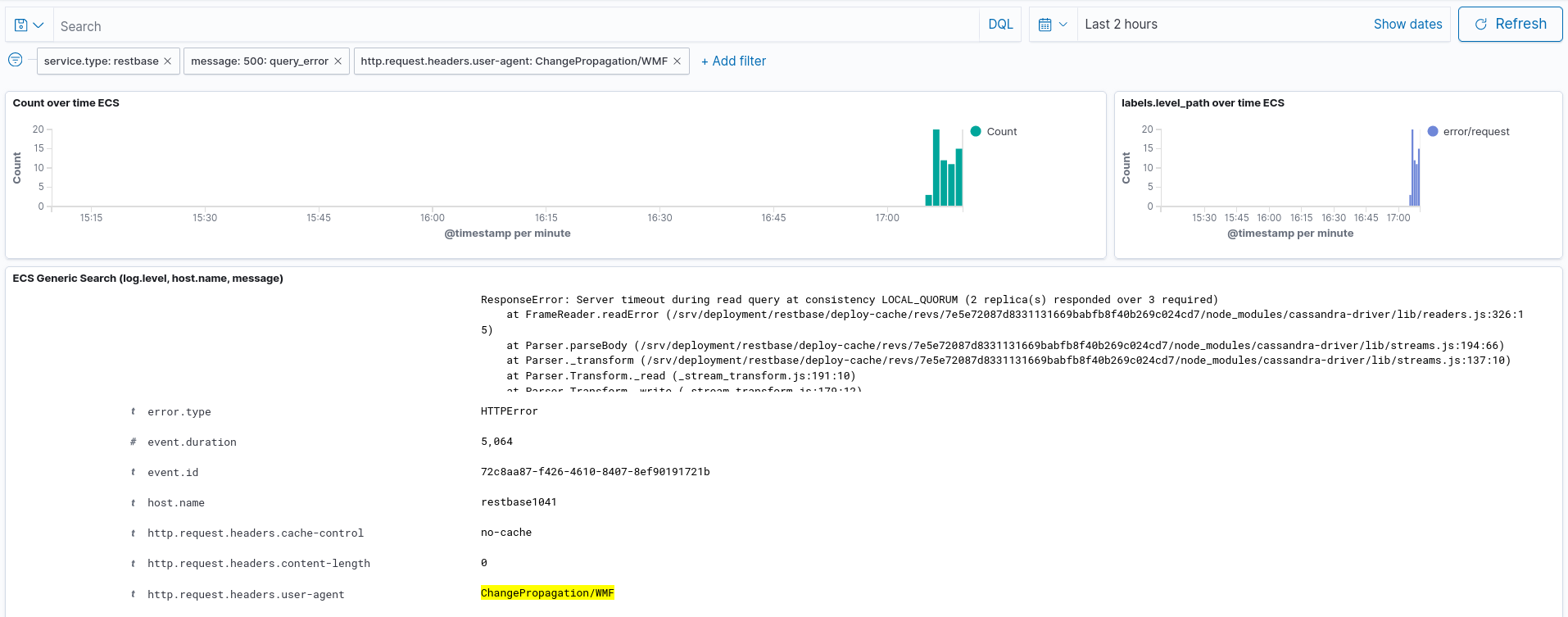
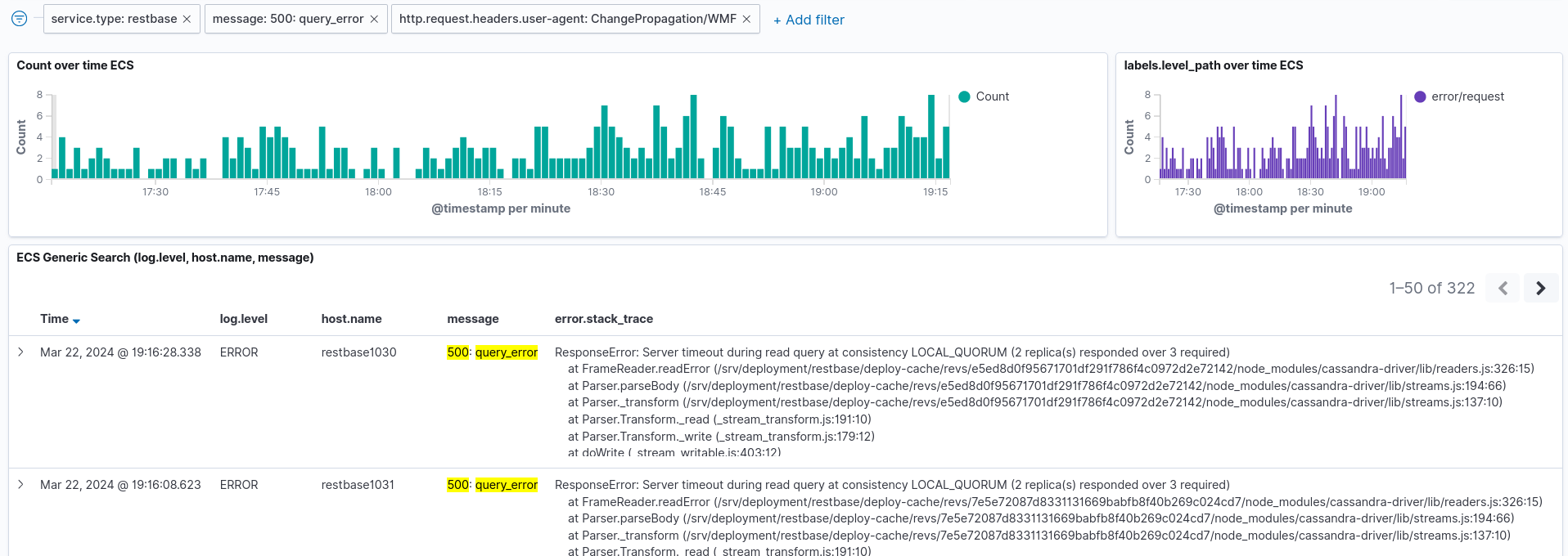
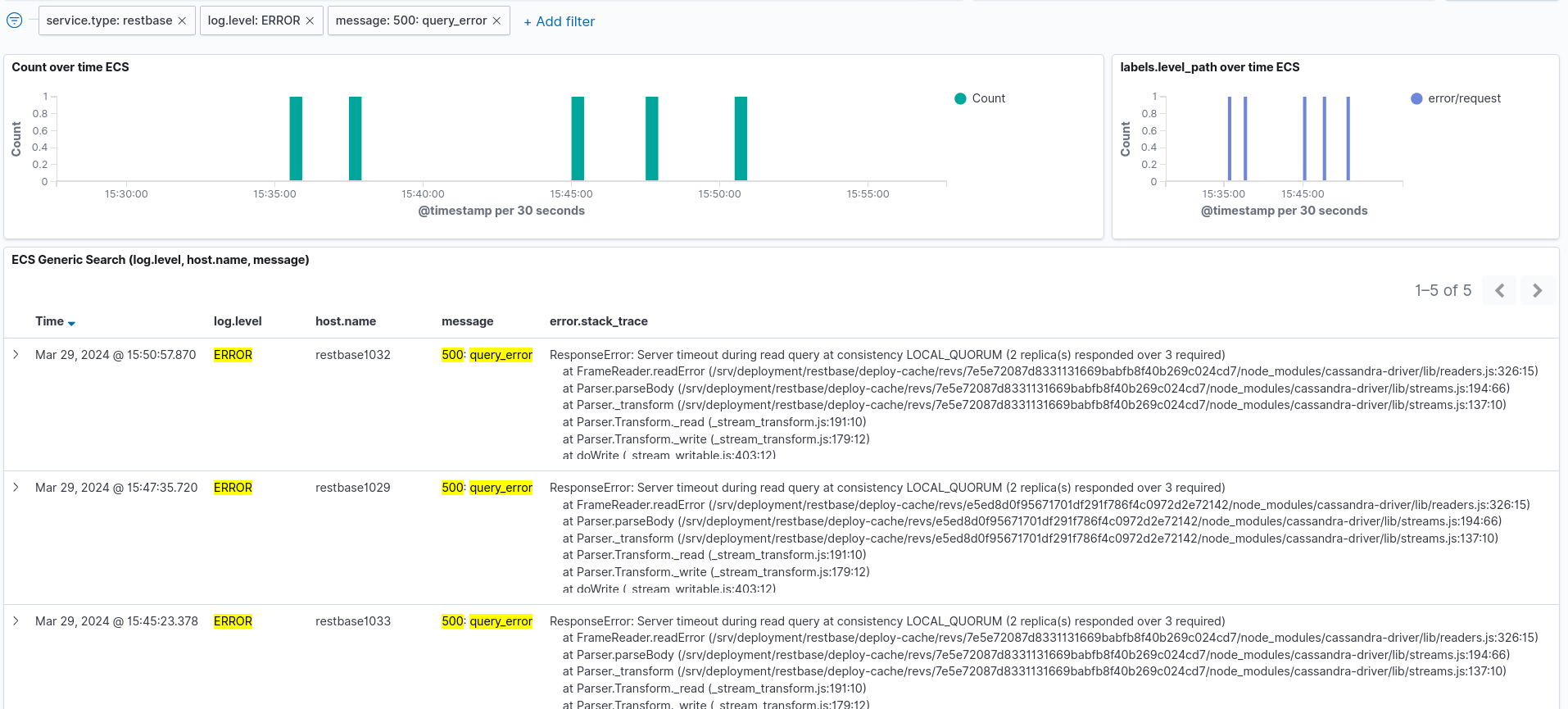
After today's data-center switchover (codfw to eqiad) elevated errors were observed for changeprop. These errors were bubbling up from RESTBase, and ultimately Cassandra:
{"type":"https://mediawiki.org/wiki/HyperSwitch/errors/update_error","title":"Internal error in Cassandra table storage backend","method":"get","uri":"/de.wikipedia.org/v1/page/html/Benutzer%3AHerzi_Pinki%2FsyncTest/243290995","internalURI":"https://restbase-async.discovery.wmnet:7443/de.wikipedia.org/v1/page/html/Benutzer%3AHerzi_Pinki%2FsyncTest/243290995","internalMethod":"get"}ResponseError: Server timeout during read query at consistency LOCAL_QUORUM (2 replica(s) responded over 3 required)
at FrameReader.readError (/srv/deployment/restbase/deploy-cache/revs/7e5e72087d8331131669babfb8f40b269c024cd7/node_modules/cassandra-driver/lib/readers.js:326:15)
at Parser.parseBody (/srv/deployment/restbase/deploy-cache/revs/7e5e72087d8331131669babfb8f40b269c024cd7/node_modules/cassandra-driver/lib/streams.js:194:66)
at Parser._transform (/srv/deployment/restbase/deploy-cache/revs/7e5e72087d8331131669babfb8f40b269c024cd7/node_modules/cassandra-driver/lib/streams.js:137:10)
at Parser.Transform._read (_stream_transform.js:191:10)
at Parser.Transform._write (_stream_transform.js:179:12)
at doWrite (_stream_writable.js:403:12)
at writeOrBuffer (_stream_writable.js:387:5)
at Parser.Writable.write (_stream_writable.js:318:11)
at Protocol.ondata (_stream_readable.js:718:22)
at Protocol.emit (events.js:314:20)
at addChunk (_stream_readable.js:297:12)
at readableAddChunk (_stream_readable.js:272:9)
at Protocol.Readable.push (_stream_readable.js:213:10)
at Protocol.Transform.push (_stream_transform.js:152:32)
at Protocol.readItems (/srv/deployment/restbase/deploy-cache/revs/7e5e72087d8331131669babfb8f40b269c024cd7/node_modules/cassandra-driver/lib/streams.js:109:10)
at Protocol._transform (/srv/deployment/restbase/deploy-cache/revs/7e5e72087d8331131669babfb8f40b269c024cd7/node_modules/cassandra-driver/lib/streams.js:32:10)This error indicates a read timeout while attempting a LOCAL_QUORUM, specifically that only two copies responded during the timeout period, when at least 3 were required. What is puzzling here, is that each data-center only holds 3 replicas, so a LOCAL_QUORUM is in fact 2 copies!
Working hypothesis
There was a decommission running in eqiad at the time of the switchover (T354561). Decommissions (and bootstraps) temporarily increase the replication by one (to include the node joining/leaving), and enforce consistency level requirements for writes. This is necessary to maintain consistency guarantees and bootstrap/decommission atomicity. The failed operations were reads, but these tables have blocking read repair enabled which means that (blocking) writes can be triggered (probabilisticly?) by a read. This would help explain the biggest mystery, namely: Why a read operation would fail with such an unexpected quorum requirement.
This still does not explain why this larger than expected quorum would fail; Even a quorum of 3 should succeed in an otherwise healthy cluster (the odd transient/spurious failure notwithstanding). CASSANDRA-19129 might offer the final piece to this puzzle.
Next steps
Terminate the decommission to see if the errors cease. If they do, disable blocking read-repair and attempt another decommission. If the errors do not return, we can assume CASSANDRA-19129 is the culprit, and either backport the patch, or wait for a 4.1.5 release.