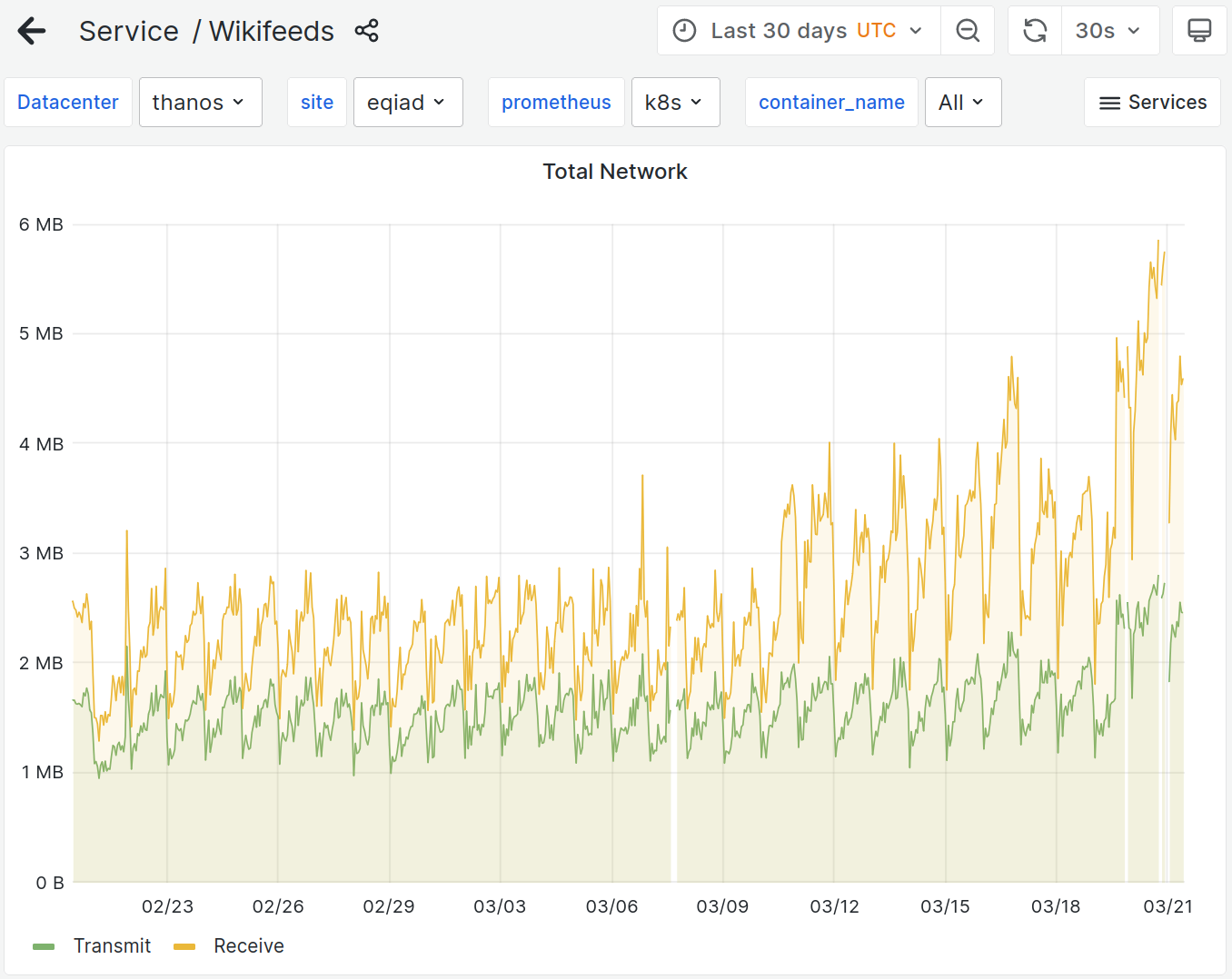
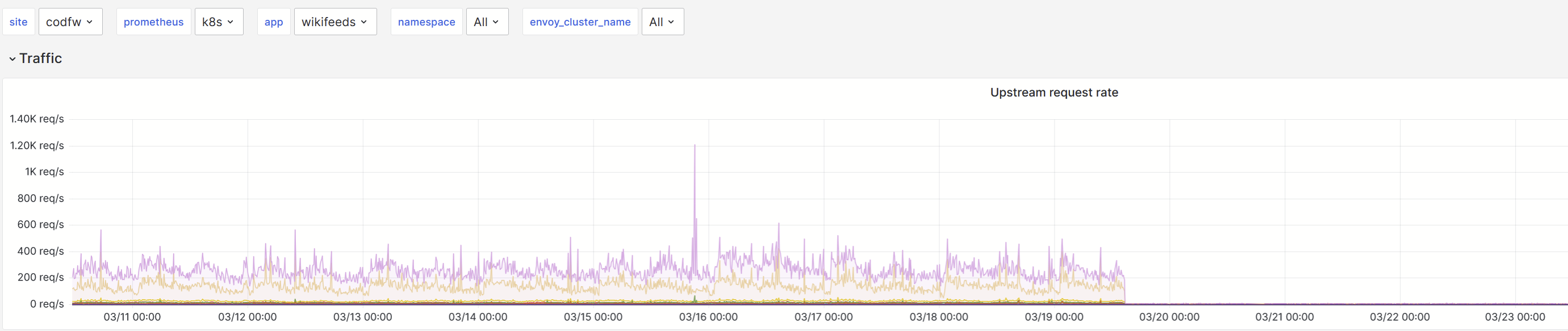
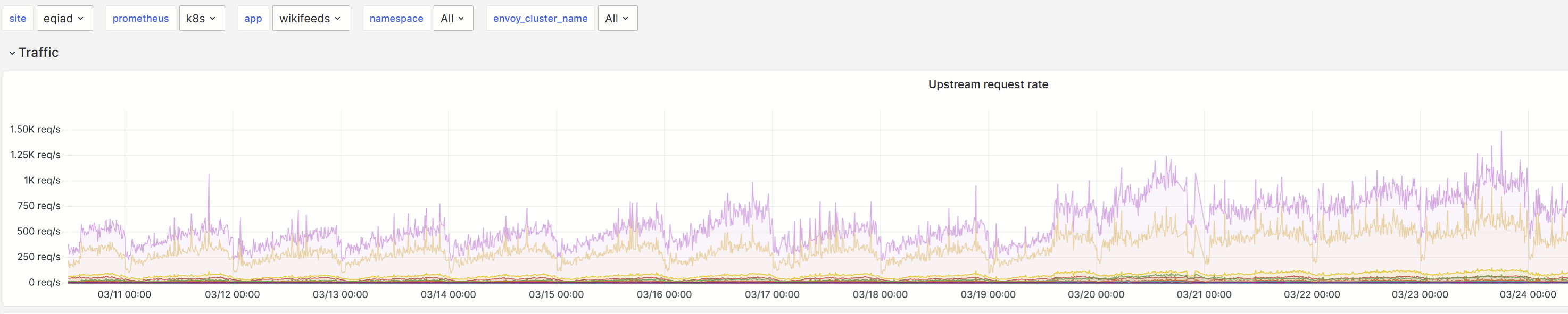
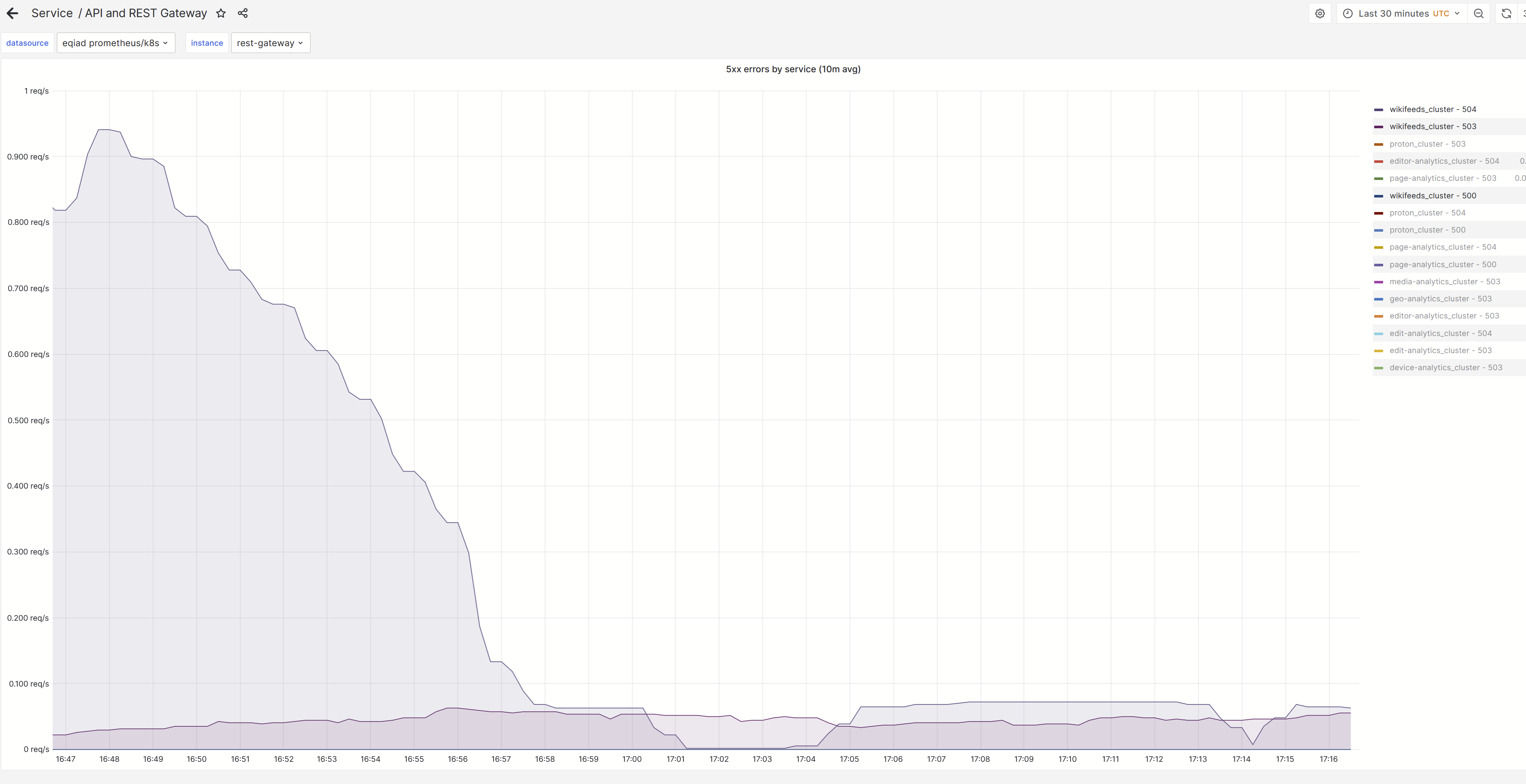
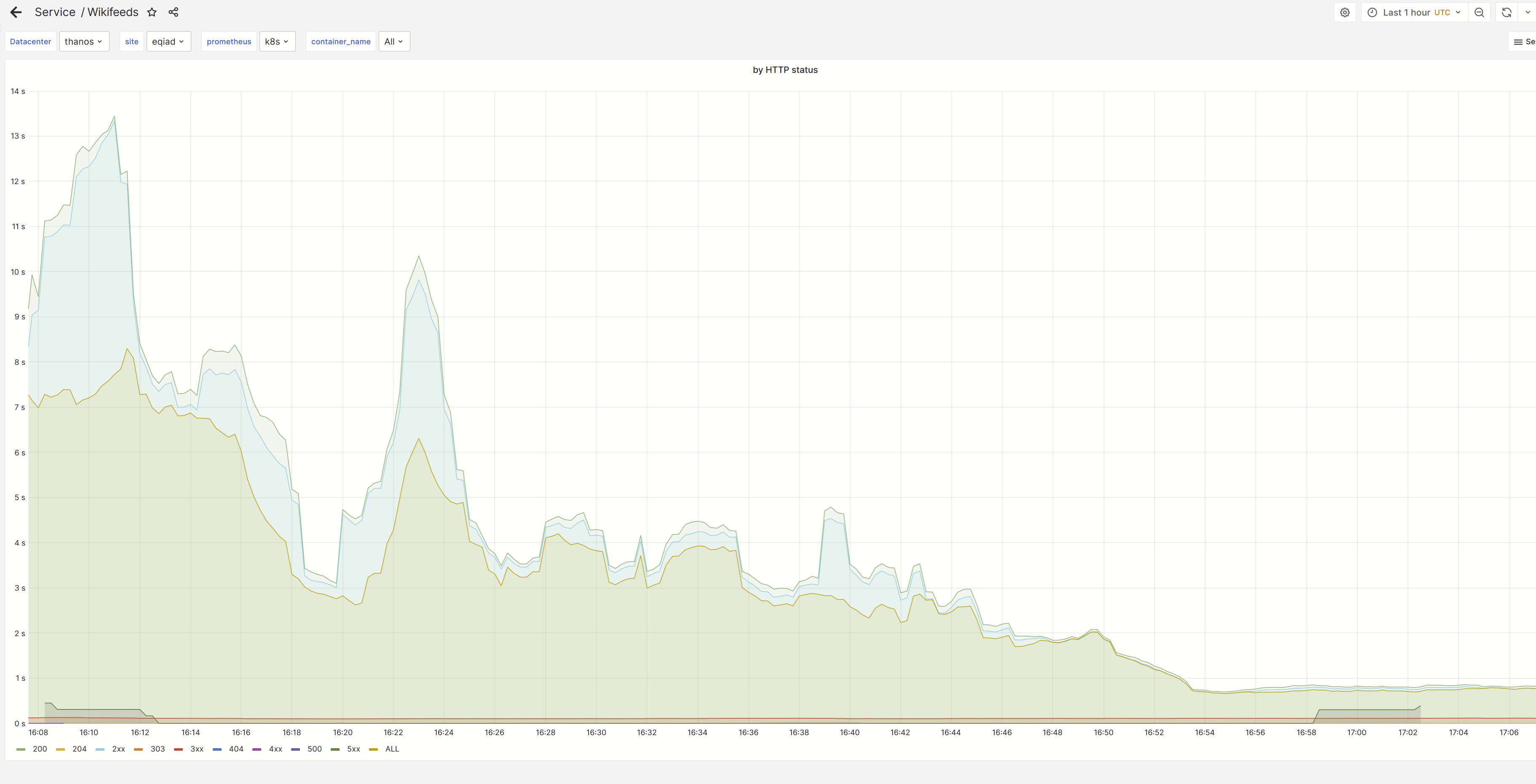
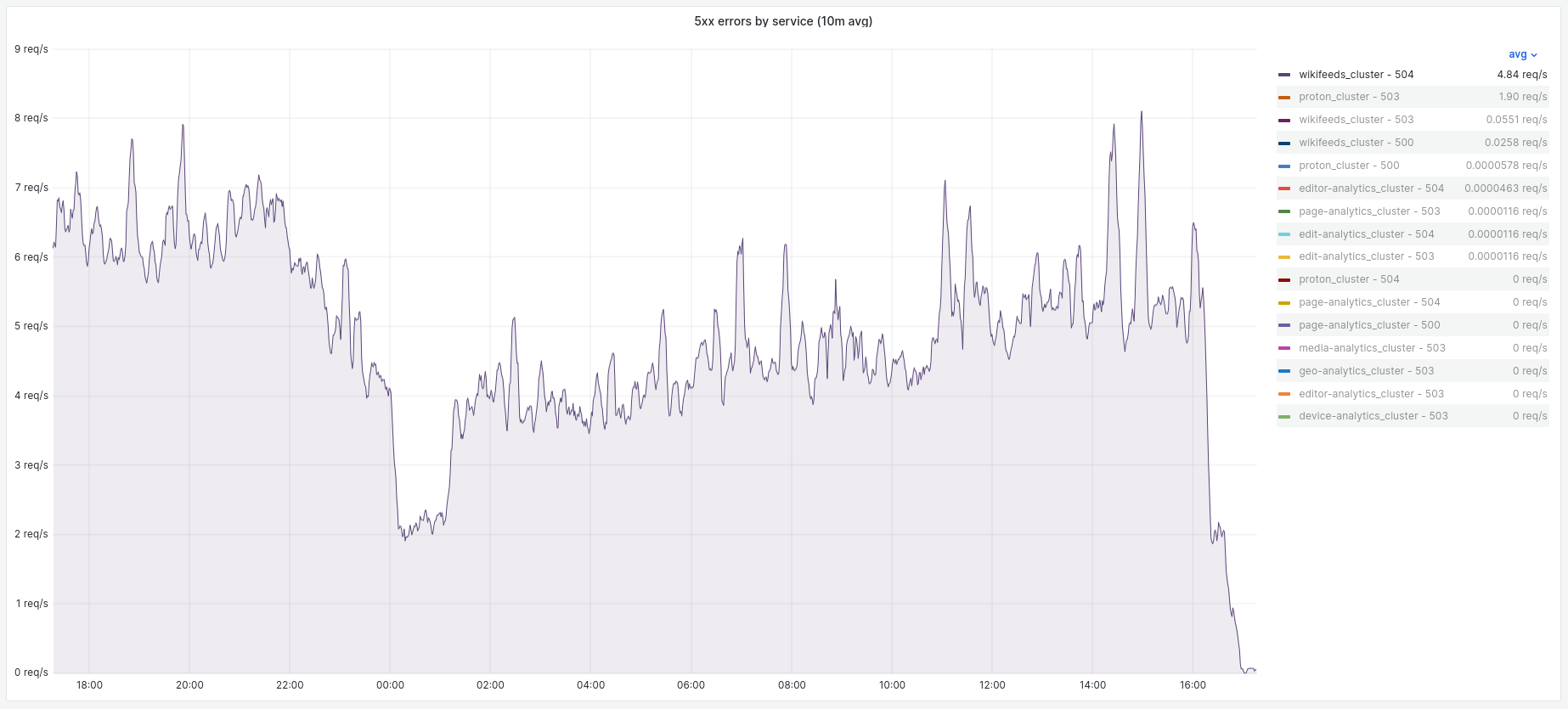
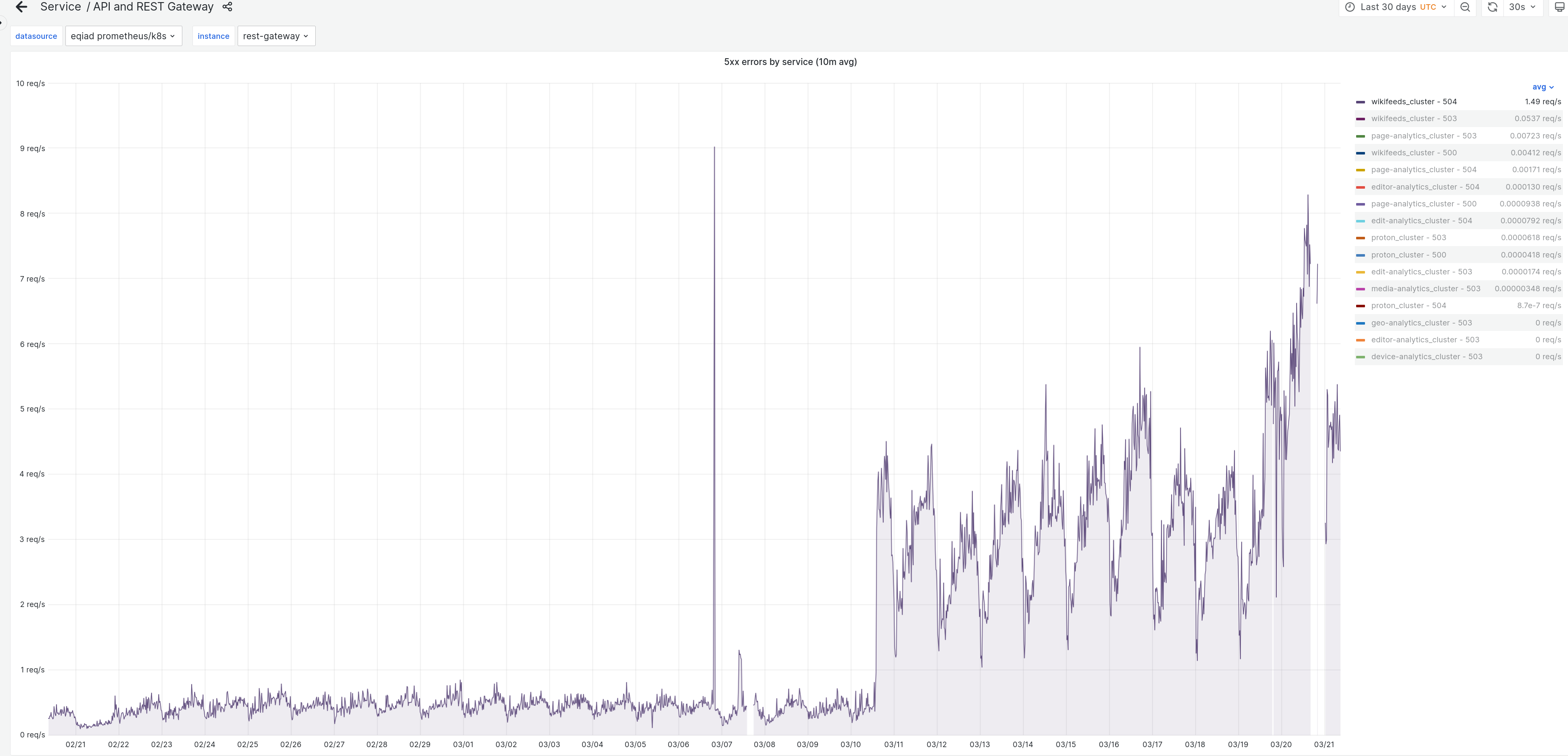
Since march 10th, the rest gateway is seeing an increased rate of timeouts from wikifeeds:
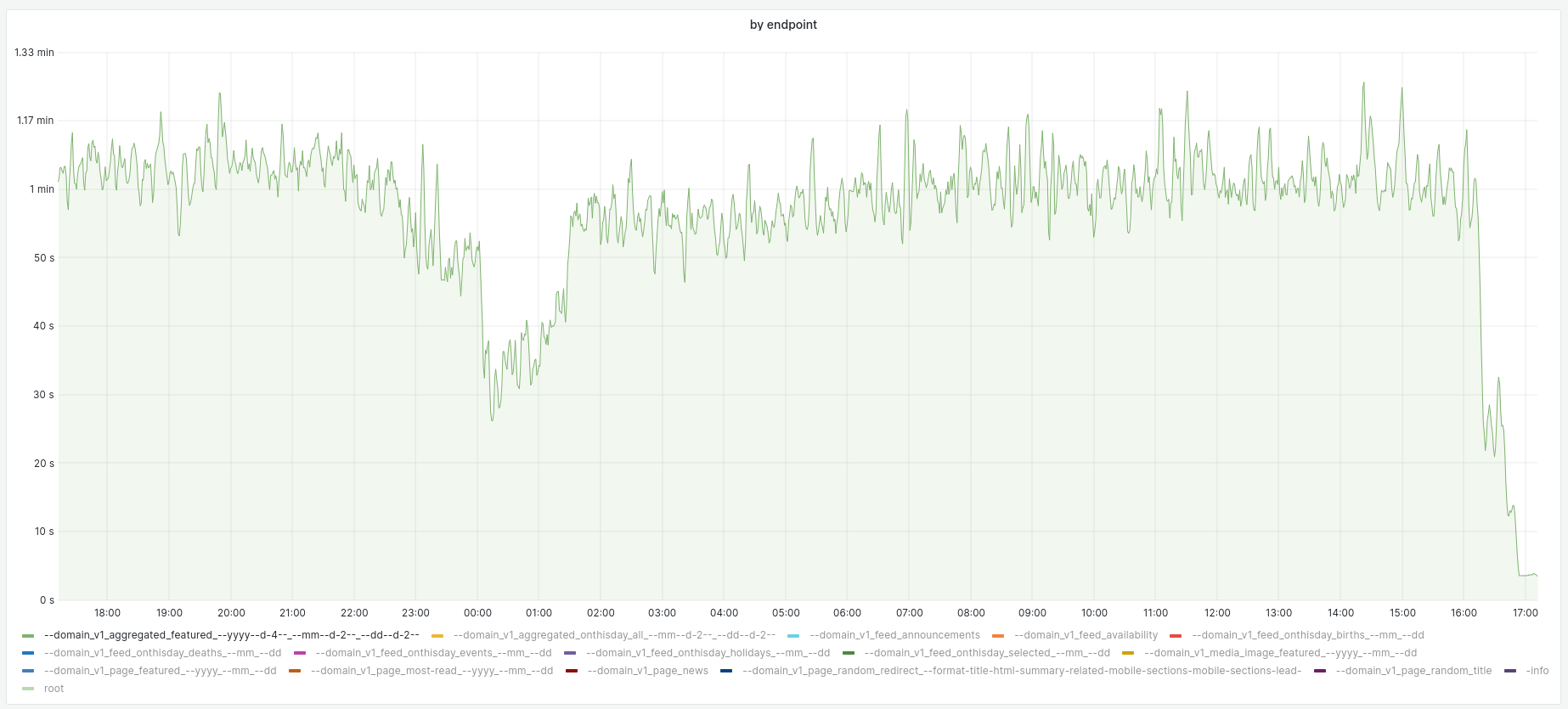
which, upon inspection, seem to all come from the "featured feed" endpoints.
Specifically, it looks like the "domain_v1_aggregated_featured" latency went from around 10 seconds to 1 minute as p99 (!!!)
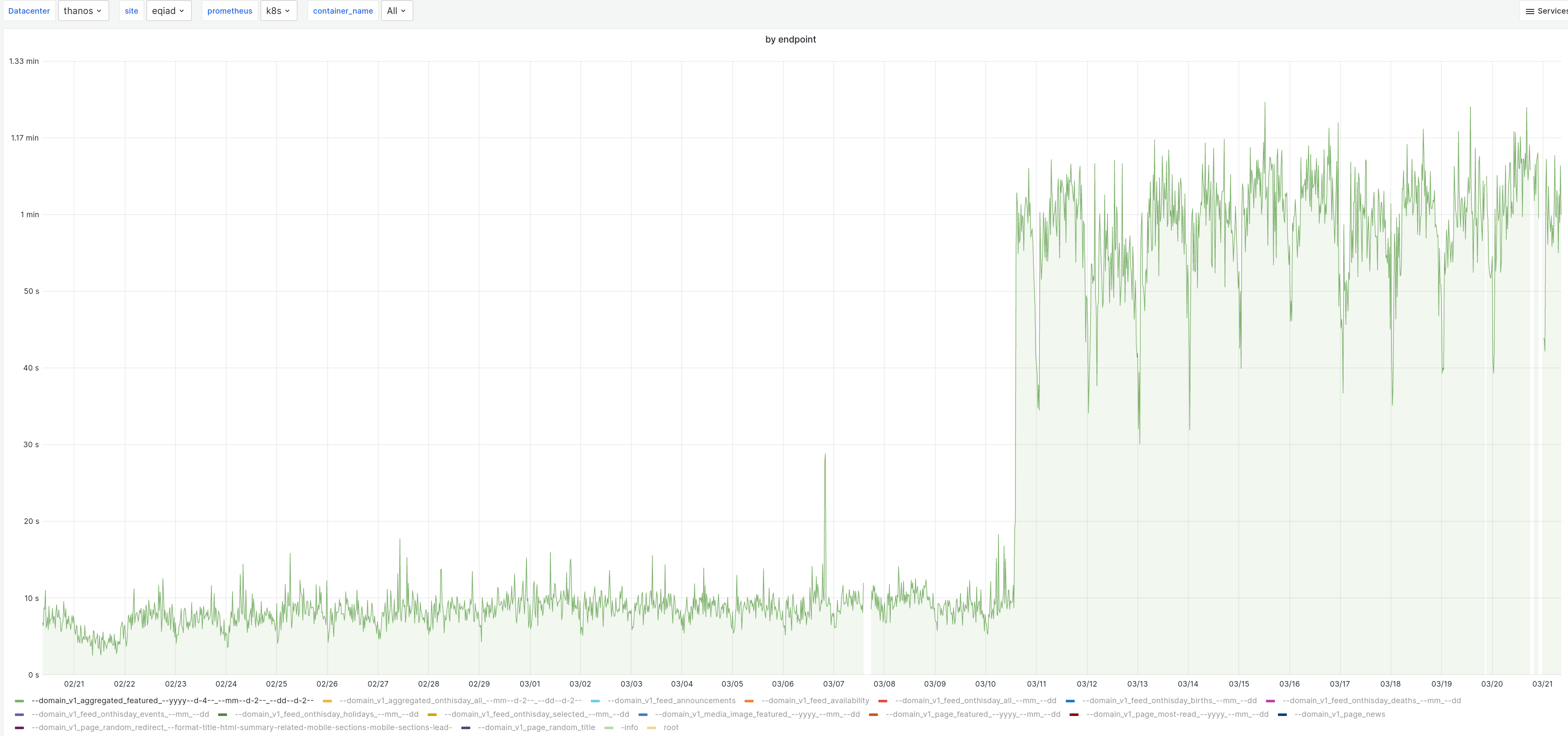
and also domain_v1_feed_onthisday_selected"
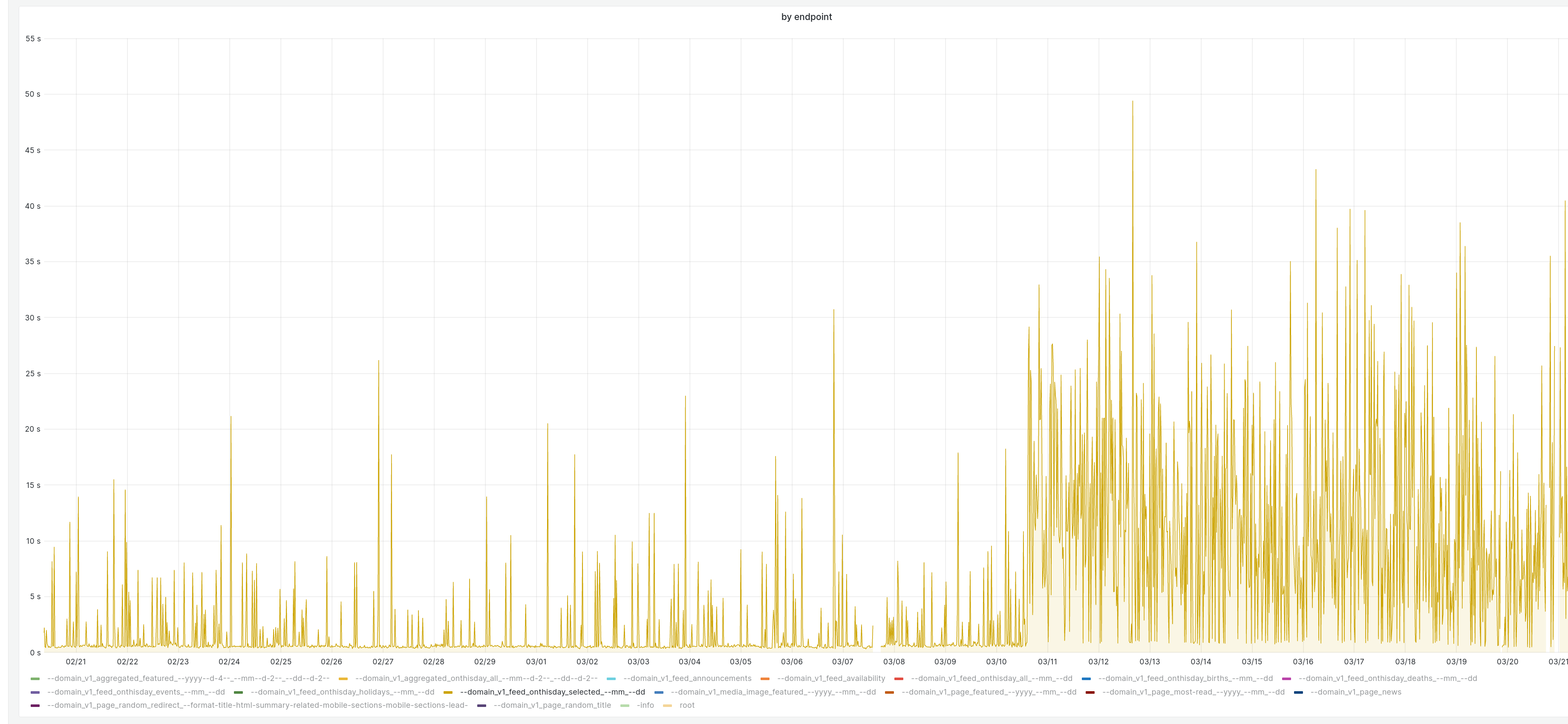
this also reflects on the overall average latency from the service:
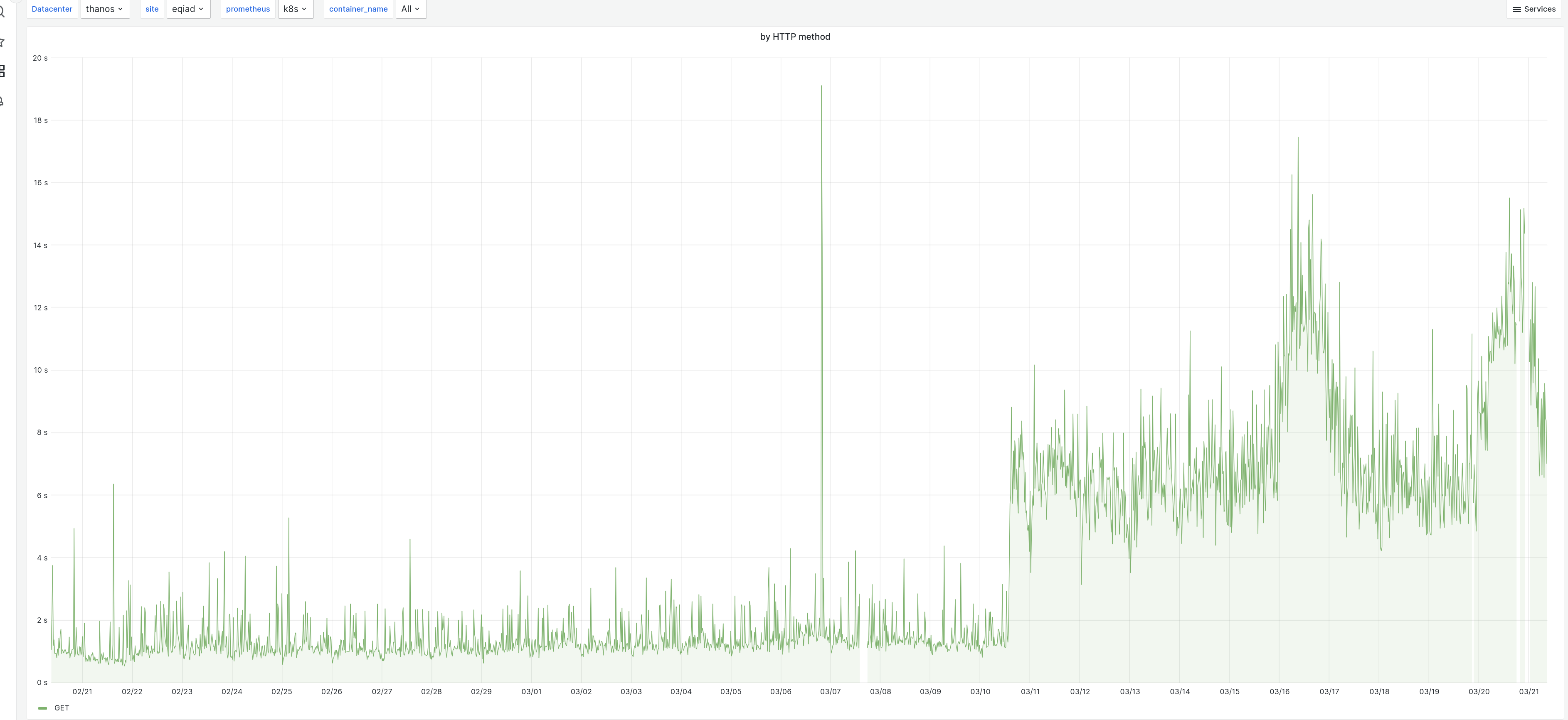
We already tried adding resources to the service and a rolling restart; neither had any effect on the timeouts or the latencies.
These p99 seem hardly acceptable from a service like wikifeeds. Any idea what happened on that date?
I'm tagging the Content-Transform-Team as they should know what's the status of this.