
The problem
BGP binds the internet together by standardizing a way for all networks to tell their neighbors “If you want to reach IP X, send the packets to network Y”. BGP is great for its resiliency and scalability, but less so for its security.
How can we know which network (Autonomous System) is the legitimate owner of an IP? Without that information, IPs can easily get hijacked, either accidentally or maliciously.
Since the late 90s, databases named Internet Routing Registries (IRR) have been trying to fulfill that (single) source of truth role. Unfortunately, they are subject to a lot of issues: fragmentation (many existing databases, not all equally well-maintained), security (some databases allow anyone to “claim” a prefix) and complexity (for the network operators). They also contain a lot of inaccurate data that have accumulated over time.
The first question that comes to mind is “why not fix what already exists instead of re-inventing the wheel?” Some efforts are being made on that, especially since IRR have a broader scope than just associating IPs to operators. Reciprocally, the Resource Public Key Infrastructure's (RPKI) scope is focused on enforcing IP/AS ownership, not replacing IRRs.
Second question is, how to make sure RPKI data doesn’t become similarly inaccurate? I believe that IRRs became stale/outdated because only a few providers were rejecting prefixes based on this information. Hopefully the documentation, simplicity and existing tooling for RPKI will democratize its adoption and make inaccuracies easy to spot and quick to remedy.
The solution
From an operator perspective, RPKI works with 2 interdependent parts:
- Signing: tell the world which prefixes have been delegated to one's AS
- Validation: prevent one's network from routing traffic to hijacked networks
Signing
Just a brief summary as there are a lot of resources available online.
Some points to highlight though:
- It’s the one step to make your prefixes safer.
- It’s very easy to do through RIR’s online signing tools
- although these tools are of varying quality
- One should setup monitoring for their ROAs (especially expiration). Some RIRs offer that option (e.g. RIPE).
- One should not create a ROA with prefixes more specific than your routing policy (e.g. if you only ever advertises a /22 don't add the more specific /24 to your ROA)
Validation
How does it work?
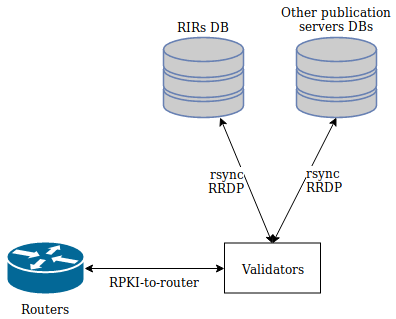
Everything starts with a validator, also called RPKI Relying Party software. Many open source implementations exist, in various languages with relatively similar features: RPKI Validator, OctoRPKI, Routinator, RPKI Toolkit, FORT Validator, rpki-client.
RPKI works as a chain of trust, and the 1st level of that chain are the RIRs. To know how to reach that 1st level (the Trust Anchors), the validator needs a file called a Trust Anchor Locator (TAL), which is a pointer to each RIR’s RPKI repository or any repository you trust, as well as their public key.
TALs are present on each RIR’s website and validators include most of them. ARIN’s is an exception as users are required to agree to the ARIN Relying Party Agreement.
The RPKI repository contains either ROAs (Route Origin Authorization) or pointers to other repositories, themselves containing ROAs trusted by the upstream repository.
ROAs are signed database items saying “Prefix X is allowed to be advertised by AS Z”. Those items also have a creation and expiration date. There is no limitation on how many prefixes can be advertised by an AS, or the other way around.
Validators will fetch the ROAs from all the available repositories using rsync or RRDP (over HTTPS).
Validators will then verify the ROAs (i.e. make sure the format and the signature are correct). Everything that can’t be verified at this level will be ignored. For example, if a ROA expired, it will be ignored (as if it were not in the repository). This prevents any risk of a prefix becoming unreachable if its owner forgets to “renew” its ROA.
The validator is decoupled from the router for performance reasons. Routers usually have high routing performances, but very little resources for any other tasks.
Now that we have a curated and verified list of prefixes/ASNs pairs, we have to communicate it to the router. For that the Validator uses the RTR (RPKI-To-Router) protocol. Most of the time this is embedded in the validator, but standalone applications like GoRTR also exist.
The RFC recommends encrypted transport such as SSH and TLS however they do not insist on encryption. This risk is mitigated by ensuring that "If unprotected TCP is the transport, the cache and routers MUST be on the same trusted and controlled network".
Like everything, it is also recommended to run more than one validator, to ensure no interruption in prefix validation. Note that here as well, the risk of unreachable prefixes is prevented by a timeout period (for example 1 hour on Junos) where if the router is unable to reach the validator it will begin ignoring validation.
The router will check every prefix learned (asynchronously, thus not impacting the BGP convergence time) against its internal RPKI database, which is periodically synced with the validator. Each BGP prefix will then have one of the 4 labels:
- Valid, the BGP prefix is originating from an AS and the proper matching ROA is on file
- Invalid, the BGP prefix is covered by a ROA, but the origin AS is not in any ROA
- Unknown, the BGP prefix doesn’t have any matching ROA (most of the Internet so far)
- Unverified, the router didn't check that prefix against its database yet
The most important and useful one here is the Invalid state, which indicates a misconfiguration at best, a malicious hijack at worse.
The last step is for the router to do something useful with this new information.
For the Invalid prefixes received from your peers:
- Lower the local preference. This can be useful as a proof of concept, but only protects against a very narrow situation: where a prefix of similar size but different origin AS is learned from multiple peers. This could potentially save the day after a misconfiguration in the DFZ (Default-Free Zone), but would not protect from a malicious actor advertising a more specific prefix.
- Discard. More difficult decision, especially as long as RPKI unreachable prefixes exist, which are IPs on the Internet without any larger/smaller prefix than the Invalid ones. This will cause them to become “invisible” to your network. Operators have to consider if this risk is worth the extra security? To help make that call, Pmacct can now show how much traffic, if any, is being exchanged between your network and those IPs.
A good first move is to discard invalids on your IXP facing links, for two reasons:
- Eliminates the risk of unreachable prefixes, as traffic will reroute through transit links. Worse case scenario is now sub-optimal routing. It’s also easier to reach out to peers to ask them to fix their ROAs.
- Prefixes learned from IXPs usually have a very short AS path. A rogue prefix originating from there would most likely be preferred over one learned through a transit.
For the Invalid prefixes advertised to your downstreams:
- Add a BGP community to the valid and invalids prefixes you’re forwarding down. This allows customers to make their own routing decisions, without having to deploy a full RPKI infra. This means your customers are placing their trust in you as such you must not blindly forward communities you have learned from untrusted peers.
- Discard. This can be done progressively, customer after customer before a global discard.
Tadam, the Internet is a bit more secure, thank you!
(Check your NOC mailbox just in case.)
Monitoring
Before you start dropping prefixes, better make sure everything is healthy.
Additionally, people who will respond to alerts and “I can’t reach X” emails should be trained on how to react.
Some validators (such as OctoRPKI or Routinator) provide Prometheus endpoints exposing various metrics.
For the router side, a draft RFC for a RTR MIB exists, but I’m not aware of any implementations. Syslog is more or less an option as well. Tools like junos-pyez or NAPALM with some custom parsing seems to be the most complete option so far.
What doesn’t it protect against?
Your own prefixes
First of all, doing validation doesn’t protect your own prefixes, as it only impacts outbound traffic. The two things you can do for that is sign your prefixes and advocating for more people to deploy RPKI.
Transit (or any intermediary AS) not doing validation
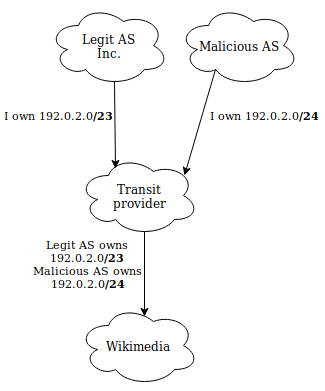
In the above diagram, even if Wikimedia discards the malicious /24, it would send traffic for 192.0.2.1 to its transit provider (as it’s the best next-hop for the /23). The transit not doing any validation would naturally forward that traffic to the malicious AS as it is advertising a more specific.
How to mitigate it?
- Peer with as many networks as possible (the shorter the AS path, the better)
- Peer with networks doing RPKI validation (maybe we should keep a hall of fame somewhere?)
- Advertise only /24s (and /48s v6)
Disaggregating has the adverse effect of increasing the size of the global routing table, which in many cases is frowned upon by the operators community. Decision to do so needs not to be taken lightly.
AS forgery
RPKI only ensure that the prefix is being advertised by the proper AS#. A malicious network could either change the AS# from the prefixes it’s advertising (to pretend to be the valid source AS) or fake a longer AS PATH (pretending to be transit for the target network). Very unlikely to be the result of a misconfiguration.
How to mitigate it?
- Peer with as many networks as possible (the shorter the AS path, the better)
- Advertise only /24s (and /48s v6), with the same warning as above
- Monitor prefixes AS PATHS and contact the rogue network’s upstream
Man in the middle
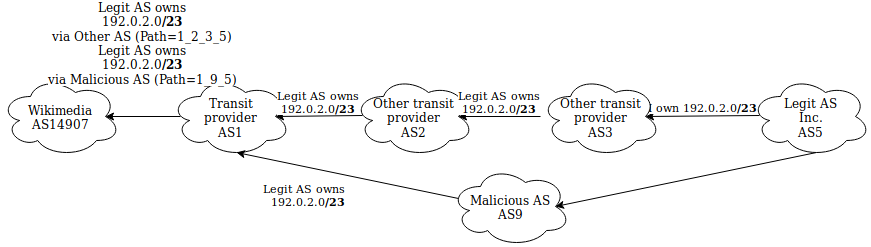
Slightly related to the point above, RPKI is vulnerable to all kinds of MitM attacks as it only validates the source AS, not the whole path.
Take the example above. A malicious network could advertise the same prefix while still maintaining an AS path going to the Legit AS (and forwarding the traffic). This is more sneaky and complex than AS forgery, as the target network still receives traffic.
How to mitigate it?
- Peer with as many networks as possible (the shorter the AS path, the better)
More specific ROA
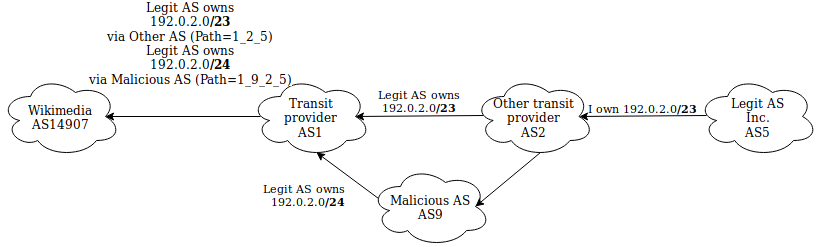
A variation of the previous point. If you allow your AS to advertize a more specific prefix, but don’t actually advertise it, a malicious AS doesn’t even need to have a shorter AS path to MitM-it.
How to mitigate it?
- Ensure the ROA strictly matches what you’re advertising in BGP
Some efforts (such as BGPsec) are being made to perform full path validation, but nothing is production ready yet.
TL;DR;
- Deploy more than one validator
- Keep them on the same trusted network as your routers (or use encryption)
- Monitor validators and routers
- Write documentation and train your staff
- Check if any traffic would be null-routed eg. pmacct
- Peer with many networks (short AS Paths)
- Discard Invalids starting with IXPs
- Share your experience
Where are we now?
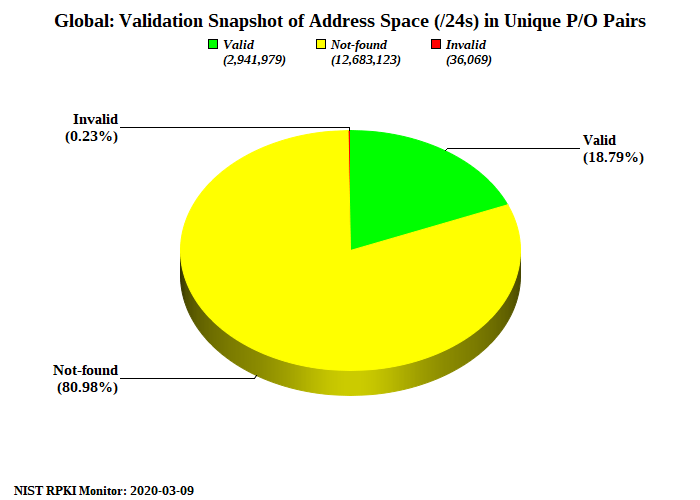
From NIST we see Invalids represent 0.23% of equivalent /24s. With RPKI unreachable being an even smaller subset.
As seen on the Internet
- AMS-IX route servers rejects by default prefixes with invalid origins.
- Telia rejects invalids
- AT&T rejects invalids
- Netnod rejects invalids
- SEACOM and Workonline reject invalids (but don’t use ARIN’s TAL)
- Google is planning to reject invalids for its peerings links
- NTT rejects invalids
- A more comprehensive list of networks rejecting invalids (methodology not detailed)
- And the now famous https://isbgpsafeyet.com/
Wikimedia
All the work done at the Foundation is public by default, RPKI is no exception. You can find the main tracking task on our Phabricator instance, all related code changes on Gerrit the doc obviously on a wiki, and graphs on Grafana.
Back in April, after looking at all the available validators, we decided to use Routinator for two main reasons: its RTR daemon is embedded into the validator (no need to maintain several tools) and its development was active with an explicit roadmap.
In parallel to the implementation side, we wrote a Prometheus exporter comparing our real time webrequests to a list of invalid prefixes, giving us the percentage of requests coming from unreachable prefixes. This was then exposed in real-time on our Grafana dashboard and used to hoover around 0.01%.
Last July, we started to reject invalids on IXP links, where our AS-paths are the shortest. In addition to having an open peering policy, this contributed to making more than half of our traffic “safer”.
On January 15th, we flipped the switch to discard invalid prefixes on transit links as well. One of our concerns is legit providers suddenly been unable to reach Wikipedia after a misconfiguration. Not our fault, but users would still be widely impacted.
On the other hand, our hope is that having such a popular website enforcing RPKI adds a considerable amount of trust in the system, accelerating the ongoing adoption of RPKI validation.
Aftermatch
As of the time of publishing this article, we have been contacted by 13 providers reporting Wikipedia being unreachable for them or one of their customers. Quickly fixed after explaining them what was the issue.
Edit: August 11, added mentions of FORT Validator and rpki-client.
Header: https://commons.wikimedia.org/wiki/File:DublinAirport31mar2007-03.jpg
{kind=link}
- Projects
- Subscribers
- Reedy, • Hostnetindi
- Tokens