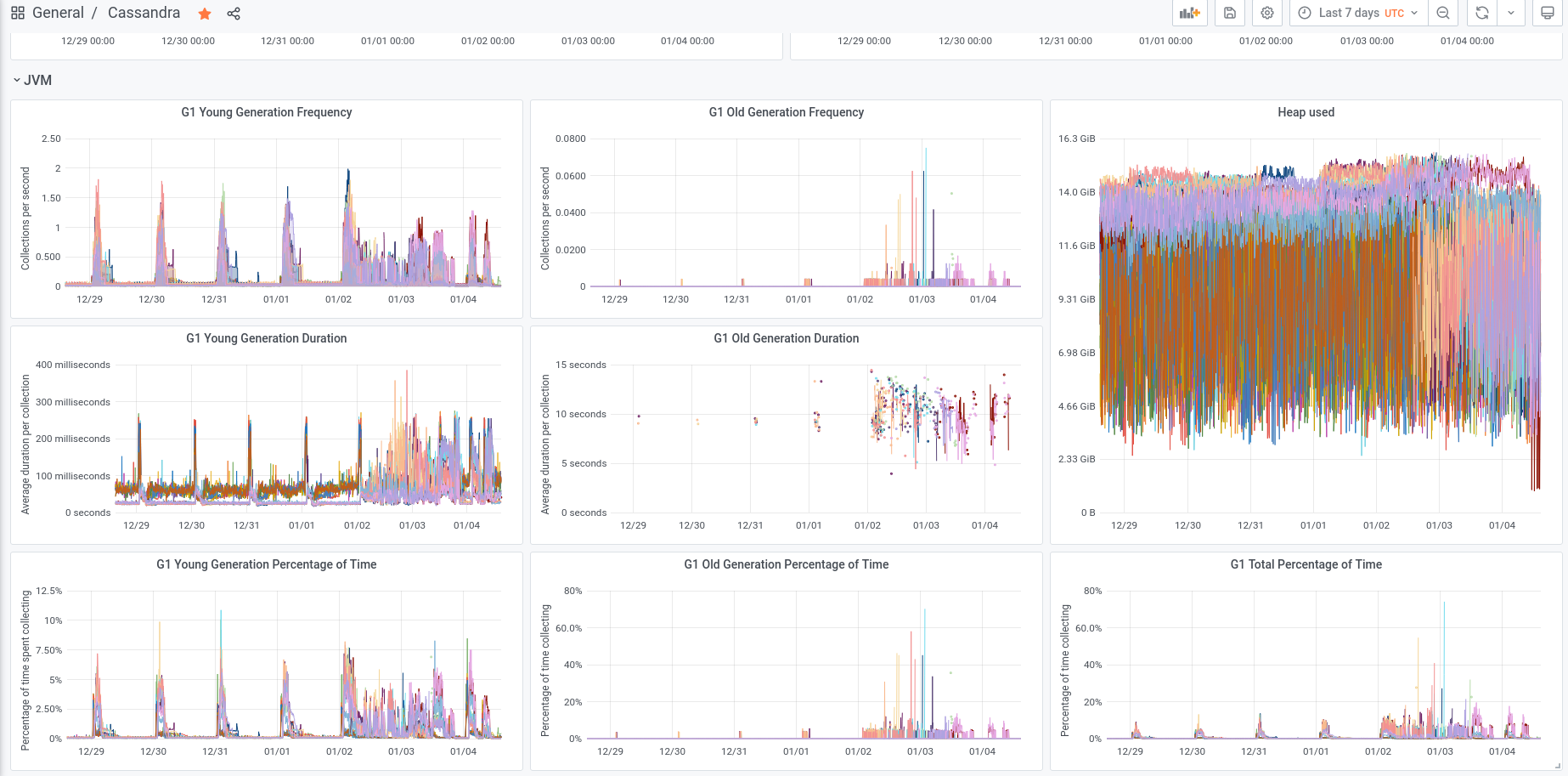
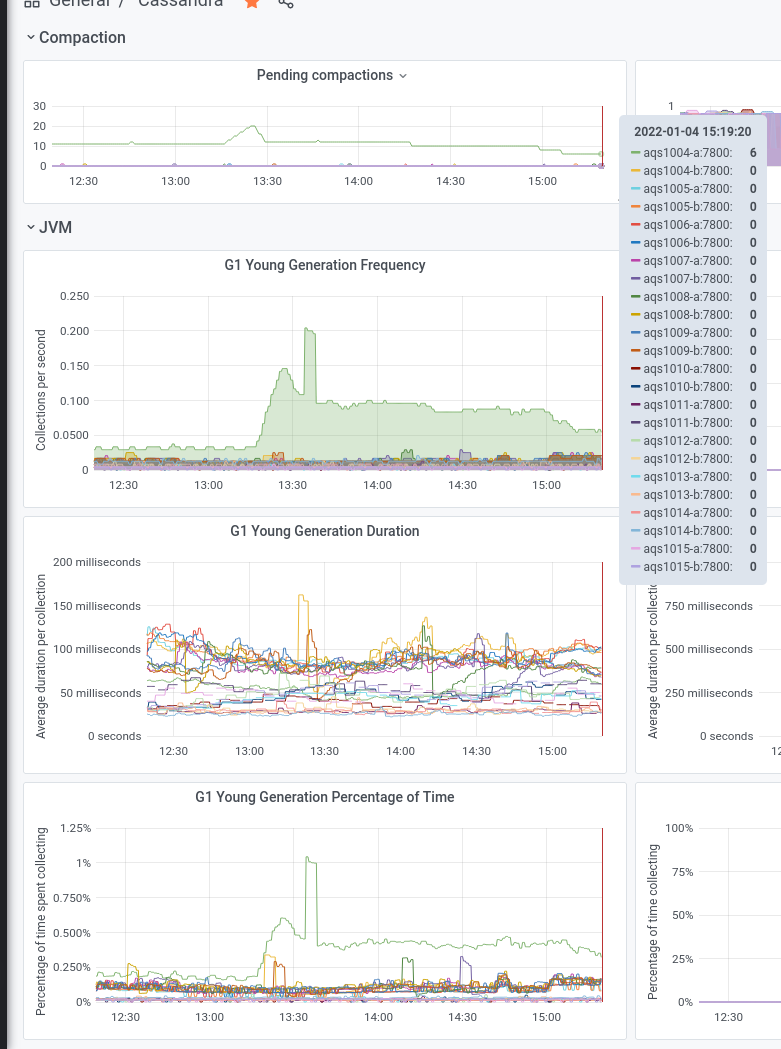
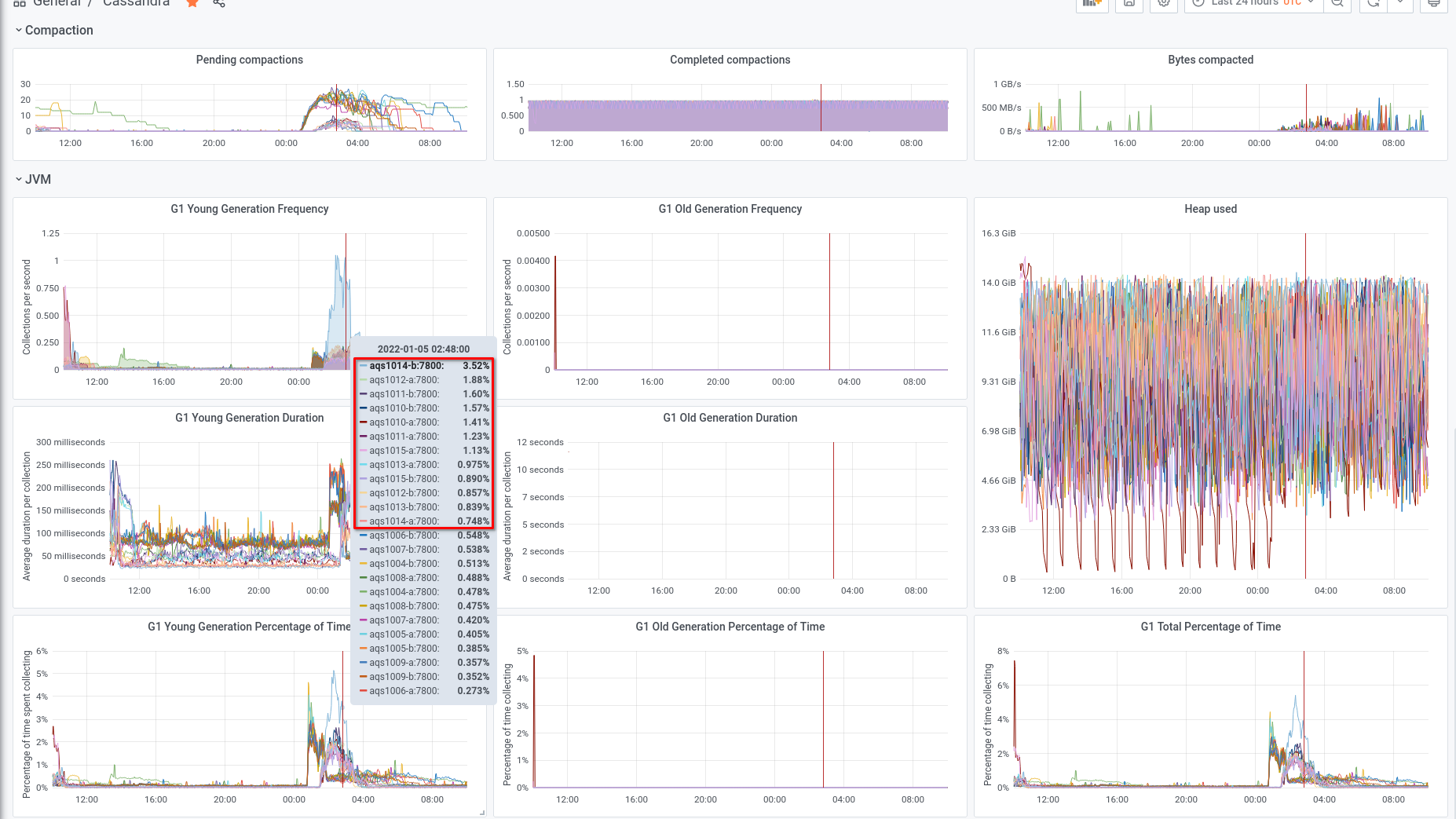
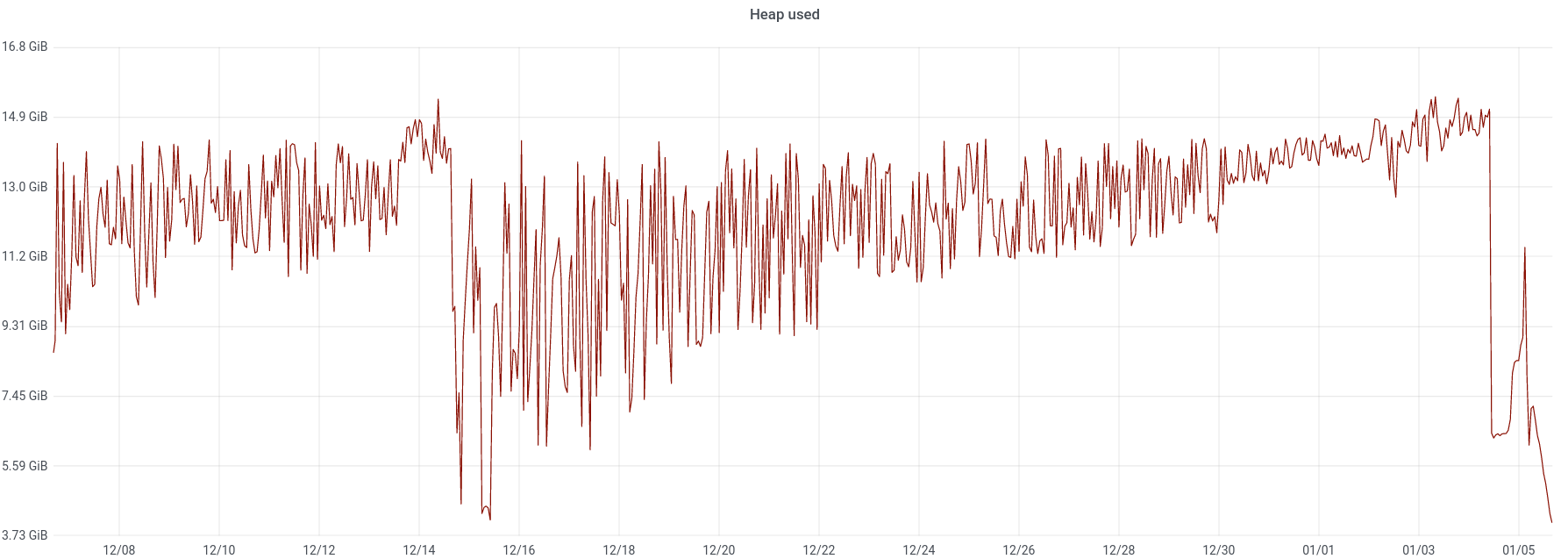
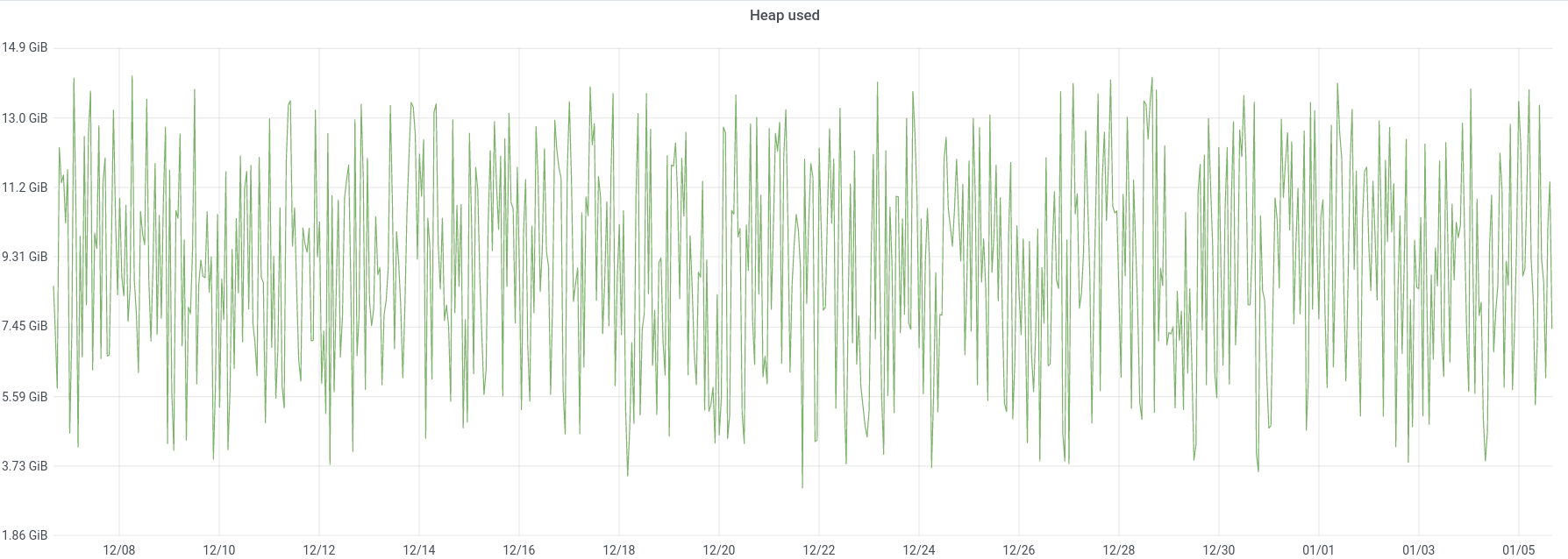
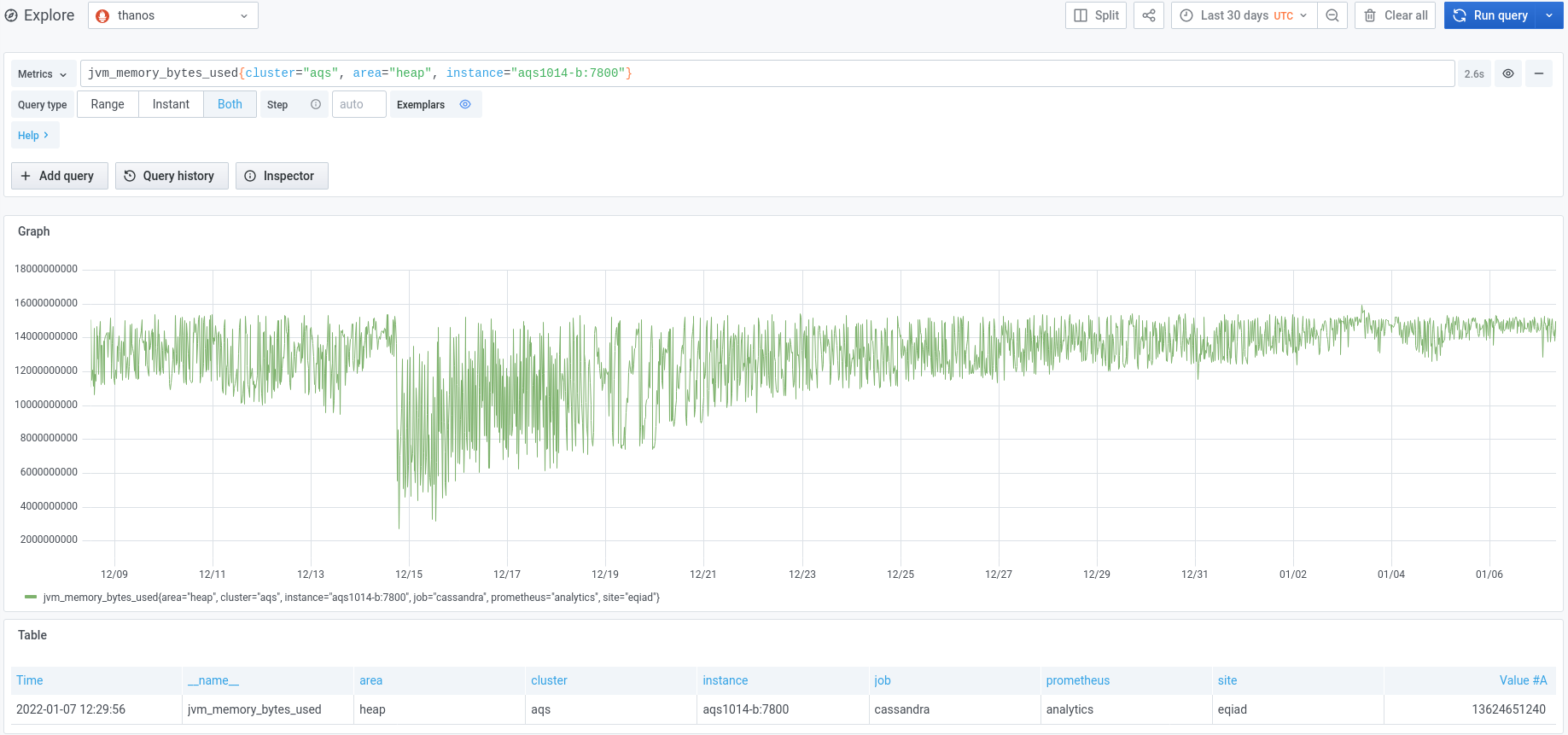
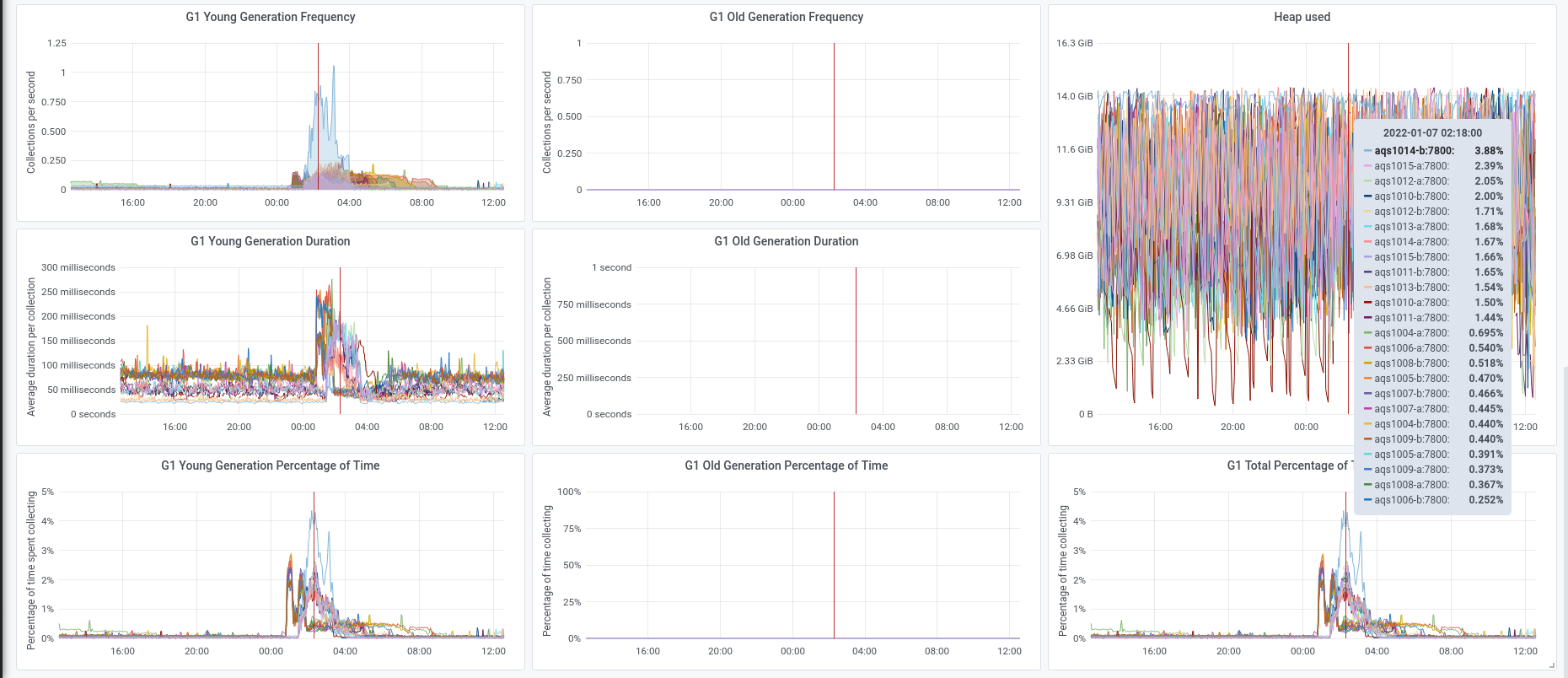
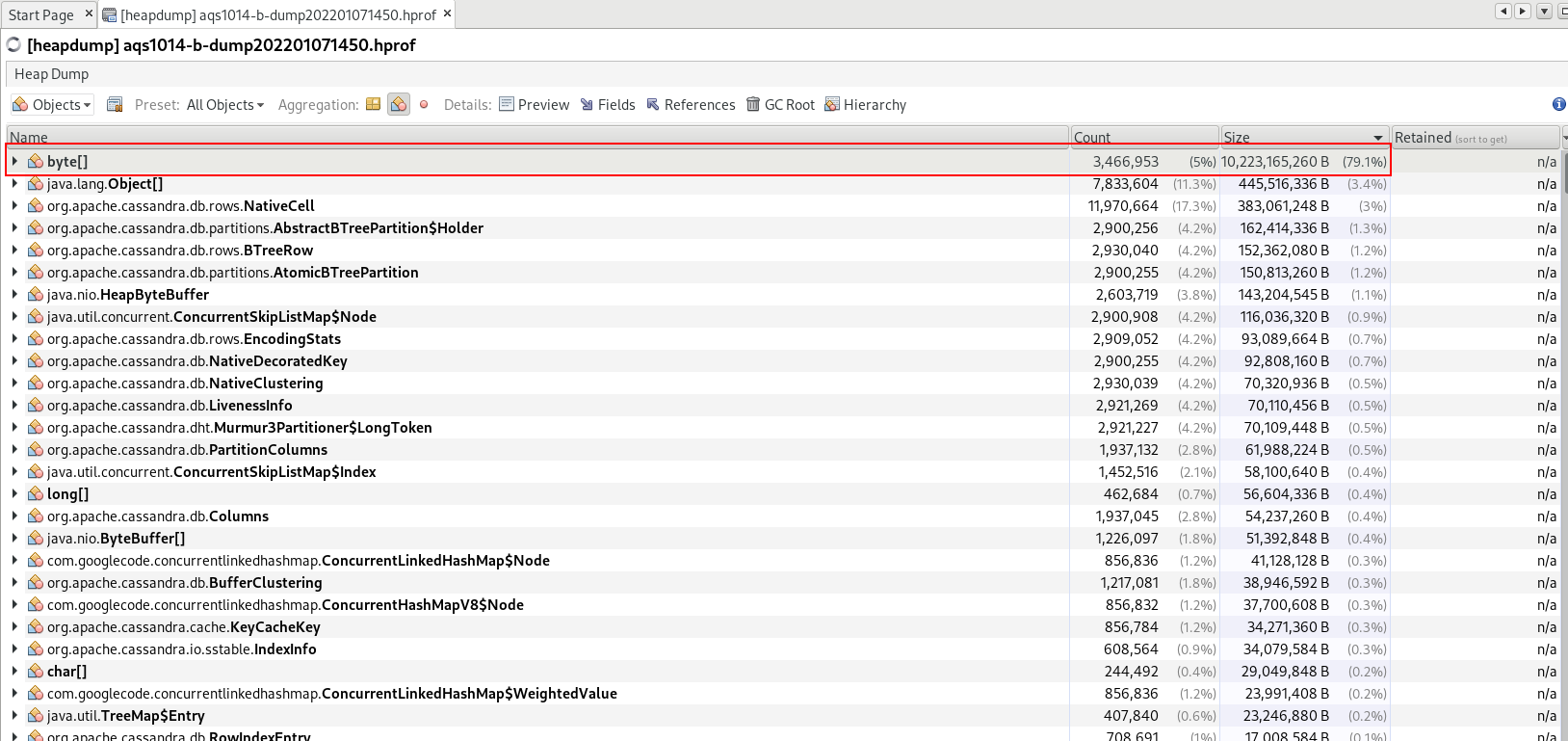
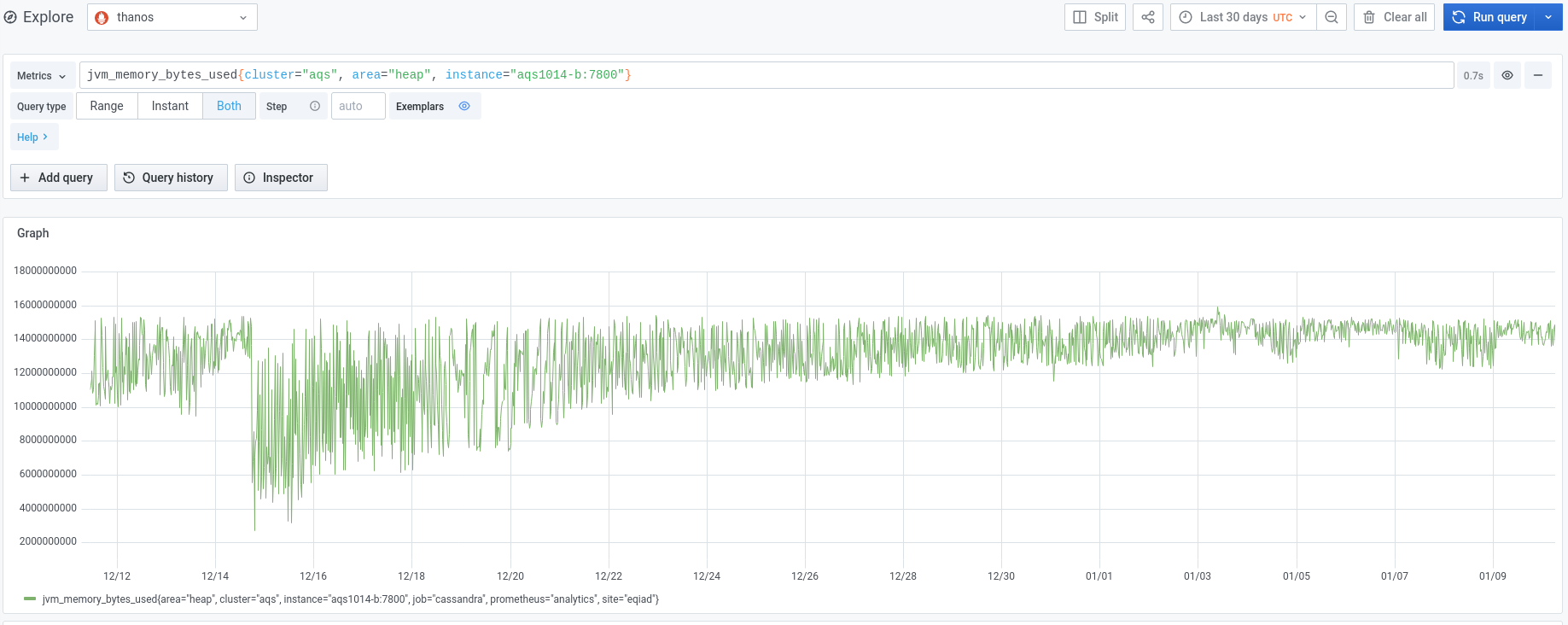
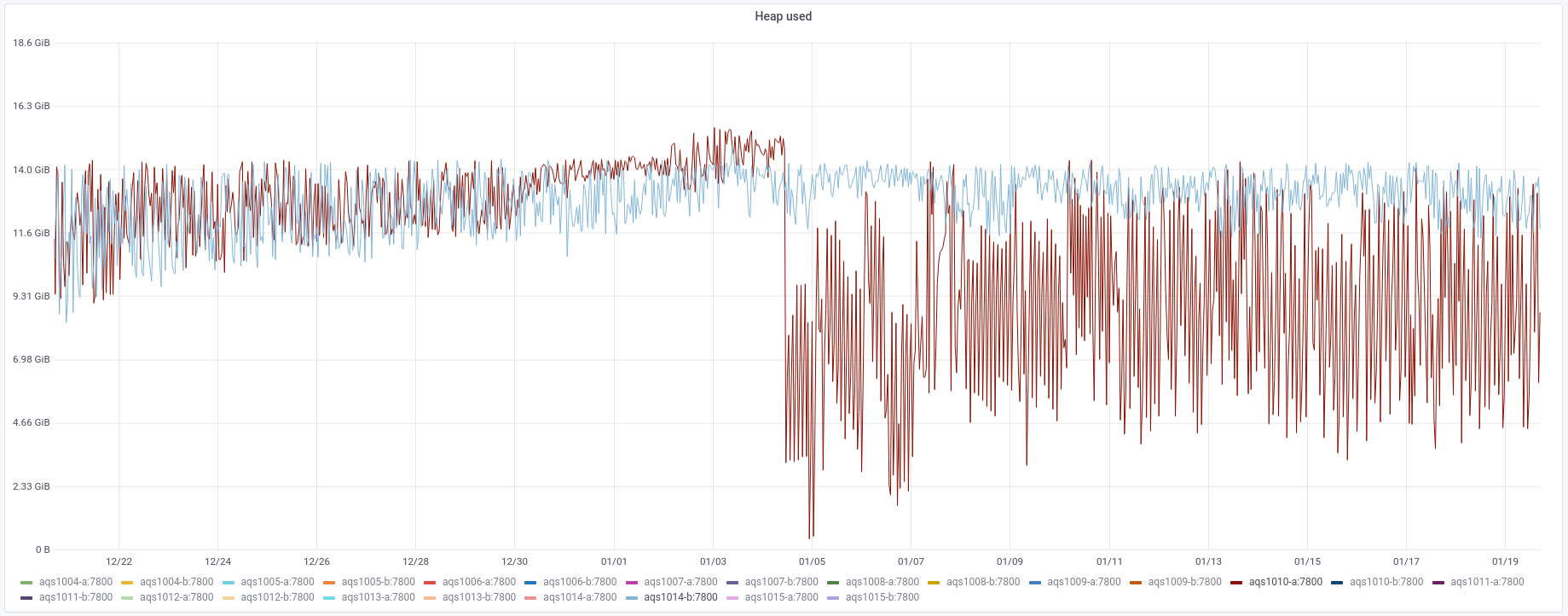
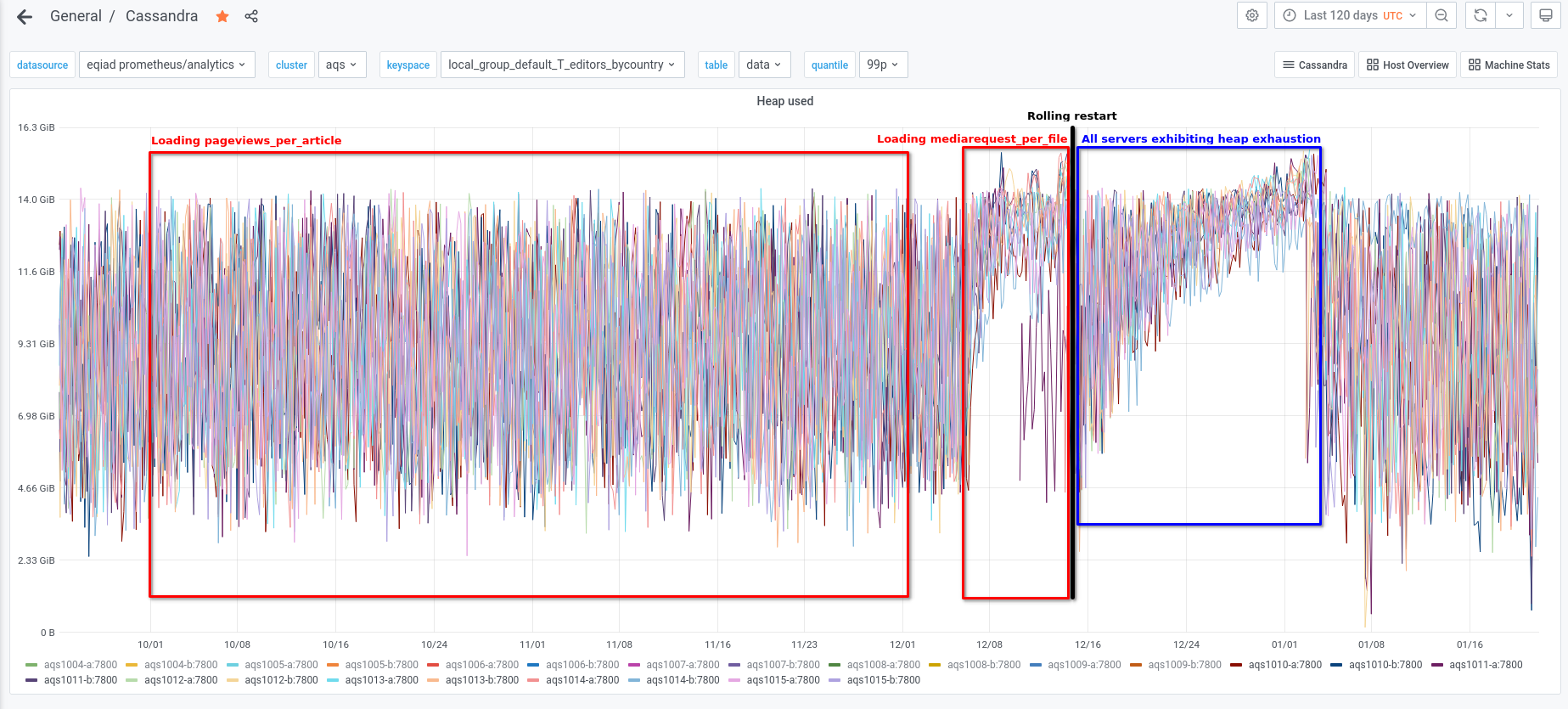
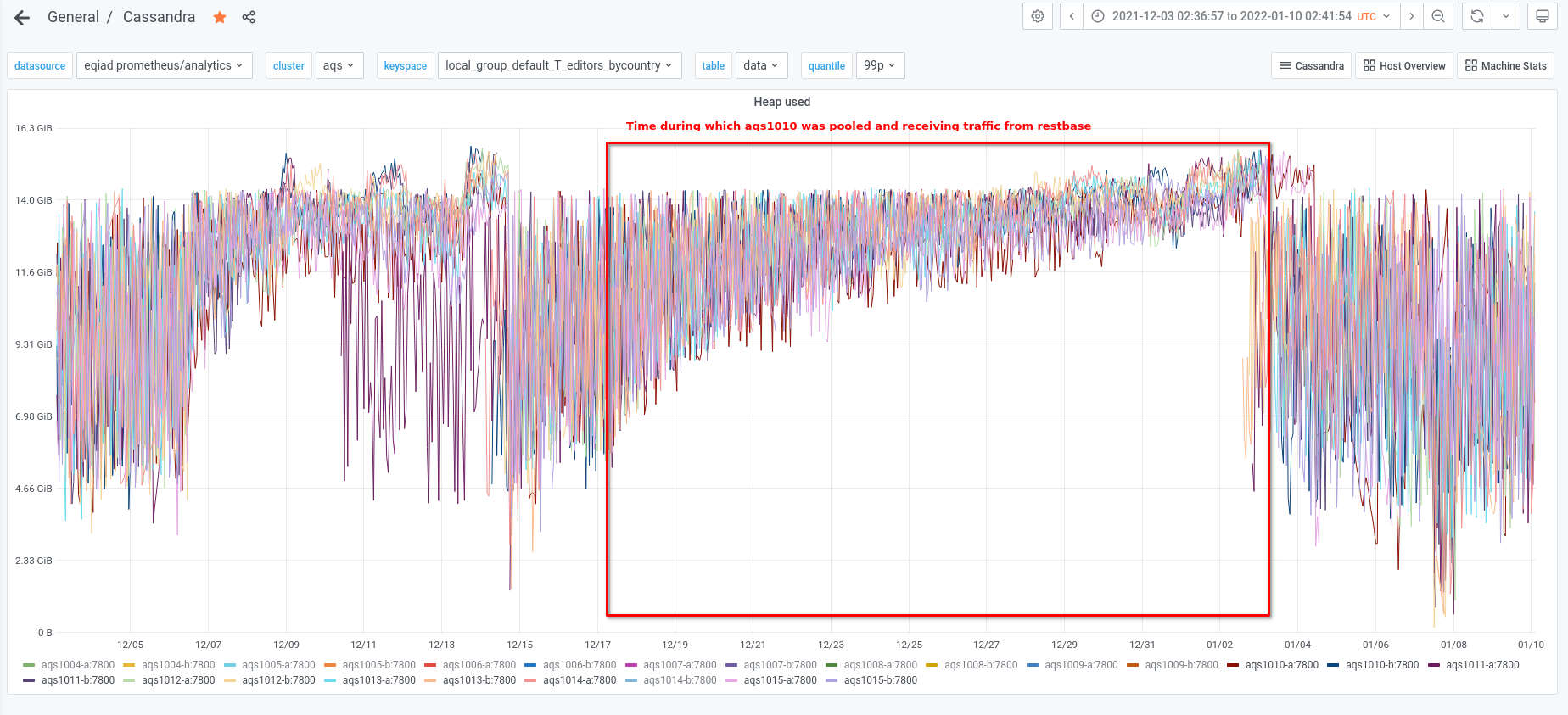
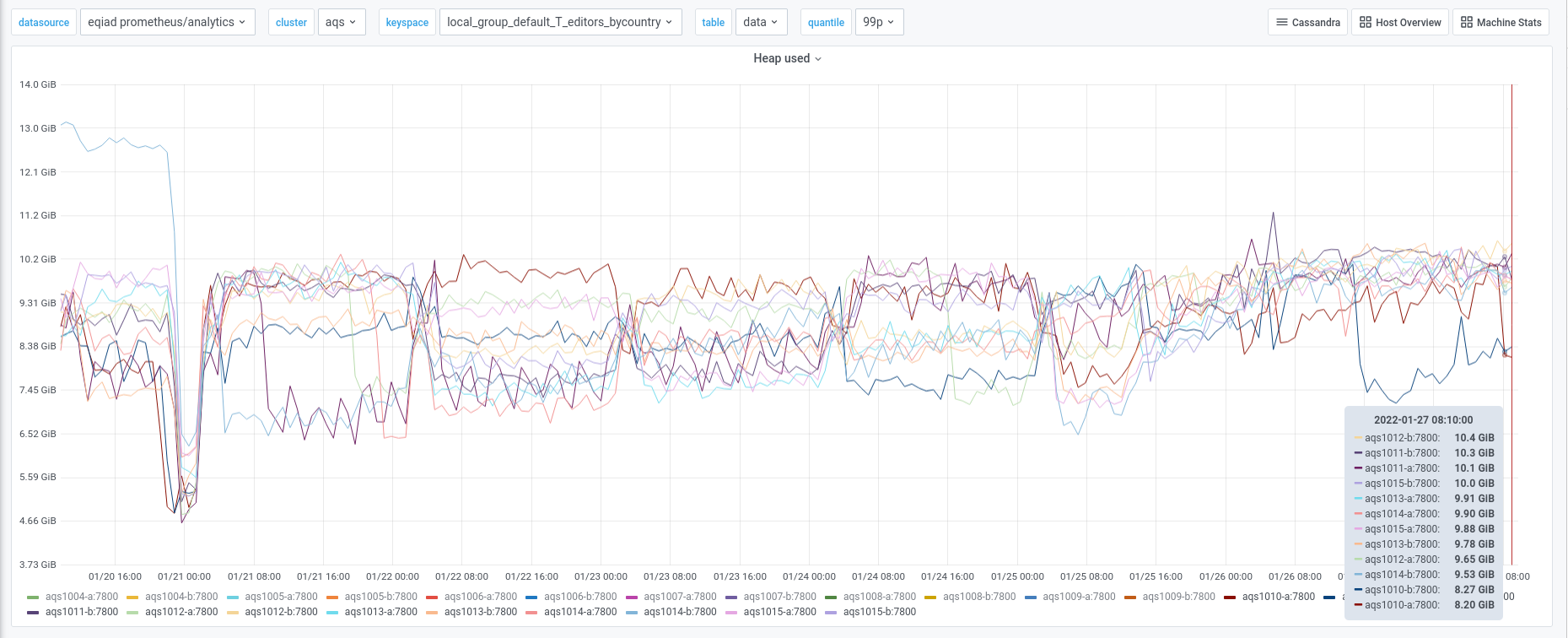
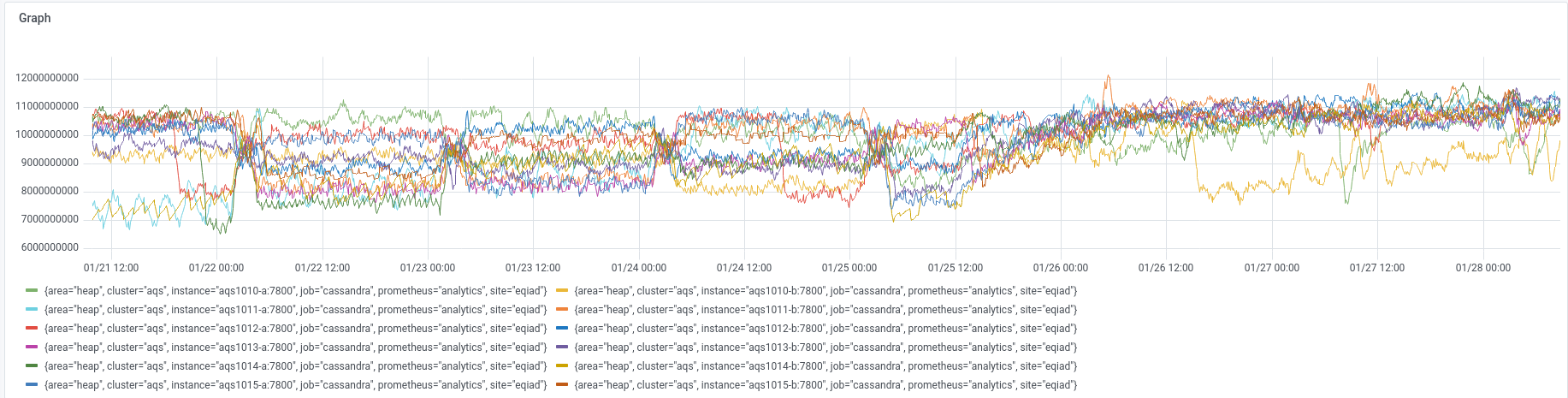
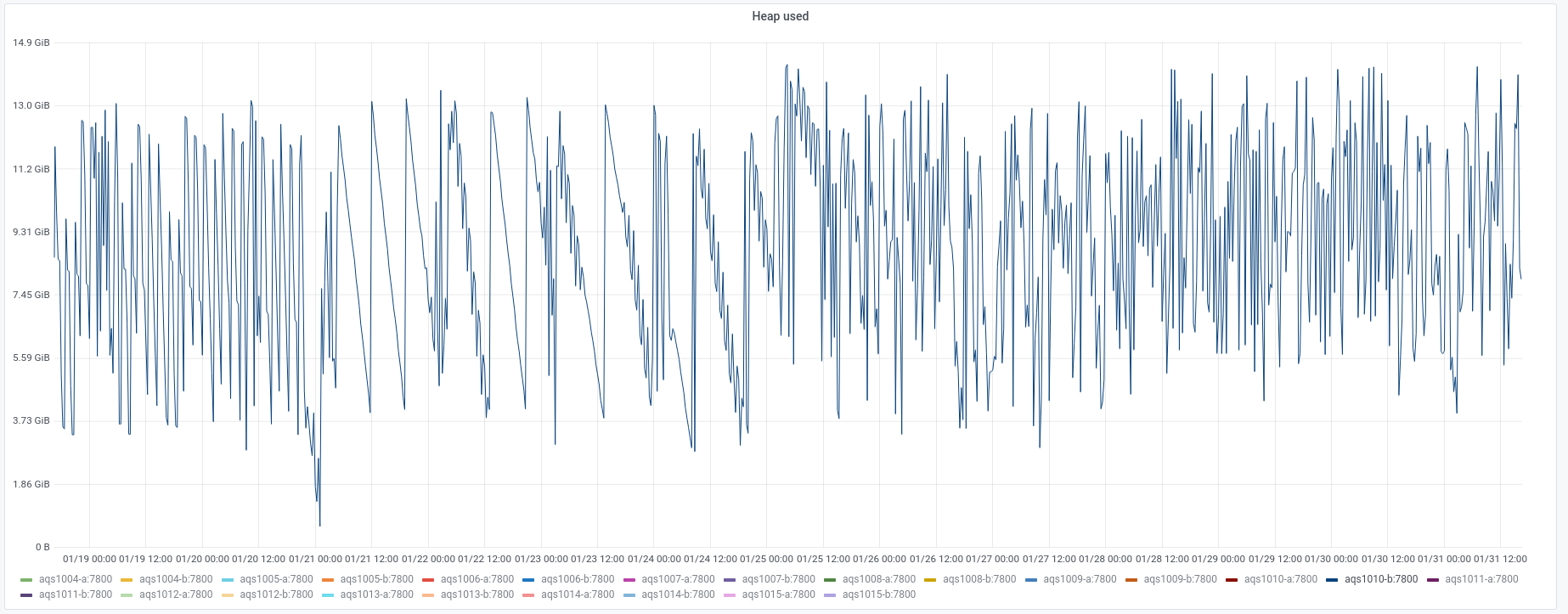
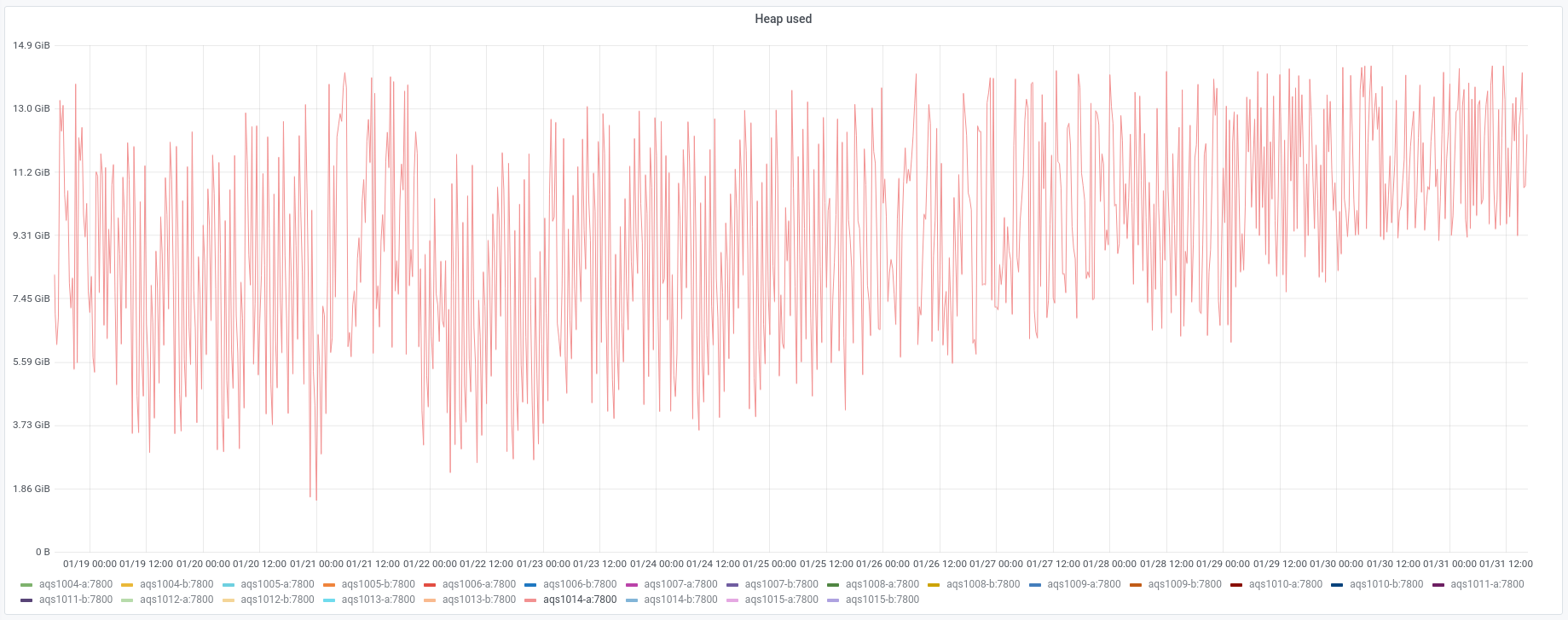
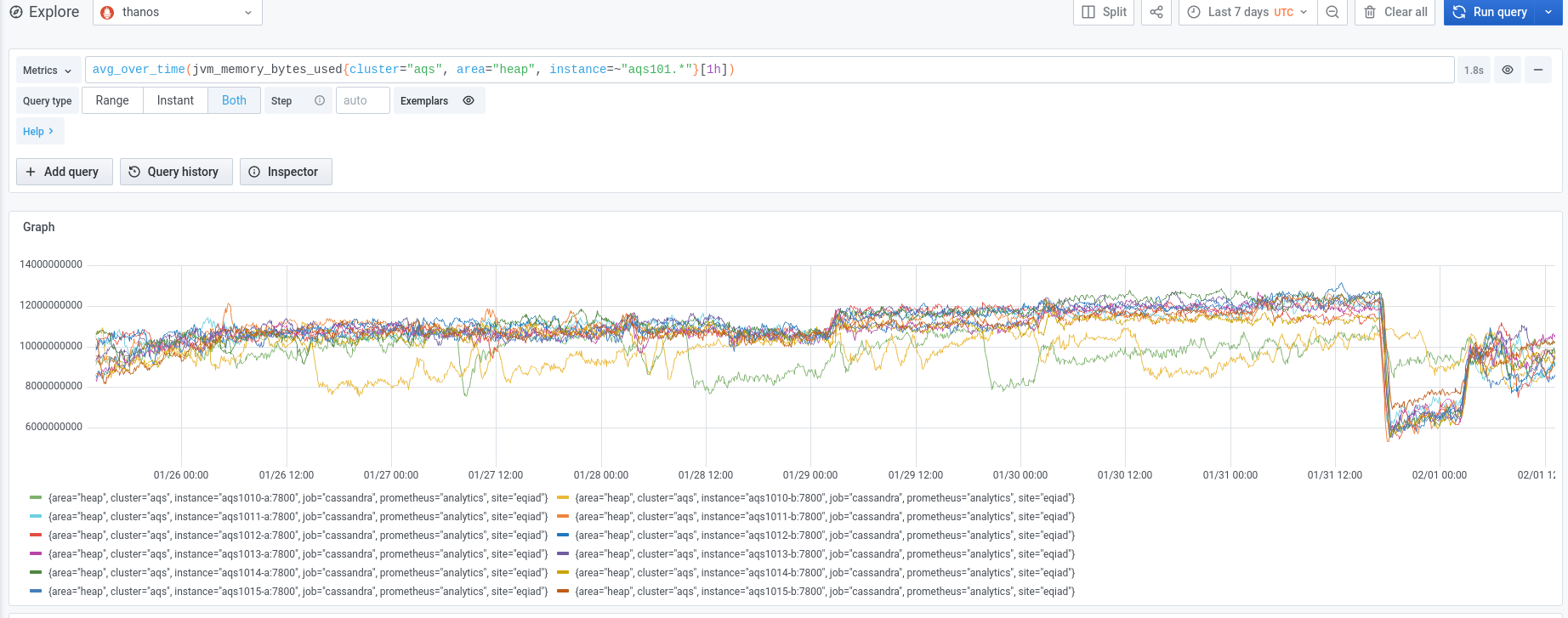
We experienced an incident on 2022/01/03 with two of the instances in the new AQS cluster.
Initially aqs1010-b went into a DN state and seemed to be spending a lot of time in garbage collection.
aqs1010 was the only node from the new cluster that was pooled and actively receiving traffic from the AQS web service at the time.
As per the SAL
- The aqs1010 node was depooled from the aqs cluster at 10:34 UTC
- The aqs1010-b instance was restarted at 11:16 UTC
Subsequently aqs1015-b stopped responding and went into a similar high GC state.
- The aqs1015-b instance was restarted at 11:26 UTC
The following day, both of the other instances on the same hosts also exhibited high heap usage and high levels of GC.
- The aqs1015-a instance was restarted at 10:20 UTC
- The aqs1015-a instance was restarted at 10:39 UTC
We would like to understand more about this excessive heap usage and unresponsiveness, before we complete the migration.