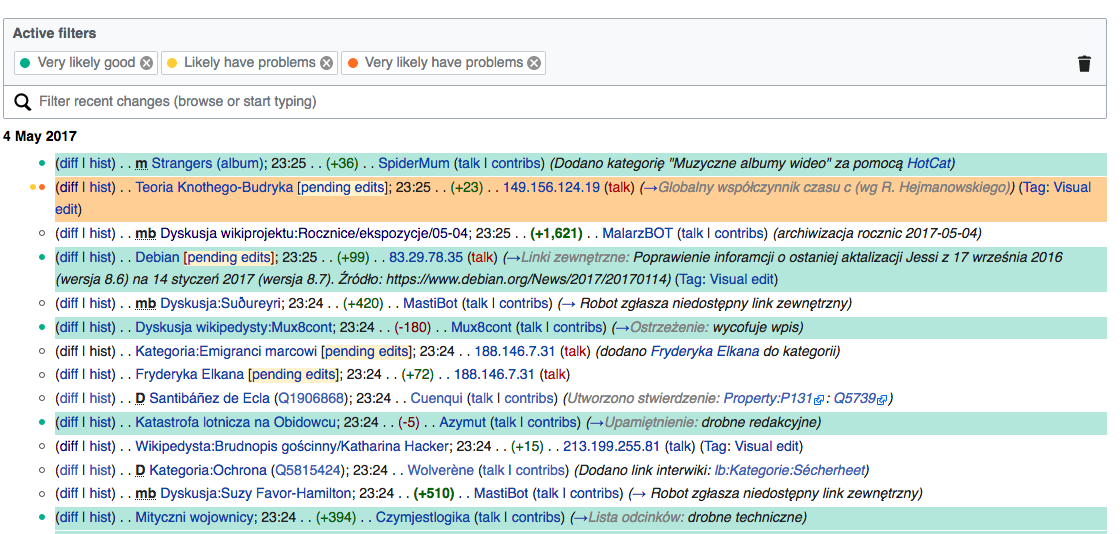
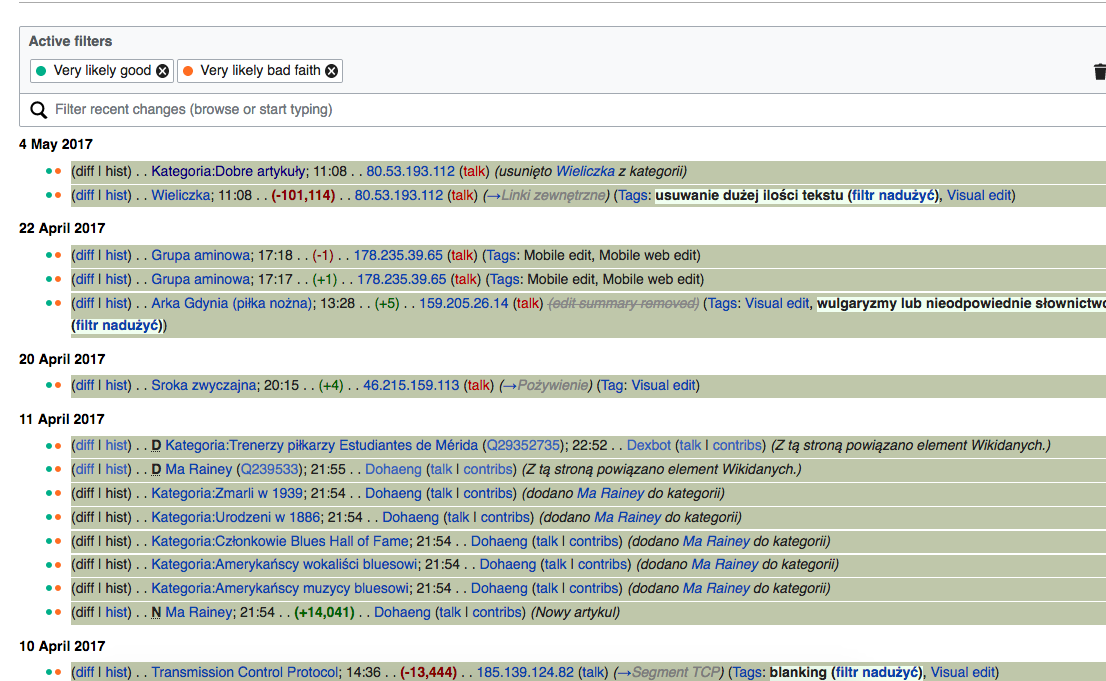
- On Polish Wikipedia, set the Quality filters as shown in the screenshots below
Expected Results: Green (Very likely good) should blend only with yellow (May be bad).
Actual results: Orange (Likely bad) frequently blends with Green (Very likely good).
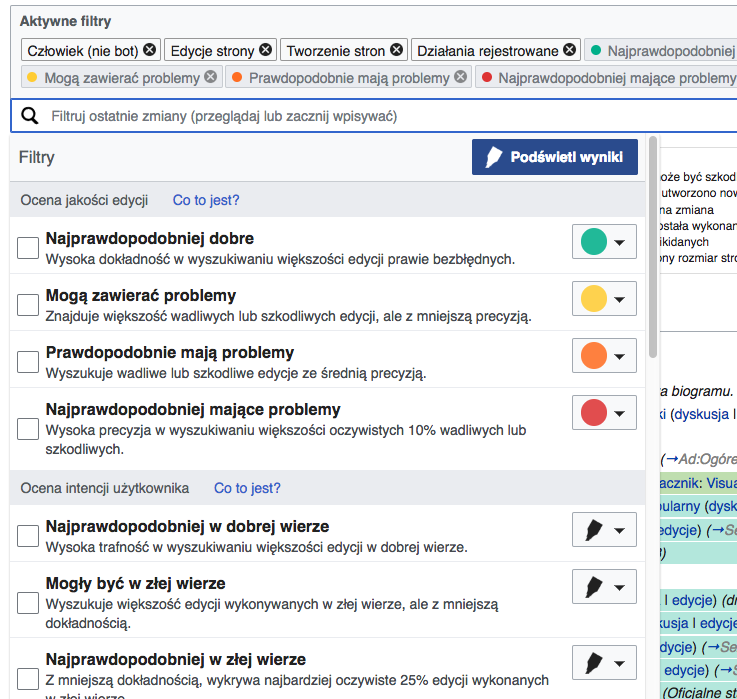

Roan looked up the thresholds in Polish and they are, in fact, much different from English Wikipedia:
- V. likely good: 0-86
- May be bad: 7-100
- Likely bad: 37-100
- V. likely bad: 73-100
The issue here is that the mathematical model doesn't match the user expectations we've set up in the interface. Beyond that, it's actually possible for an edit to be both V. likely good and V. likely bad. What is a user to make of such a classification?
Clearly our assumptions are based on our experience with en.wiki. Here are the problems/solutions that seem possible here:
- There's simply a problem with our math/code, and the thresholds are being set improperly (please let it be this!).
- The precision/recall targets we established based on en.wiki don't translate to other wikis, and we need adjust them on a per-wiki basis.
- The interface assumptions we made based on en.wiki don't translate, and we need to customize the interface on a per-wiki basis (e.g., because certain wikis simply won't support three levels of damage).
@Halfak, @SBisson @Catrope, please comment. I think we need to have a plan here soonest so we an understand what we're looking at before we roll this out to the next batch of wikis.