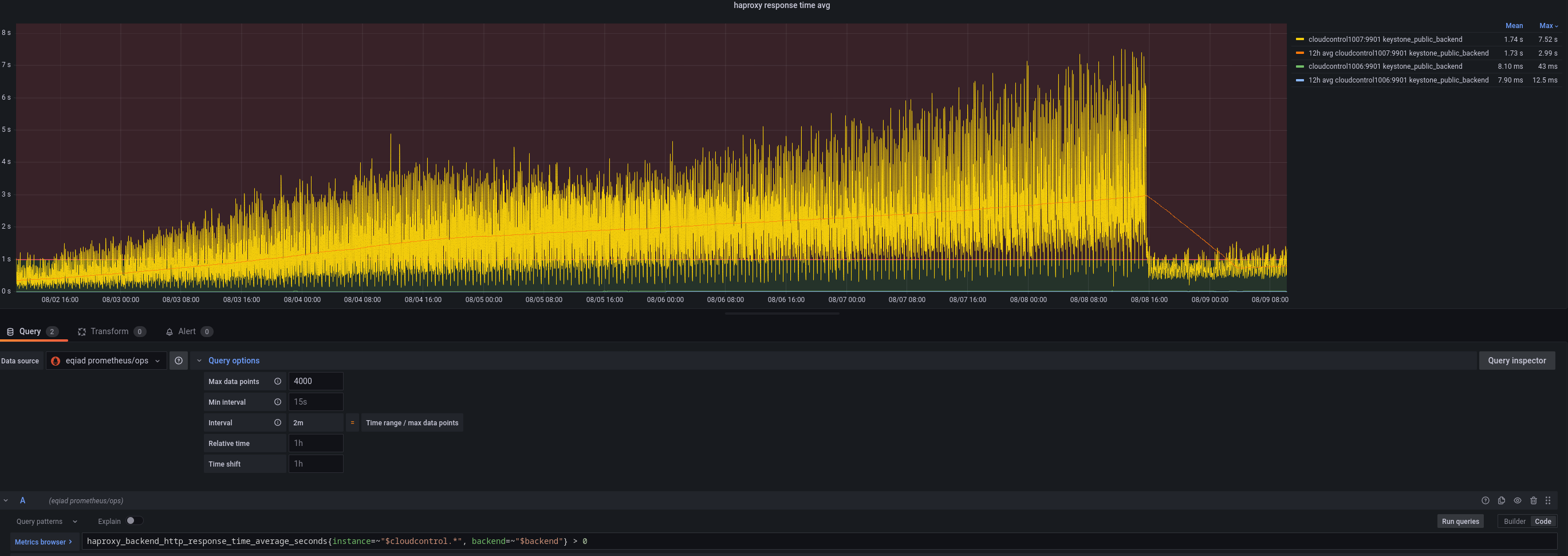
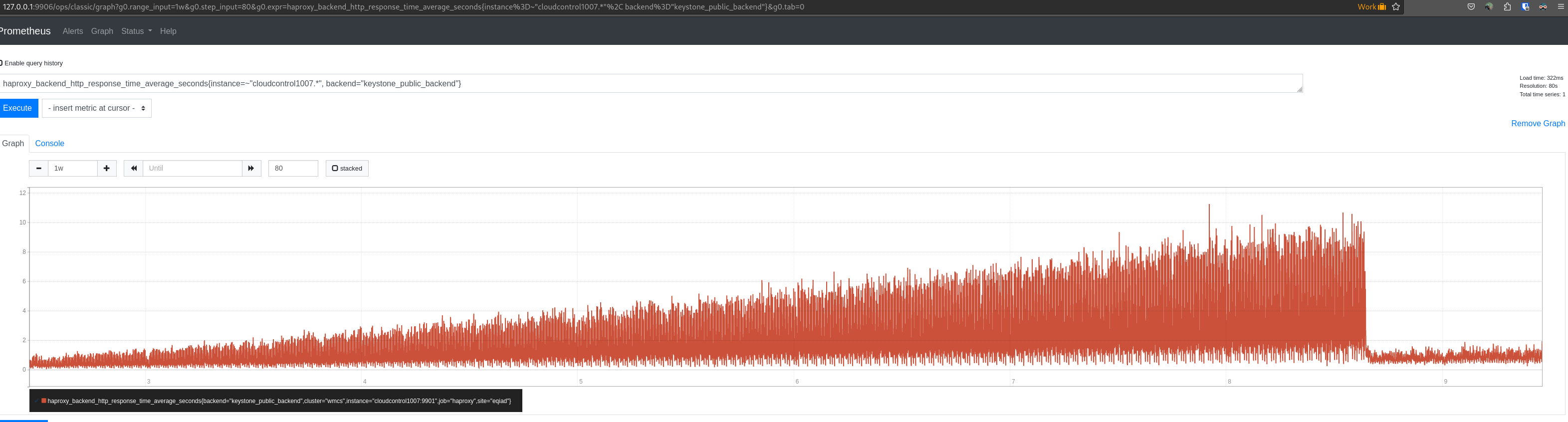
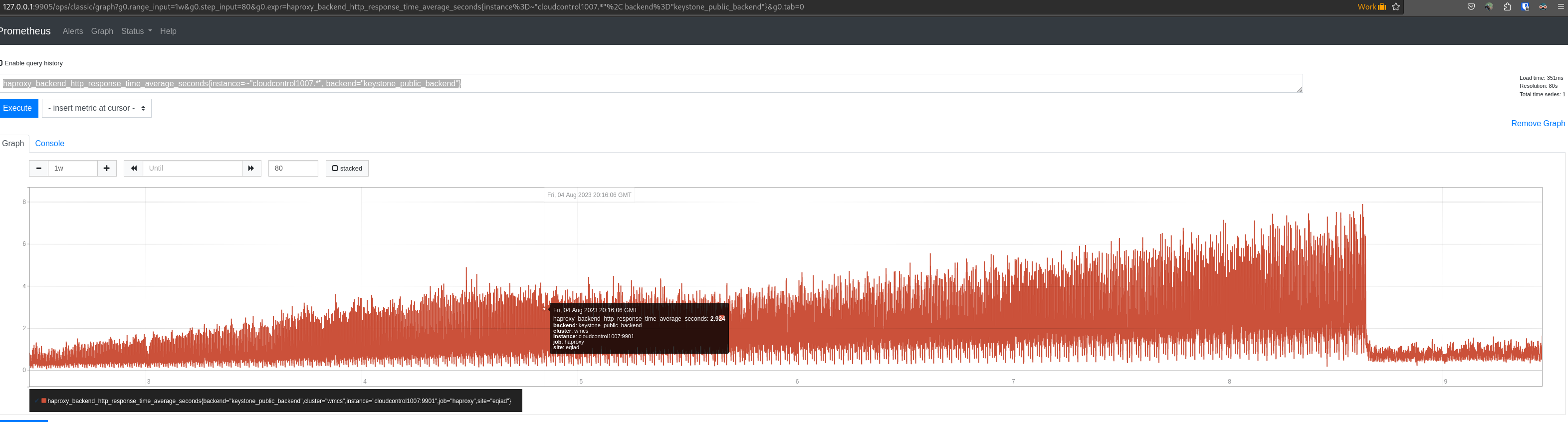
When going to the grafana board:
If you refresh you might get sometimes a different set of data for the same metrics, making the graps not consistent.
This task is to investigate and hopefully fix/remediate the issue so we get reliable data.
Examples:


There were some issues with scraping haproxy for traffic, and they tried disabling keep-alive, so I backported their patch also to see if it helped:
https://gerrit.wikimedia.org/r/c/operations/puppet/+/947325
But did not so far.
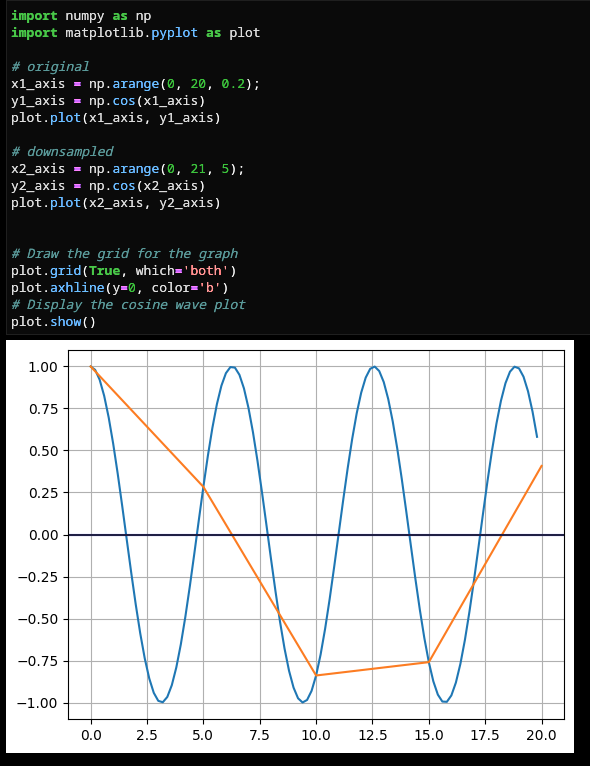
It might be a 'spikey' graph issue, where the filtering of number of values retrieved from the backend might end up getting rid of the spikes: