An incident occurred on 2023-01-24 when (as part of routine maintenance) one of the Cassandra hosts in eqiad (sessionstore1001) was rebooted. When sessionstore1001 went down, connections failed over to the remaining two nodes as expected. However, as soon as the rebooted node rejoined the cluster, the sessionstore service began emitting 500s and logging errors.
... {"msg":"Error writing to storage (Cannot achieve consistency level LOCAL_QUORUM)","appname":"sessionstore","time":"2023-01-24T21:10:27Z","level":"ERROR","request_id":"..."} {"msg":"Error reading from storage (Cannot achieve consistency level LOCAL_QUORUM)","appname":"sessionstore","time":"2023-01-24T21:10:27Z","level":"ERROR","request_id":"..."} {"msg":"Error deleting in storage (Cannot achieve consistency level EACH_QUORUM in DC eqiad","appname":"sessionstore","time":"2023-01-24T21:10:27Z","level":"ERROR","request_id":"..."} ...
This happened as a result of a kind of split-brain condition. After the reboot, sessionstore1001 started and transitioned to an UP state. The other two nodes (1002 & 1003) also transitioned 1001 from DOWN to UP. However, 1001 did not recognize 1002 & 1003 as being online, it saw their state as DOWN. Meanwhile, 1001 began accepting client connections, and the driver (which also observed 1001 come online) began routing a portion of client requests to it. We replicate sessions 3 ways (per datacenter), and use QUORUM reads & writes, which is to say: we must see at least two of the three replicas to satisfy a read, and synchronously replicate at least two to successfully write. Clients that attempted to use 1001 as a coordinator node failed with an 'unavailable exception' (the source of the errors observed), because that node was unable to locate another replica in order to satisfy QUORUM.
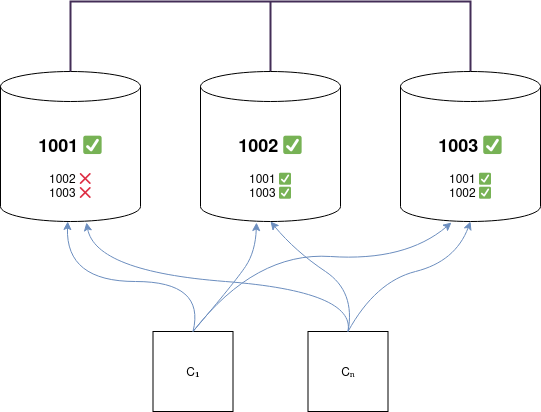
Summary of findings:
This problem only manifests when a host is rebootedWhen Cassandra starts up immediately after a prolonged outage, that node sees an erroneous cluster state, where one or more of the other nodes are DOWNFrom the perspective of all other nodes however, membership is green across the board — including the recently rebooted nodeConnectivity, in every other respect seems fine (Cassandra clients can open connections, SSH works, etc)
The problem resolves itself after 15 minutes and some seconds (< 30); No intervention is required, and nothing would seem to extend or shorten this periodNothing done to the rebootee would seem to shorten the period; A restart of the other nodes will correct their state on the problematic one
It can be reproduced on any of the 6 sessionstore hosts, in either of the two datacenters (quite reliably)- It only happens in the sessionstore cluster; It cannot be reproduced on any of restbase, aqs, or the cassandra-dev clusters
- Cassandra, JVM, kernels, etc match across all clusters
- It is dependent upon the timing between a node shutdown, and startup. A simple restart (where the stop is immediately followed by a start), does not provoke, but with sufficient time between the stop and start, it does. This is why it appeared to manifest only on reboots (that was the only time that a start & stop were separated by minutes).
- It seems to correspond to what was reported in CASSANDRA-13984. The problem lies with peer nodes (as opposed to the node that was restarted); Peers are shutting down their outbound messaging when the restarting node announces shutdown, but then (inexplicably) attempt to reconnect. If the affected node immediately starts back up this reconnect succeeds, and all is fine. However, if the node is down for any significant period, then it remains in a defunct state for (apparently) 20 minutes¹.
- Issuing a nodetool disablegossip and nodetool drain prior to the restart seems to work around this issue (both result in an announced shutdown of Gossip, and apparently the second one succeeds)
- Using kill -9 to simulate a ungraceful shutdown also results in correct state after startup (without the Gossip shutdown message, the racing reconnect never happens)
[¹] We observed 15 minutes, but that was 15 minutes after Cassandra startup. The additional 5 minutes is likely the period between shutdown and startup when the host is being rebooted
Next Steps
- Follow-up with upstream
- Remove de-initialization from c-foreach-restart
- Add de-initialization to Cassandra systemd unit
See also:
- https://wikitech.wikimedia.org/wiki/Incidents/2023-01-24_sessionstore_quorum_issues (incident document)
- https://wikitech.wikimedia.org/wiki/Incidents/2022-09-15_sessionstore_quorum_issues (past incident (at least) similar (if not identical) to this one)
- https://logstash.wikimedia.org/goto/d9a0a6a1e3663b452b3119ba51049e27 (snapshot of Kask logs from the incident)
- https://user.cassandra.apache.narkive.com/SWz6Jh2j/non-zero-nodes-are-marked-as-down-after-restarting-cassandra-process (similar report from another user)
- https://issues.apache.org/jira/browse/CASSANDRA-13984 (similar report from another user)
- https://unix.stackexchange.com/questions/4420/reply-on-same-interface-as-incoming
