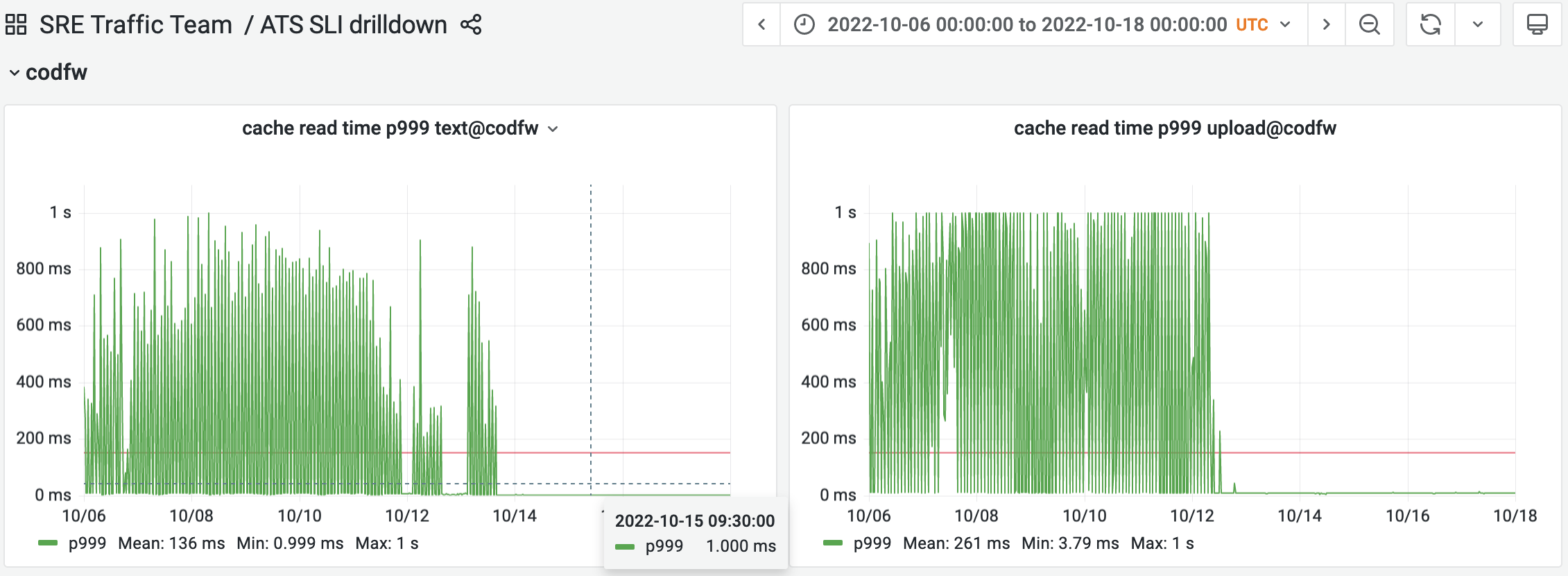
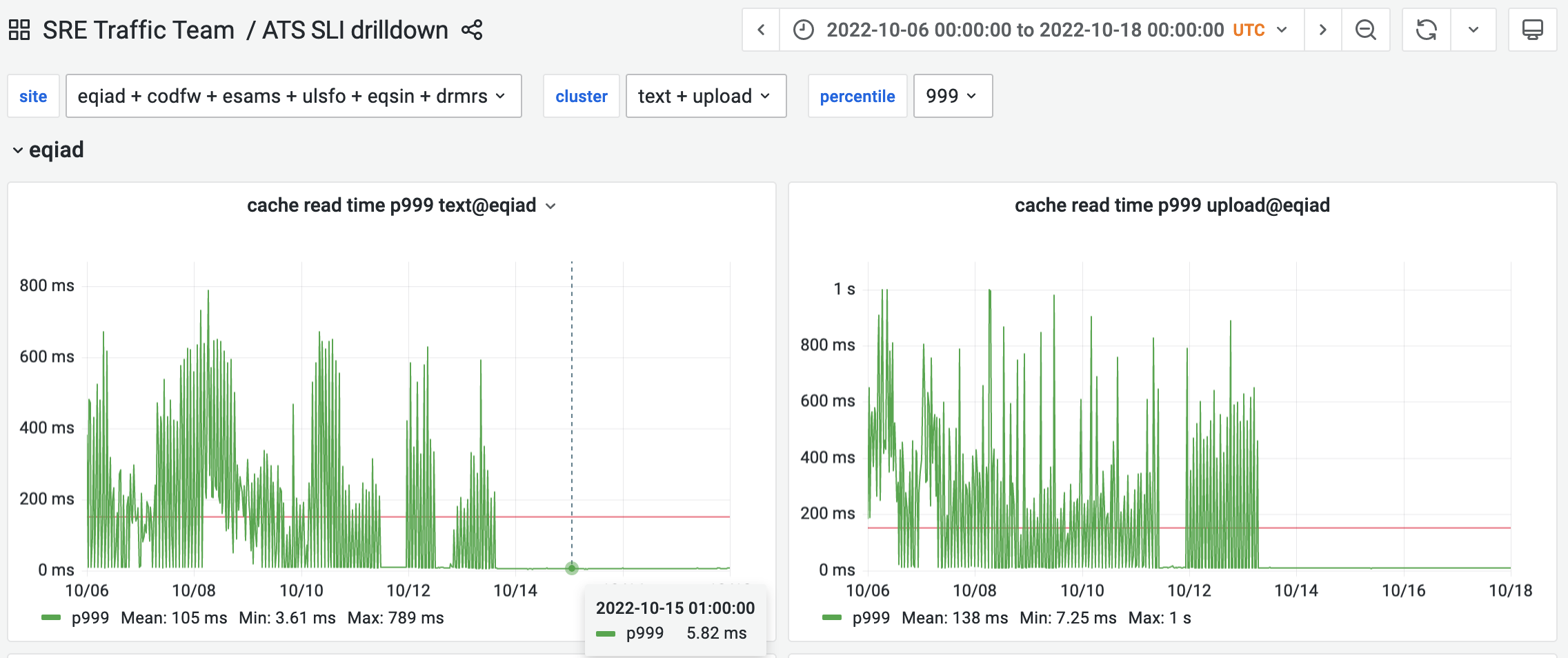
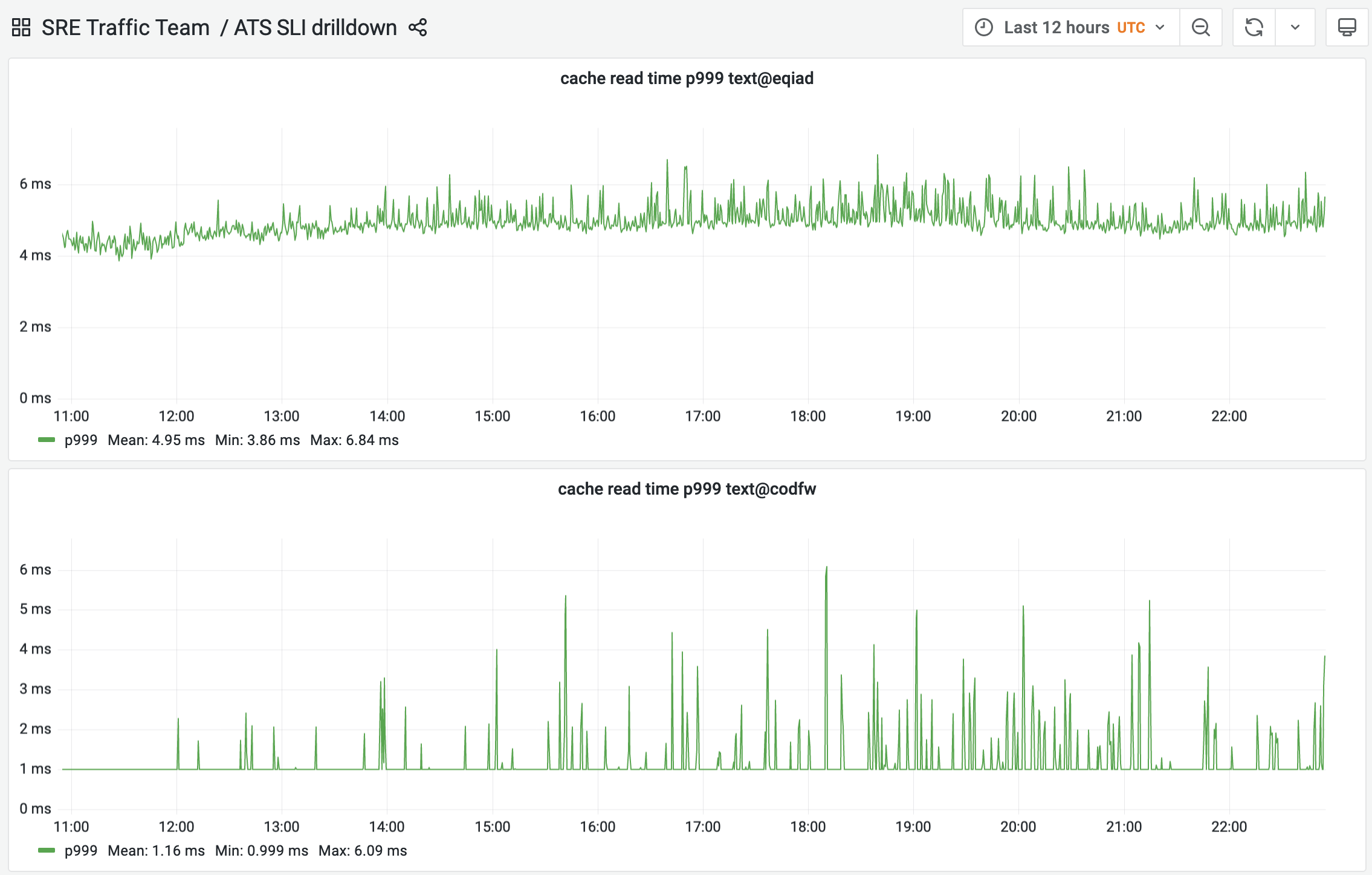
While working on SLIs for ATS, we've discovered that certain requests are consuming up to 1 second waiting for a cache read to happen:
Date:2022-09-14 Time:10:28:02 ConnAttempts:0 ConnReuse:7 TTFetchHeaders:1396 ClientTTFB:2007 CacheReadTime:610 CacheWriteTime:0 TotalSMTime:2095 TotalPluginTime:0 ActivePluginTime:0 OriginServer:appservers-ro.discovery.wmnet OriginServerTime:1484 CacheResultCode:TCP_MISS CacheWriteResult:FIN ReqMethod:GET RespStatus:200 OriginStatus:200 ReqURL:http://fr.m.wikipedia.org/wiki/Robert_Klapisch ReqHeader:User-Agent:Mozilla/5.0 (iPhone; CPU iPhone OS 15_6 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) GSA/228.0.471065565 Mobile/15E148 Safari/604.1 ReqHeader:Host:fr.wikipedia.org ReqHeader:X-Client-IP:REDACTED ReqHeader:GeoIP=REDACTED; PHP_ENGINE=7.4; WMF-Last-Access=14-Sep-2022; BerespHeader:Set-Cookie:- BerespHeader:Cache-Control:s-maxage=1209600, must-revalidate, max-age=0 BerespHeader:Connection:- RespHeader:X-Cache-Int:cp6016 miss RespHeader:Backend-Timing:D=1220799 t=1663151283314732