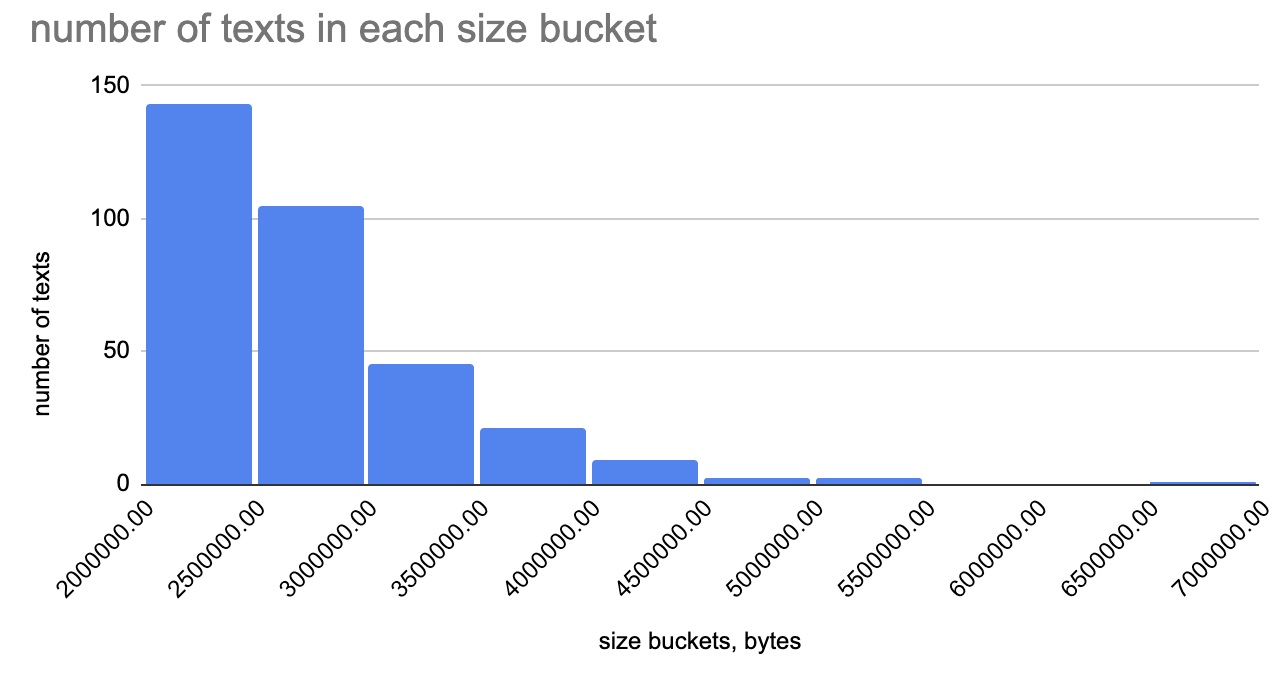
The Maximum article size (AKA post-expand include size) is set to 2048Kb. This limit is configured by the $wgMaxArticleSize variable. We ask to raise the limit to 4096Kb for the Hebrew Wikisource. We already hit the limit with two heavily accessed pages: Income Tax Ordinance and Planning and Building (Application for Permit, Conditions and Fees) Regulations, 5730–1970. Those pages are rendered incorrectly due to the limit. Other pages, such as Transportation Regulations, 5721–1961, are expected to hit to the limit in the near future.
Breaking the legal text into sections is not felt to be a valid solution. Also note that Hebrew characters are two-bytes per character, whereas Latin characters are one-byte per character. Therefore the limit for Hebrew text is half of the limit of a Latin text of the same length.