This task is for documenting how conda-analytics environments might reach a broken state and identify ways to solve the problem. We have so far identified one such case, which goes as follows:
- Create a new conda-analytics Jupyter environment and launch it.
- In a Jupyter terminal window, install the Mamba solver per these instructions (note that a Jupyter terminal is needed because it'll also upgrade conda to version 23.1, which is required to be able to change its solver).
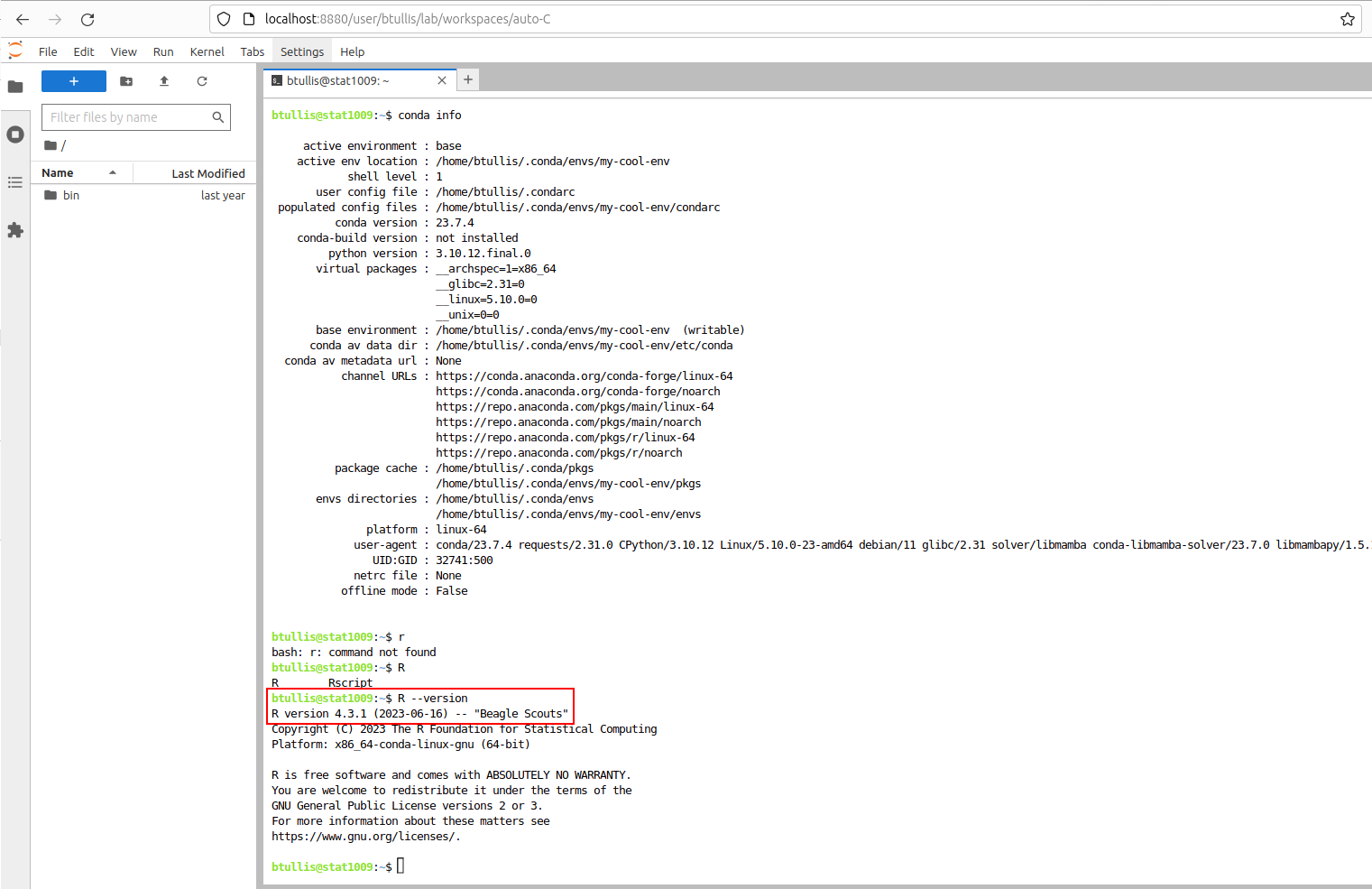
- Install R 4.2.3 with conda install -c conda-forge r-base=4.2.3.
The environment ends up with incompatible versions of PySpark and Jupyter so running Spark queries fails, and if the Jupyter server is shut down it will not restart.
When discussing this on Slack, @BTullis noted that it's possible to pin Conda packages to prevent updates. This might be one good solution, e.g. for ensuring that the PySpark package installed matches that of the server. Another approach is to first do a dry run of an installation using the -d command line parameter to conda and then check that it doesn't update things like PySpark and Jupyter.