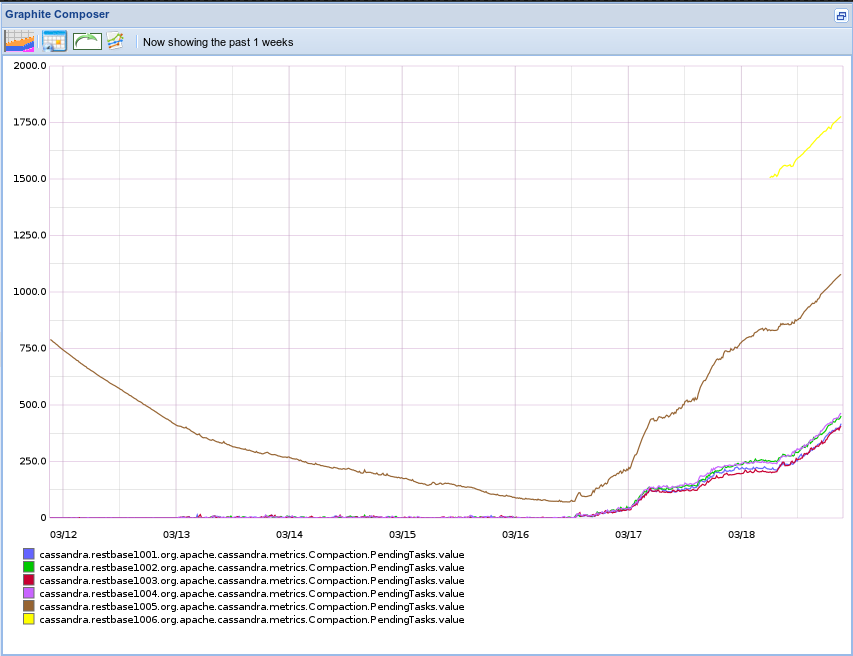
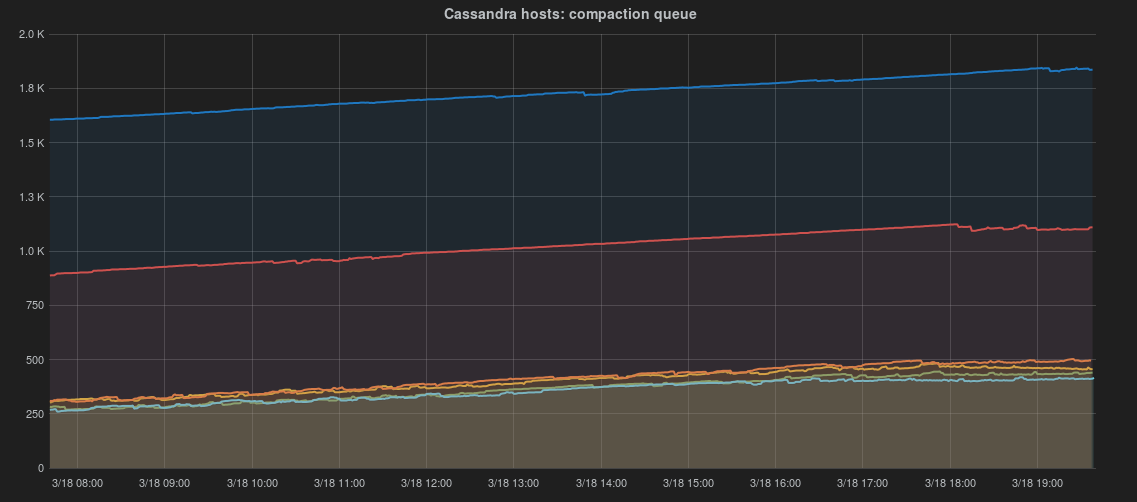
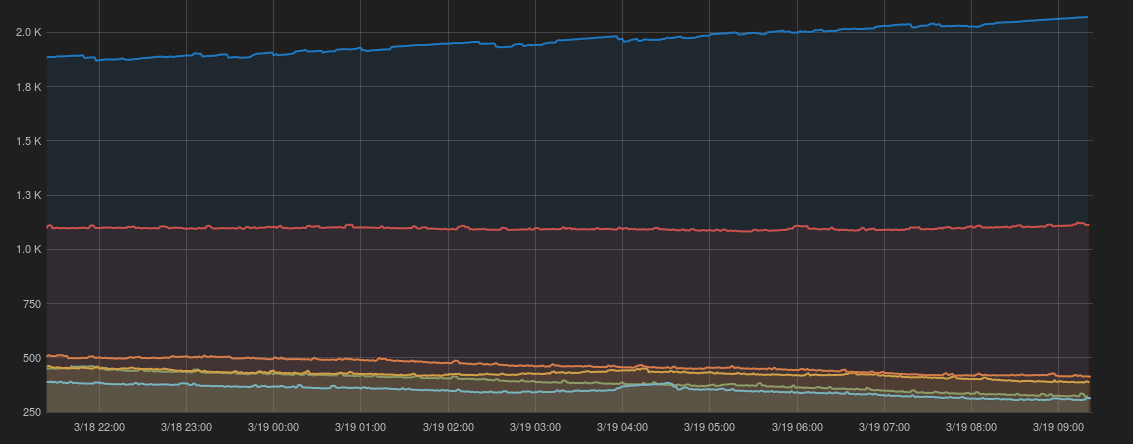
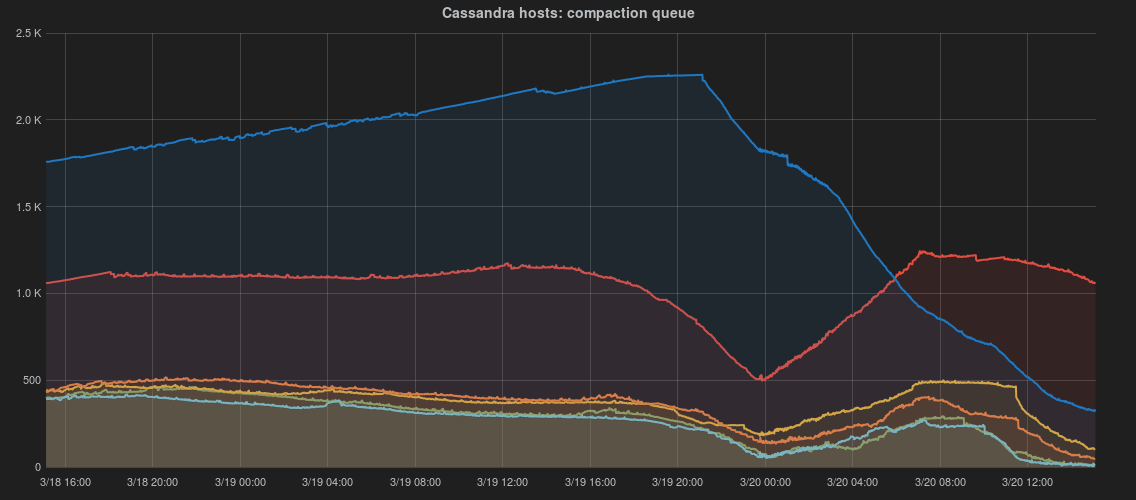
Since RESTBase's release, the number of pending compactions in Cassandra has been trending upward. This will eventually cause problems.
Throughput is currently set to the default of 16MB/s, which is quite conservative for our environment, particularly given our use of Leveled Compaction.
If there are no objections, I'm going to start gradually increasing it (ephemerally, using nodetool), and observe the results.