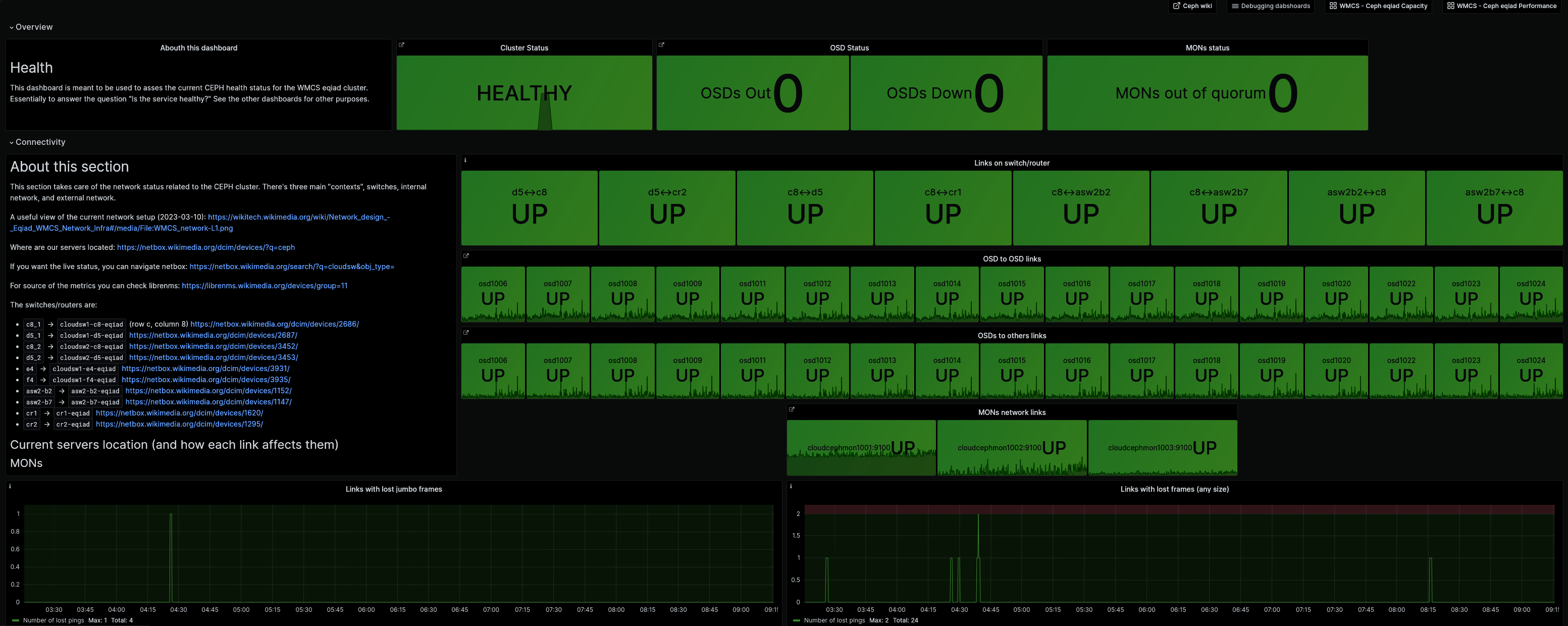
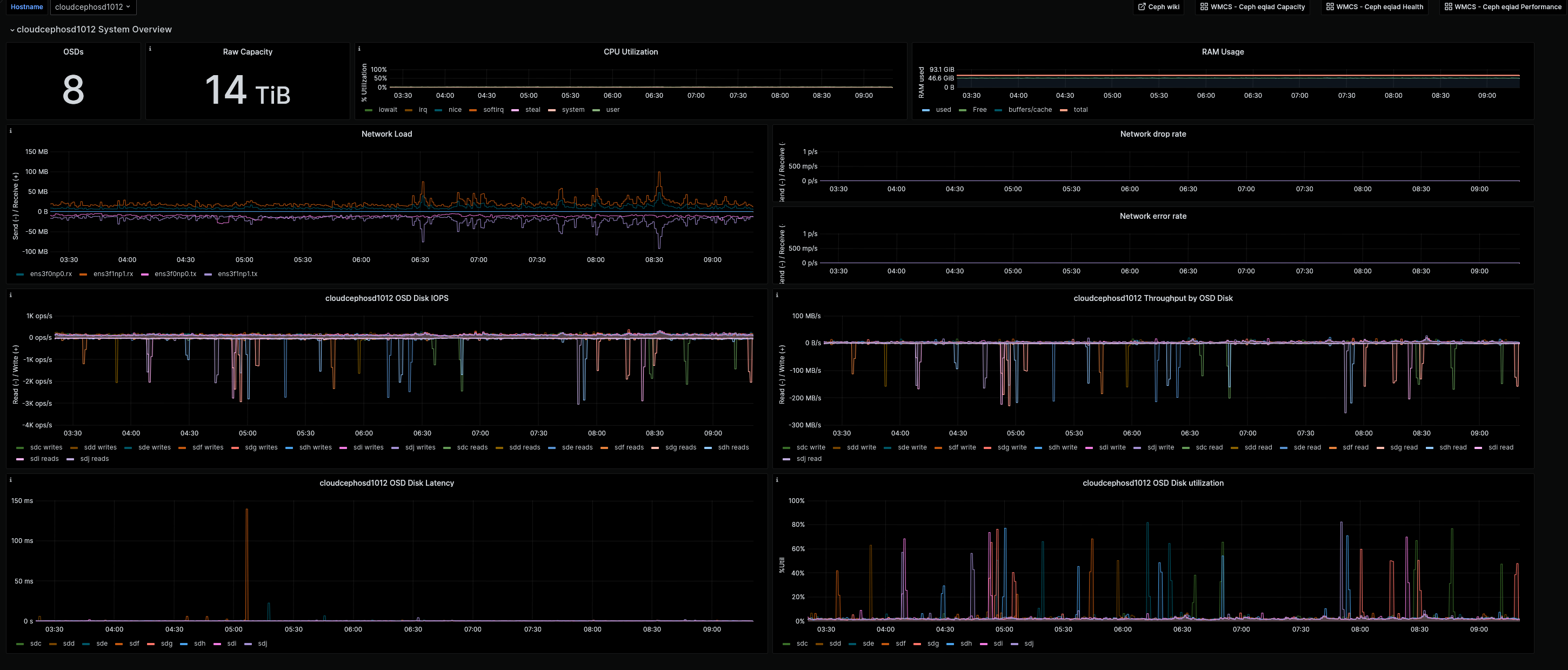
Something happened in Ceph today that triggered a NFS alert (critical, I received a page). The alert resolved without any action after a few minutes.
Timeline as recorded in #wikimedia-cloud-feed (all times UTC):
06:41 <+jinxer-wm> (CephClusterInWarning) firing: The ceph cluster in is in warning status, that means that it's high availability is compromised, things should still be working as expected. - https://wikitech.wikimedia.org/wiki/Portal:Cloud_VPS/Admin/Runbooks/CephClusterInWarning - https://grafana.wikimedia.org/d/P1tFnn3Mk/wmcs-ceph-eqiad-health?orgId=1&search=open&tag=ceph&tag=health&tag=WMCS - https://alerts.wikimedia.org/?q=alertname%3DCephClusterInWar 06:45 <+wmcs-alerts> (ProbeDown) firing: (2) Service tools-k8s-haproxy-3:30000 has failed probes (http_admin_toolforge_org_ip4) - https://grafana.wikimedia.org/d/O0nHhdhnz/network-probes-overview?var-job=probes/custom&var-module=All - https://prometheus-alerts.wmcloud.org/?q=alertname%3DProbeDown 06:46 <+icinga-wm> PROBLEM - toolschecker: NFS read/writeable on labs instances on checker.tools.wmflabs.org is CRITICAL: HTTP CRITICAL: HTTP/1.1 504 Gateway Time-out - string OK not found on http://checker.tools.wmflabs.org:80/nfs/home - 340 bytes in 60.008 second response time https://wikitech.wikimedia.org/wiki/Portal:Toolforge/Admin/Toolschecker 06:47 <+icinga-wm> PROBLEM - toolschecker: check mtime mod from tools cron job on checker.tools.wmflabs.org is CRITICAL: HTTP CRITICAL: HTTP/1.1 504 Gateway Time-out - string OK not found on http://checker.tools.wmflabs.org:80/cron - 340 bytes in 60.004 second response time https://wikitech.wikimedia.org/wiki/Portal:Toolforge/Admin/Toolschecker 06:50 <+icinga-wm> RECOVERY - toolschecker: NFS read/writeable on labs instances on checker.tools.wmflabs.org is OK: HTTP OK: HTTP/1.1 200 OK - 158 bytes in 52.649 second response time https://wikitech.wikimedia.org/wiki/Portal:Toolforge/Admin/Toolschecker 06:50 <+wmcs-alerts> (ProbeDown) resolved: (5) Service tools-k8s-haproxy-3:30000 has failed probes (http_admin_toolforge_org_ip4) - https://grafana.wikimedia.org/d/O0nHhdhnz/network-probes-overview?var-job=probes/custom&var-module=All - https://prometheus-alerts.wmcloud.org/?q=alertname%3DProbeDown 06:52 <+icinga-wm> RECOVERY - toolschecker: check mtime mod from tools cron job on checker.tools.wmflabs.org is OK: HTTP OK: HTTP/1.1 200 OK - 158 bytes in 0.012 second response time https://wikitech.wikimedia.org/wiki/Portal:Toolforge/Admin/Toolschecker 06:56 <+jinxer-wm> (CephClusterInWarning) resolved: The ceph cluster in is in warning status, that means that it's high availability is compromised, things should still be working as expected. - https://wikitech.wikimedia.org/wiki/Portal:Cloud_VPS/Admin/Runbooks/CephClusterInWarning - https://grafana.wikimedia.org/d/P1tFnn3Mk/wmcs-ceph-eqiad-health?orgId=1&search=open&tag=ceph&tag=health&tag=WMCS - https://alerts.wikimedia.org/?q=alertname%3DCephClusterInW