
User Details
- User Since
- May 5 2020, 11:24 AM (207 w, 3 d)
- Availability
- Available
- IRC Nick
- nemo-yiannis
- LDAP User
- Jgiannelos
- MediaWiki User
- JGiannelos (WMF) [ Global Accounts ]
Tue, Apr 23
PCS now serves mobile-html with data-file-original-src to indicate that the image was upscaled.
Hi, is there any update with dev access for PCS devs?
Fri, Apr 19
Thu, Apr 18
From a quick look this is the <p> element that its chosen instead of the actual first paragraph:

Mon, Apr 15
Fri, Apr 12
After a bit of debugging this looks like its the issue:


The svg renders 2 elements for parsoid but one with legacy parser output.
Thu, Apr 11
For now it looks like working on an extension with good abstractions so it can easily be implemented in core looks like the most feasible way forward.
I boostrapped the extension code for the prototyping work here:
https://gitlab.wikimedia.org/repos/content-transform/pagesummary
Wed, Apr 10
Tue, Apr 9
Mon, Apr 8
It failed again but with a different error:
:* restbase1030.eqiad.wmnet
09:48:11 ['/usr/bin/scap', 'deploy-local', '-v', '--repo', 'restbase/deploy', '-g', 'canary', 'fetch', '--refresh-config'] (ran as deploy-service@restbase1030.eqiad.wmnet) returned [70]: Registering scripts in directory '/srv/deployment/restbase/deploy-cache/revs/c4d19d7c4e2b4e8d16cd12677d44b42962c05917/scap/scripts'
Fetch from: http://deploy1002.eqiad.wmnet/restbase/deploy/.git
Running ['git', 'remote', 'set-url', 'origin', 'http://deploy1002.eqiad.wmnet/restbase/deploy/.git'] with {'cwd': '/srv/deployment/restbase/deploy-cache/cache', 'stdout': -1, 'stderr': -1, 'text': True, 'stdin': -3}
Running ['git', 'fetch', '--tags', '--jobs', '38', '--no-recurse-submodules'] with {'cwd': '/srv/deployment/restbase/deploy-cache/cache', 'stdout': -1, 'stderr': -1, 'text': True, 'stdin': -3}
Running ['git', 'config', 'lfs.url', 'https://gerrit.wikimedia.org/r/p/mediawiki/services/restbase/deploy.git/info/lfs'] with {'cwd': '/srv/deployment/restbase/deploy-cache/cache', 'stdout': -1, 'stderr': -1, 'text': True, 'stdin': -3}
Update submodules
git submodule sync
Running ['git', 'submodule', 'sync', '--recursive'] with {'cwd': '/srv/deployment/restbase/deploy-cache/cache', 'stdout': -1, 'stderr': -1, 'text': True, 'stdin': -3}
Fetch submodules
Remapping submodule /srv/deployment/restbase/deploy-cache/cache to http://deploy1002.eqiad.wmnet/restbase/deploy/.git
Updating .gitmodule: /srv/deployment/restbase/deploy-cache/cache
Running ['git', 'checkout', '.gitmodules'] with {'cwd': '/srv/deployment/restbase/deploy-cache/cache', 'stdout': -1, 'stderr': -1, 'text': True, 'stdin': -3}
Running ['git', 'config', '--list', '--file', '.gitmodules'] with {'cwd': '/srv/deployment/restbase/deploy-cache/cache', 'stdout': -1, 'stderr': -1, 'text': True, 'stdin': -3}
git submodule sync
Running ['git', 'submodule', 'sync', '--recursive'] with {'cwd': '/srv/deployment/restbase/deploy-cache/cache', 'stdout': -1, 'stderr': -1, 'text': True, 'stdin': -3}
Running ['git', 'submodule', 'update', '--init', '--recursive', '--jobs', '38'] with {'cwd': '/srv/deployment/restbase/deploy-cache/cache', 'env': {'SHELL': '/bin/bash', 'PWD': '/var/lib/deploy-service', 'LOGNAME': 'deploy-service', 'XDG_SESSION_TYPE': 'tty', 'MOTD_SHOWN': 'pam', 'HOME': '/var/lib/deploy-service', 'LANG': 'en_US.UTF-8', 'SSH_CONNECTION': '10.64.32.28 43578 10.64.48.228 22', 'XDG_SESSION_CLASS': 'user', 'USER': 'deploy-service', 'SHLVL': '0', 'XDG_SESSION_ID': '47018', 'XDG_RUNTIME_DIR': '/run/user/497', 'SSH_CLIENT': '10.64.32.28 43578 22', 'PATH': '/usr/local/bin:/usr/bin:/bin:/usr/games', '_': '/usr/bin/scap', 'PHP': 'php7.4', 'SSH_AUTH_SOCK': '/run/keyholder/proxy.sock', 'GIT_LFS_SKIP_SMUDGE': '1'}, 'stdout': -1, 'stderr': -1, 'text': True, 'stdin': -3}
Setting lfs.url of restbase to https://gerrit.wikimedia.org/r/mediawiki/services/restbase/info/lfs
Running ['git', 'config', 'lfs.url', 'https://gerrit.wikimedia.org/r/mediawiki/services/restbase/info/lfs'] with {'cwd': '/srv/deployment/restbase/deploy-cache/cache/restbase', 'stdout': -1, 'stderr': -1, 'text': True, 'stdin': -3}
Unhandled error:
deploy-local failed: <FileNotFoundError> {}Fri, Apr 5
I added 4800 new titles from hewikivoyage:
MariaDB [parsoid_rv_deploy_targets]> SELECT prefix, COUNT(*) FROM pages GROUP BY prefix; +--------------+----------+ | prefix | COUNT(*) | +--------------+----------+ | enwikivoyage | 24615 | | hewikivoyage | 4800 | +--------------+----------+ 2 rows in set (0.137 sec)
Thanks @hashar
jgiannelos@deploy1002:/srv/deployment/restbase/deploy$ git tag -d scap/sync/2024-02-19/0011 Deleted tag 'scap/sync/2024-02-19/0011' (was d3425717)
Thu, Apr 4
Should be fixed in prod:
MCS is still used by kiwix. I think wikiwand has stopped using the endpoint.
Things look better on staging:
From staging:
{
"status": 500,
"type": "internal_error",
"title": "ArgumentError",
"detail": "Datacenter eqiad was not found. Available DCs are: [codfw]",
"method": "GET",
"uri": "/en.wikipedia.org/v1/page/mobile-html/Dog"
}Wed, Apr 3
I think the problem is on the nodejs cassandra client TLS initialization and more specifically on how we pass the config options.
From staging:
I am testing things on staging and I am getting this error (and a CrashLoopBackOff from the pod):
ENOENT: no such file or directory, open '/etc/ssl/certs/wmf-ca-certificates.crt'",
Tue, Apr 2
Thu, Mar 28
I verified the ticket on mobile-html endpoint. Indeed the pins don't match between desktop and mobile-html.
This is also not reproducible in parsoid either so it must be a transformation on the PCS level that moves the pins to the wrong position.
Mar 27 2024
Pending from initial parsoid patch:
- Tests for
- [[Category:Foo|{{1x|}}]] (missing sort key)
- [[Category:Foo|Category:Foo]] (category as sort key)
- [[Category:Foo|\n]] (newline as sort key)
- Sort key that is language converted
Mar 25 2024
So the root cause looks like is the following:
It looks like errors/latency are stabilized after depooling some nodes:
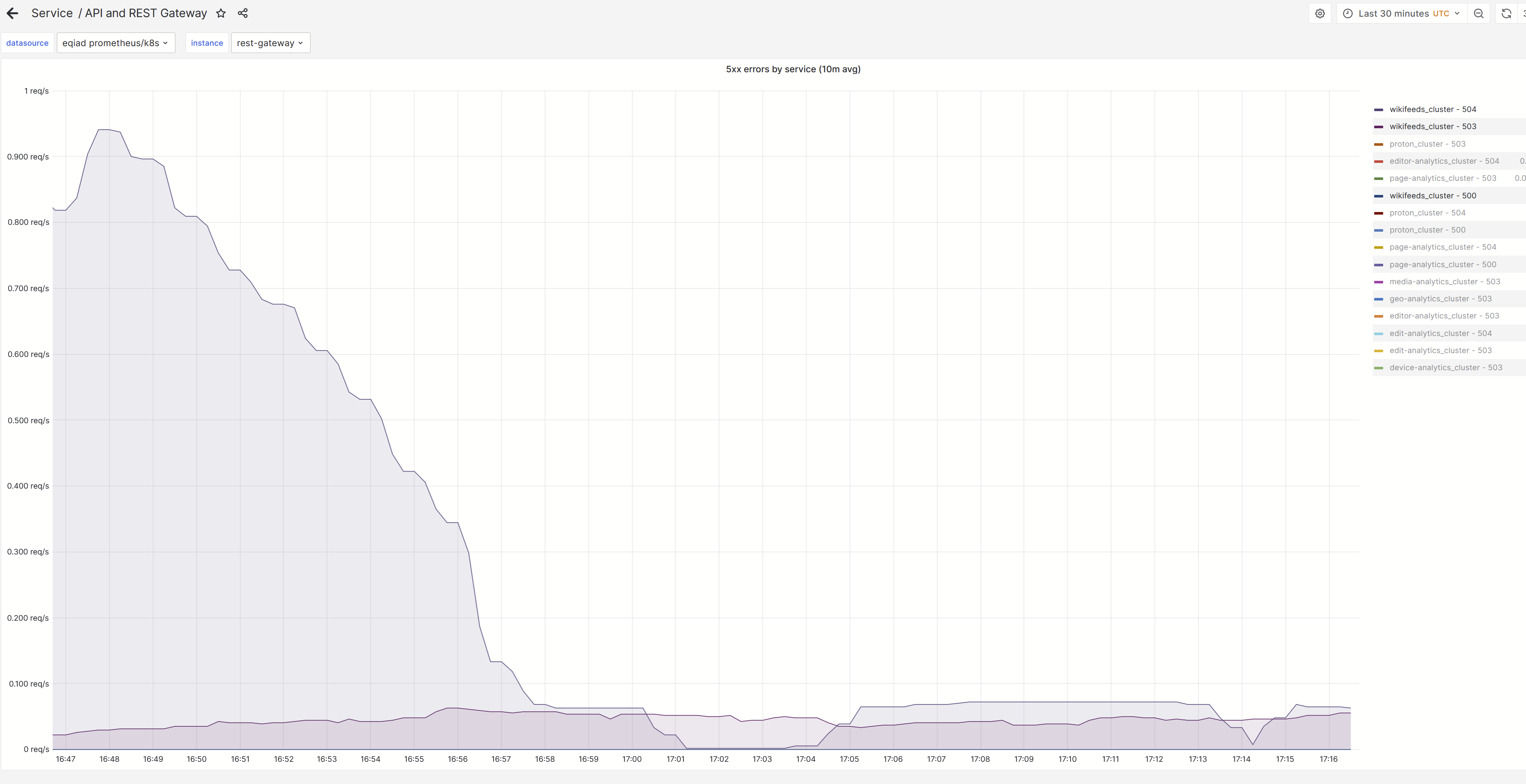
It looks like this path was not deployed using scap:
https://gerrit.wikimedia.org/r/c/mediawiki/services/restbase/deploy/+/1009842
From the URLs from logstash as @hnowlan pointed out it looks like the main cause of timeouts is outgoing requests to v1/<domain>/page/summary/<title> and more specifically to media files (svg, png, webm).
From restbase:
jgiannelos@deploy1002:~$ curl -v restbase.svc.codfw.wmnet:7233/fr.wikipedia.org/v1/page/summary/Fichier%3ACleopatra_poster.jpg
I was trying to see if there is a correlation between this issue and switching over parsoid from restbase to MW core but it doesn't look something is related.
From logs I think there are 2 things to investigate:
- What happened since ~10th March ?
- Why traffic was completely dropped on the 19th of March on codfw?
- Could be related to the datacenter switchover ?
- Meanwhile eqiad kept having traffic before and after that time.
Mar 15 2024
Mar 14 2024
Metrics looks better now after the backport fix:
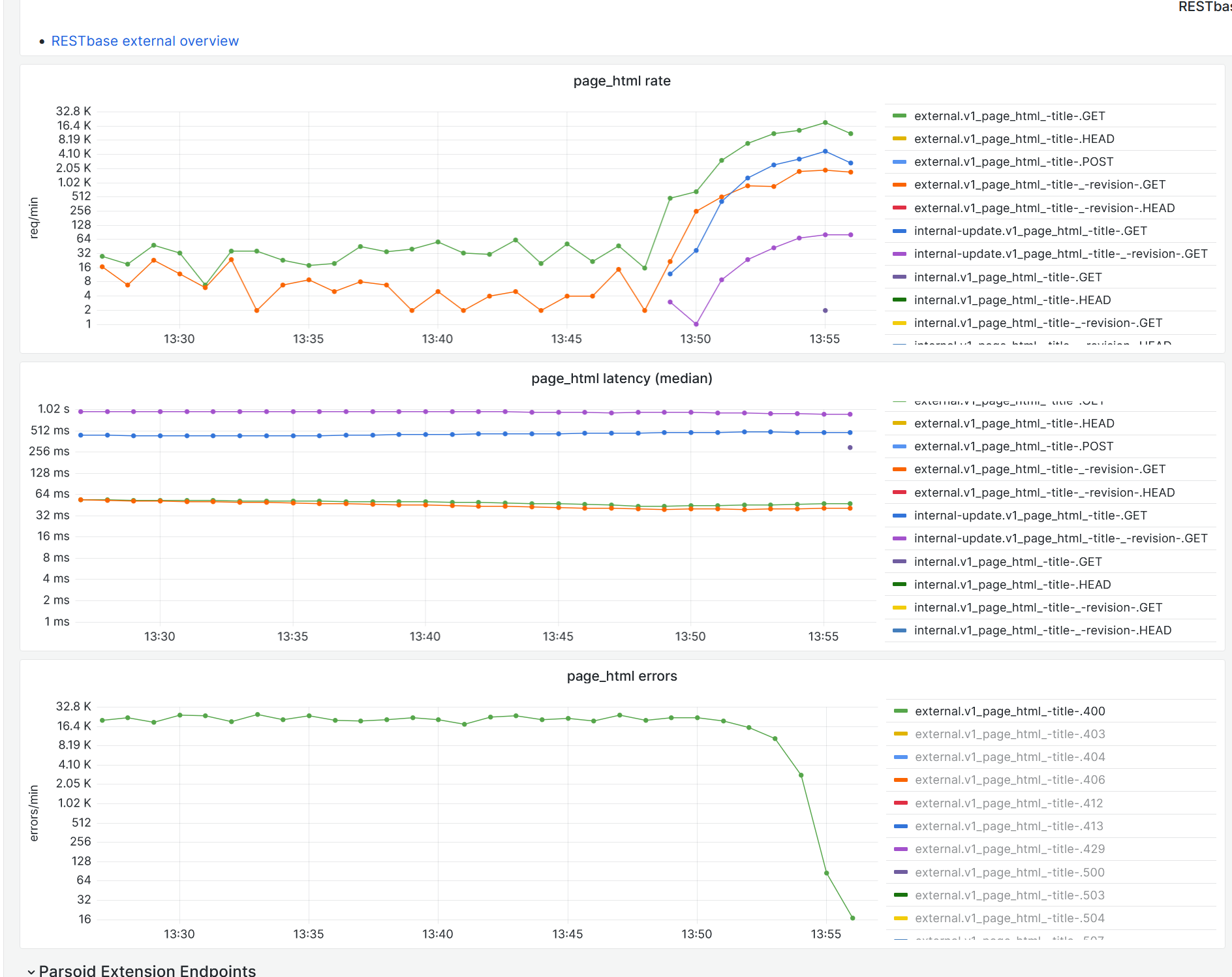
It looks like this fix was backported last week as a hotfix: https://gerrit.wikimedia.org/r/c/mediawiki/core/+/1009542
But never merged to master so now the same bug got triggered.