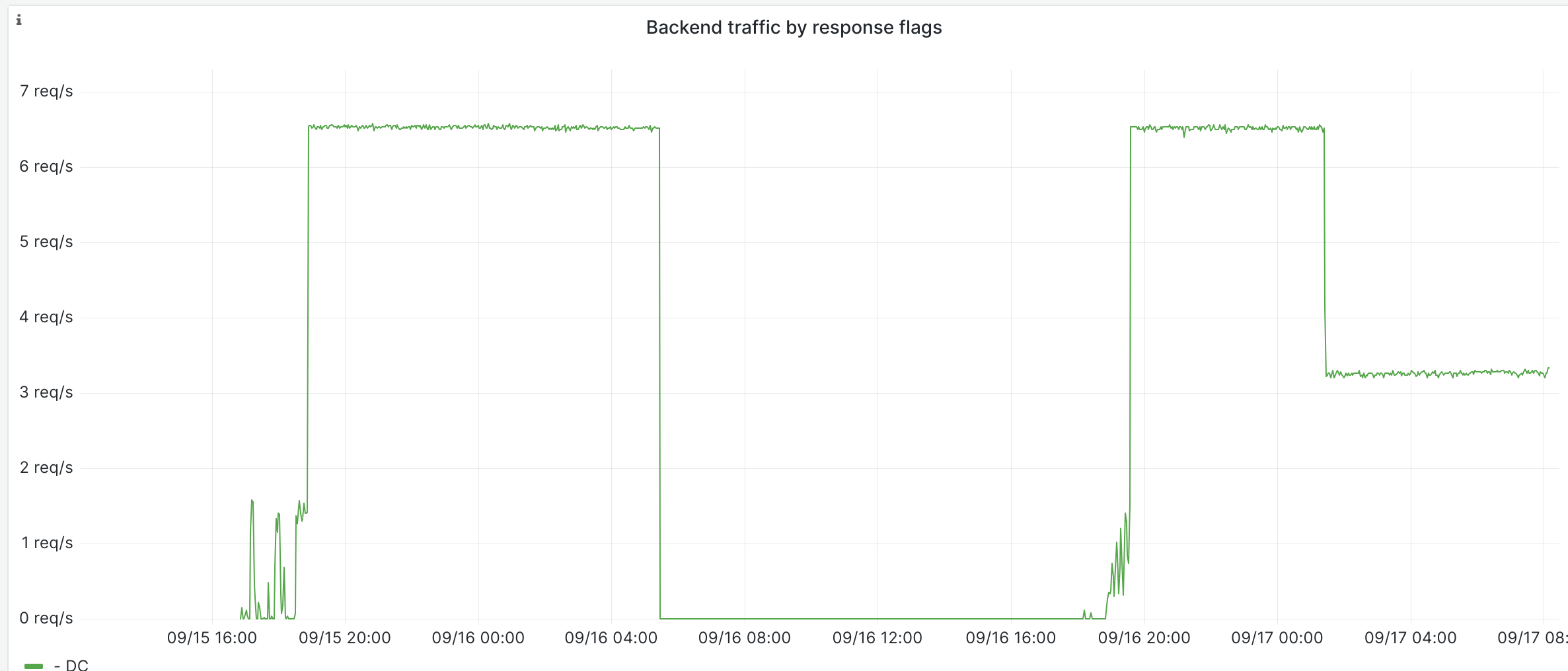
We found out about this problem in T346175
The current symptom are:
- Pods shown in kubectl with container health status 2/3.
- Example: eswiki-damaging-predictor-default-00011-deployment-754dcd86j6kb 2/3 Running 0 2d22h
- The queue-proxy container seems to fail health checks, and it logs stuff like: aggressive probe error (failed 72 times): dial tcp 127.0.0.1:8080: i/o timeout
- The kserve container doesn't log anything suspicious.
- Changeprop and other clients hang when calling the pod blackholing traffic, eventually timing out (client side) and giving it up.
We don't know exactly why this is happening, maybe it could be due to autoscaling settings (since this is what we have changed recently).
Since we don't know many logs in kserve (due to a bug in 0.11) we should prioritize upgrading our docker images to 0.11 to get all logs that we should, hopefully getting some clue about what's happening.