From Seawolf35: https://www.mediawiki.org/wiki/Topic:Xplk44hmlwwu97ki
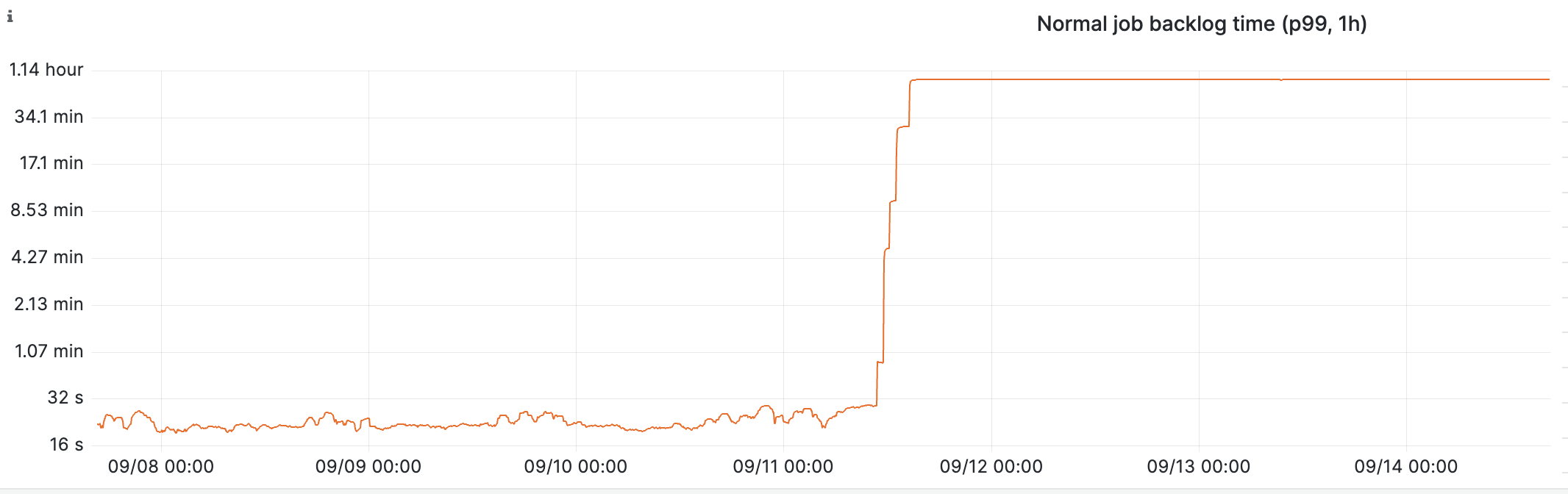
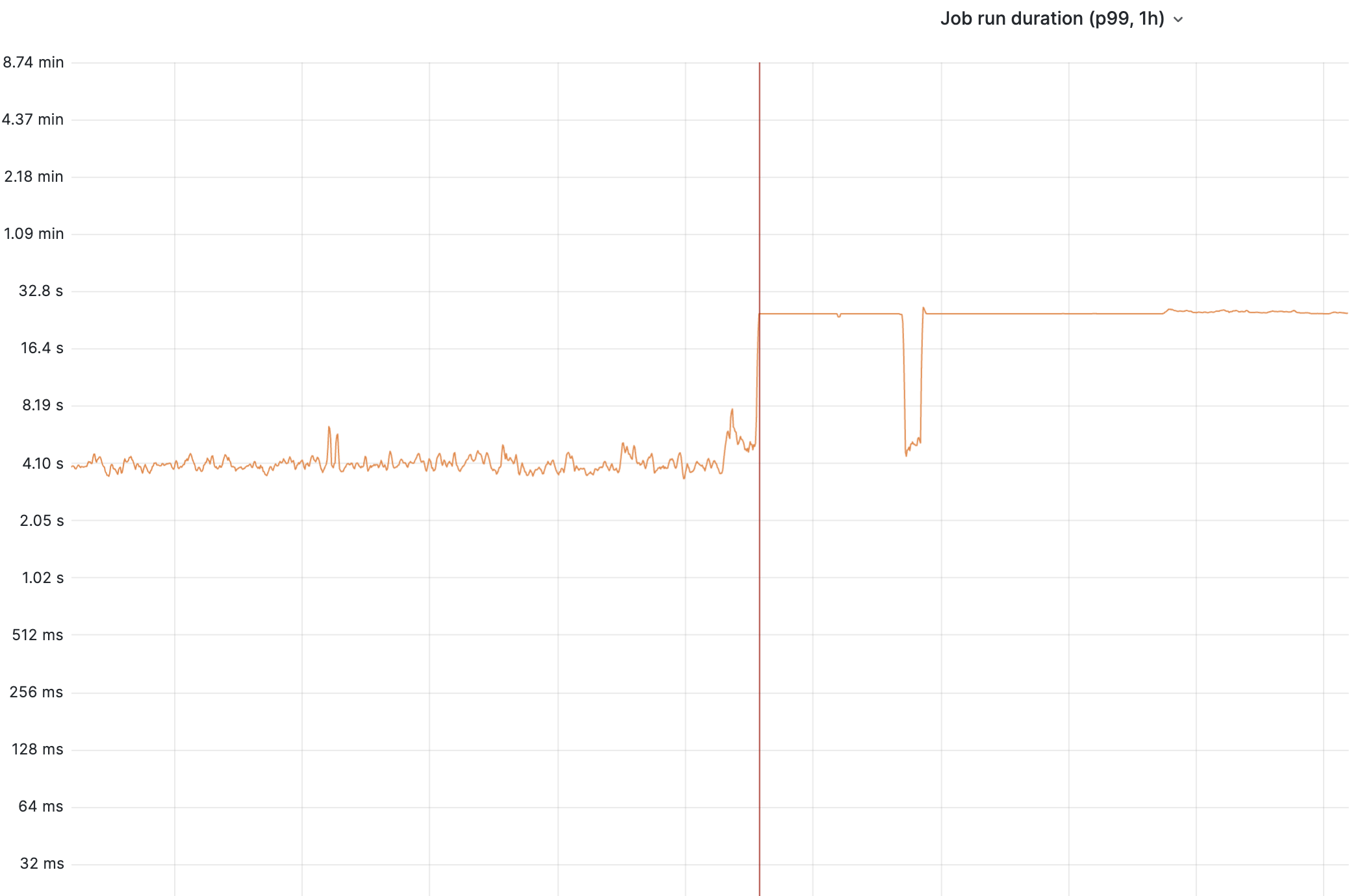
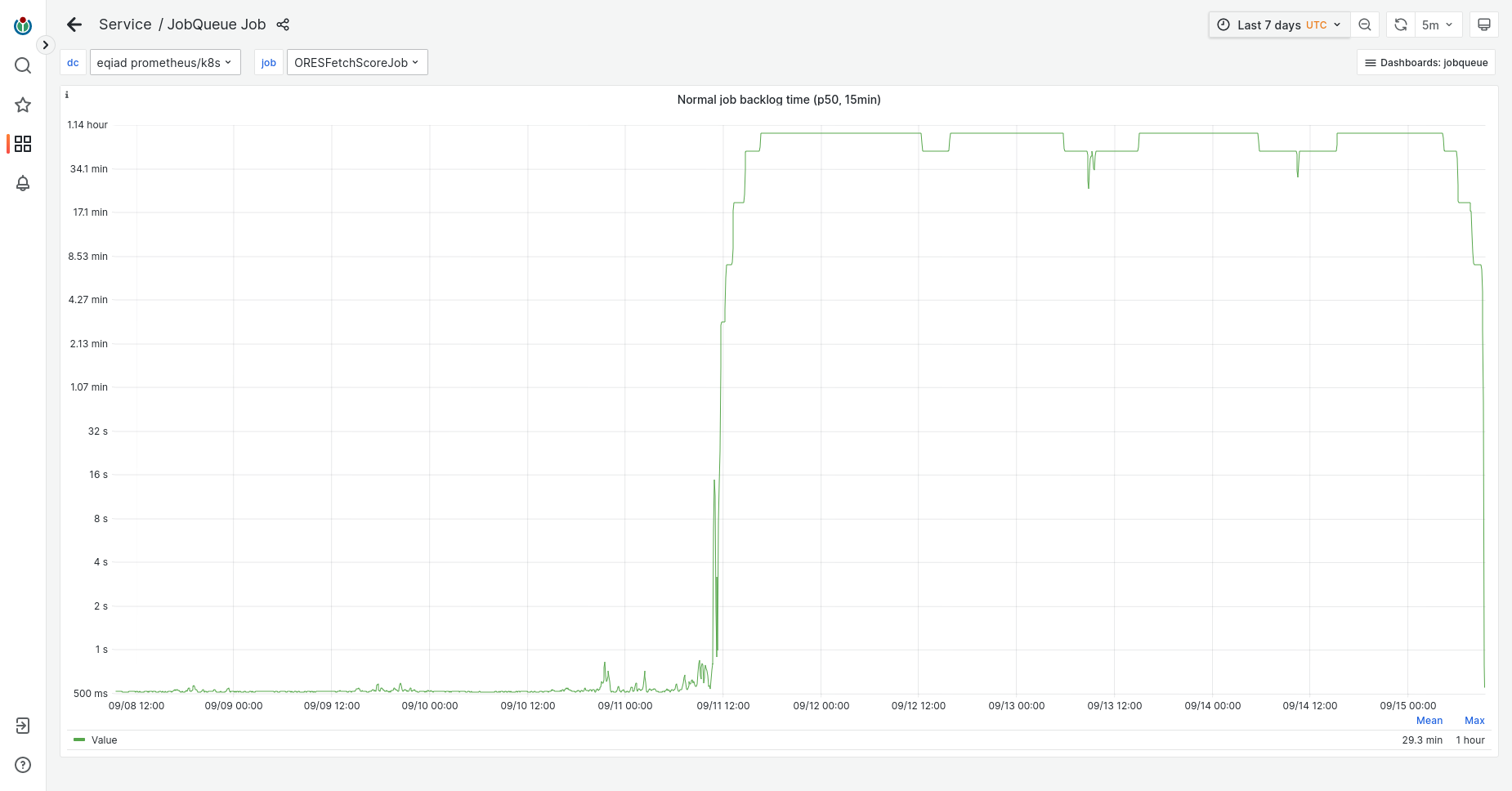
"Recently, I have found that on the Wikipedia recent changes list the edit highlighting by ORES has disappeared. Is this because of the new open source infrastructure? Any solutions other than to just wait."