We got paged today:
https://grafana.wikimedia.org/d/O0nHhdhnz/network-probes-overview?var-job=probes/service&var-module=All thanos-query:443 failed when probed by http_thanos-query_ip4 from eqiad. Availability is 0%. https://logstash.wikimedia.org/app/dashboards#/view/f3e709c0-a5f8-11ec-bf8e-43f1807d5bc2?_g=(filters:!((query:(match_phrase:(service.name:http_thanos-query_ip4))))) https://wikitech.wikimedia.org/wiki/Runbook#thanos-query:443 Service thanos-query:443 has failed probes (http_thanos-query_ip4) #page Alerts Firing: Labels: - alertname = ProbeDown - address = 10.2.2.53 - family = ip4 - instance = thanos-query:443 - job = probes/service - module = http_thanos-query_ip4 - prometheus = ops - severity = page - site = eqiad - source = prometheus - team = sre Annotations: - dashboard = https://grafana.wikimedia.org/d/O0nHhdhnz/network-probes-overview?var-job=probes/service&var-module=All - description = thanos-query:443 failed when probed by http_thanos-query_ip4 from eqiad. Availability is 0%. - logs = https://logstash.wikimedia.org/app/dashboards#/view/f3e709c0-a5f8-11ec-bf8e-43f1807d5bc2?_g=(filters:!((query:(match_phrase:(service.name:http_thanos-query_ip4))))) - runbook = https://wikitech.wikimedia.org/wiki/Runbook#thanos-query:443 - summary = Service thanos-query:443 has failed probes (http_thanos-query_ip4) #page Source: https://prometheus-eqiad.wikimedia.org/ops/graph?g0.expr=%28avg_over_time%28probe_success%7Bjob%3D~%22probes%2F.%2A%22%2Cmodule%3D~%22%28http%7Ctcp%29.%2A%22%7D%5B1m%5D%29+and+on+%28instance%29+service_catalog_page+%3D%3D+1%29+%2A+100+%3C+10&g0.tab=1
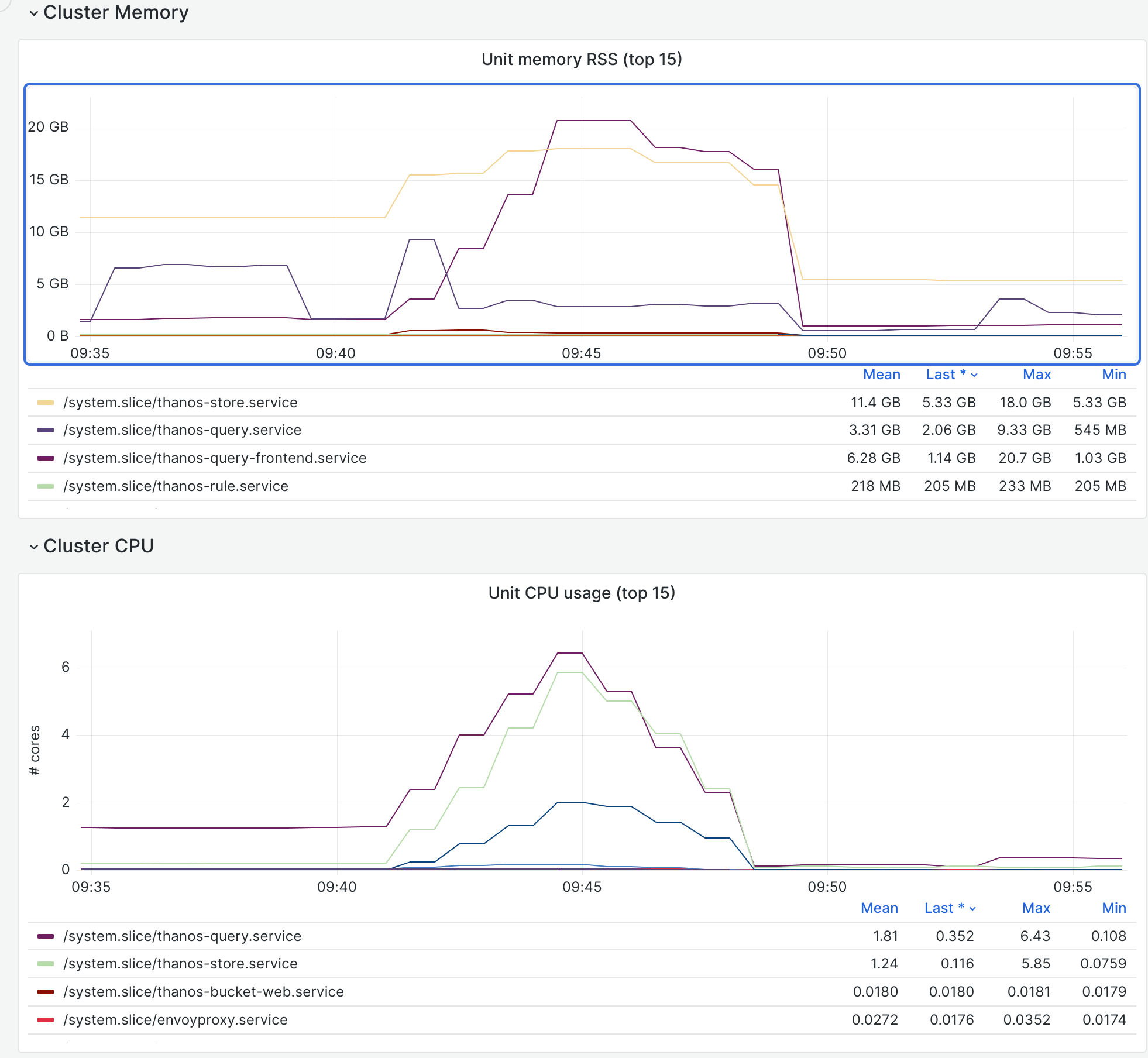
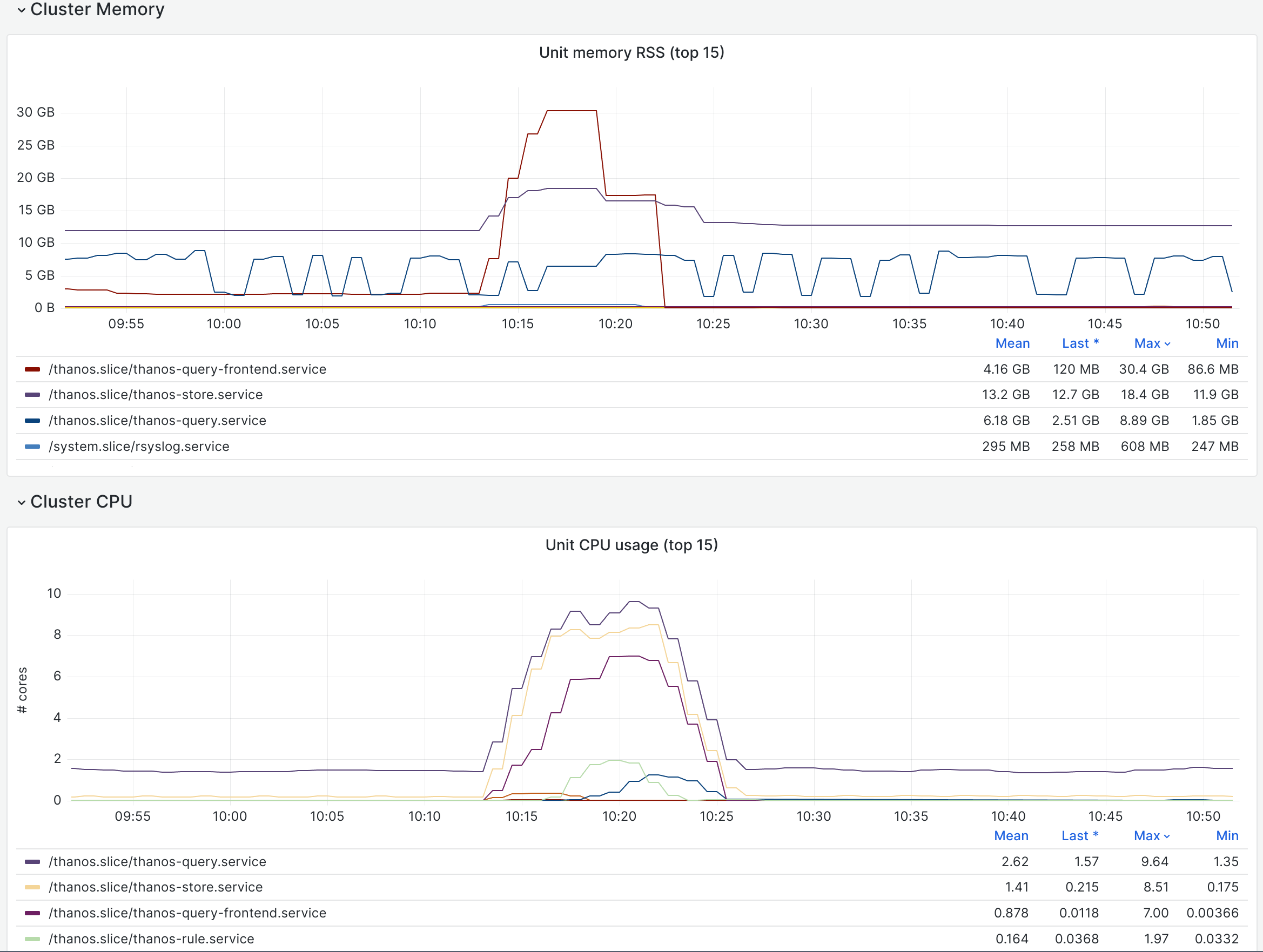
On both eqiad titan nodes, the OOM killer came for thanos:
2024-02-06T16:02:48.599094+00:00 titan1002 kernel: [529285.100137] Out of memory: Killed process 944 (thanos) total-vm:25141640kB, anon-rss:20740672kB, file-rss:0kB, shmem-rss:0kB, UID:111 pgtables:47124kB oom_score_adj:0 2024-02-06T16:02:42.108834+00:00 titan1001 kernel: [534723.800913] Out of memory: Killed process 935 (thanos) total-vm:25080384kB, anon-rss:24252060kB, file-rss:0kB, shmem-rss:0kB, UID:111 pgtables:47820kB oom_score_adj:0
Systemd notices and restarts the service, so the incident self-resolved:
2024-02-06T16:02:48.599092+00:00 titan1002 kernel: [529285.100104] oom-kill:constraint=CONSTRAINT_NONE,nodemask=(null),cpuset=/,mems_allowed=0,global_oom,task_memcg=/system.slice/thanos-query.service,task=thanos,pid=944,uid=111 2024-02-06T16:02:48.790450+00:00 titan1002 systemd[1]: thanos-query.service: A process of this unit has been killed by the OOM killer. 2024-02-06T16:02:49.814773+00:00 titan1002 systemd[1]: thanos-query.service: Main process exited, code=killed, status=9/KILL 2024-02-06T16:02:49.814901+00:00 titan1002 systemd[1]: thanos-query.service: Failed with result 'oom-kill'. 2024-02-06T16:02:49.815302+00:00 titan1002 systemd[1]: thanos-query.service: Consumed 11h 54min 16.327s CPU time. 2024-02-06T16:02:49.916665+00:00 titan1002 systemd[1]: thanos-query.service: Scheduled restart job, restart counter is at 1. 2024-02-06T16:02:49.917068+00:00 titan1002 systemd[1]: Stopped thanos-query.service - Thanos query. 2024-02-06T16:02:49.917829+00:00 titan1002 systemd[1]: thanos-query.service: Consumed 11h 54min 16.327s CPU time. 2024-02-06T16:02:49.963018+00:00 titan1002 systemd[1]: Started thanos-query.service - Thanos query.
My best guess is that a particular query is what caused the memory overuse (since that would explain the almost-identical timings?), but that might warrant further investigation. It would be nice if user error didn't kill the service, however briefly. And obviously if that happens frequently enough eventually systemd will decide the service is failed and stop trying to restart it.
From an oncall perspective, too, it'd be nice if the thanos docs talked about which things are served by titan* rather than thanos-fe* (and maybe the alert could be a bit clearer in this regard too)?